 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Online Sign Language Recognition and Translation
Paper and Code
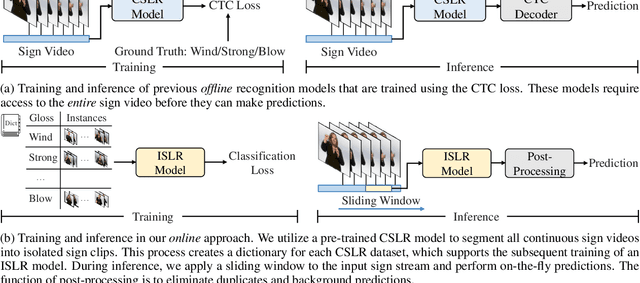
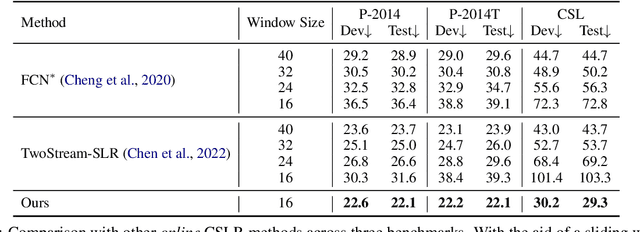
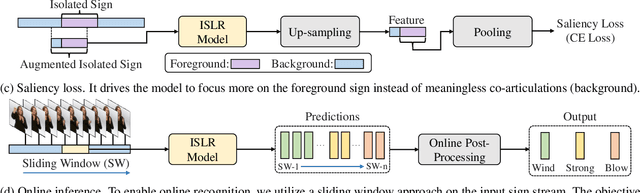
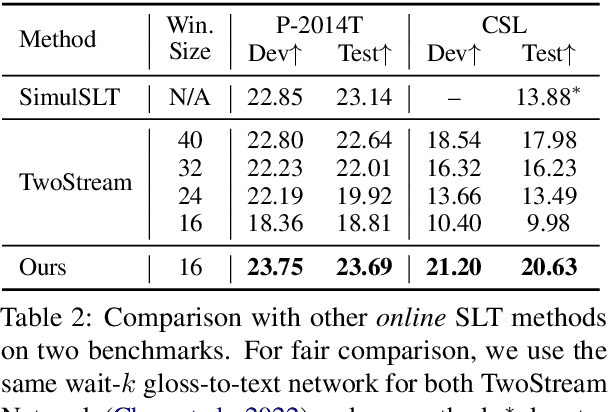
The objective of sign language recognition is to bridge the communication gap between the deaf and the hearing. Numerous previous works train their models using the well-established connectionist temporal classification (CTC) loss. During the inference stage, the CTC-based models typically take the entire sign video as input to make predictions. This type of inference scheme is referred to as offline recognition. In contrast, while mature speech recognition systems can efficiently recognize spoken words on the fly, sign language recognition still falls short due to the lack of practical online solutions. In this work, we take the first step towards filling this gap. Our approach comprises three phases: 1) developing a sign language dictionary encompassing all glosses present in a target sign language dataset; 2) training an isolated sign language recognition model on augmented signs using both conventional classification loss and our novel saliency loss; 3) employing a sliding window approach on the input sign sequence and feeding each sign clip to the well-optimized model for online recognition. Furthermore, our online recognition model can be extended to boost the performance of any offline model, and to support online translation by appending a gloss-to-text network onto the recognition model. By integrating our online framework with the previously best-performing offline model, TwoStream-SLR, we achieve new state-of-the-art performance on three benchmarks: Phoenix-2014, Phoenix-2014T, and CSL-Daily. Code and models will be available at https://github.com/FangyunWei/SLRT