 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hong Kong Sign Language Corpus Collected from Sign-interpreted TV News
May 02, 2024



This paper introduces TVB-HKSL-News, a new Hong Kong sign language (HKSL) dataset collected from a TV news program over a period of 7 months. The dataset is collected to enrich resources for HKSL and support research in large-vocabulary continuous sign language recognition (SLR) and translation (SLT). It consists of 16.07 hours of sign videos of two signers with a vocabulary of 6,515 glosses (for SLR) and 2,850 Chinese characters or 18K Chinese words (for SLT). One signer has 11.66 hours of sign videos and the other has 4.41 hours. One objective in building the dataset is to support the investigation of how well large-vocabulary continuous sign language recognition/translation can be done for a single signer given a (relatively) large amount of his/her training data, which could potentially lead to the development of new modeling methods. Besides, most parts of the data collection pipeline are automated with little human intervention; we believe that our collection method can be scaled up to collect more sign language data easily for SLT in the future for any sign languages if such sign-interpreted videos are available. We also run a SOTA SLR/SLT model on the dataset and get a baseline SLR word error rate of 34.08% and a baseline SLT BLEU-4 score of 23.58 for benchmarking future research on the dataset.
On the Audio-visual Synchronization for Lip-to-Speech Synthesis
Mar 01, 2023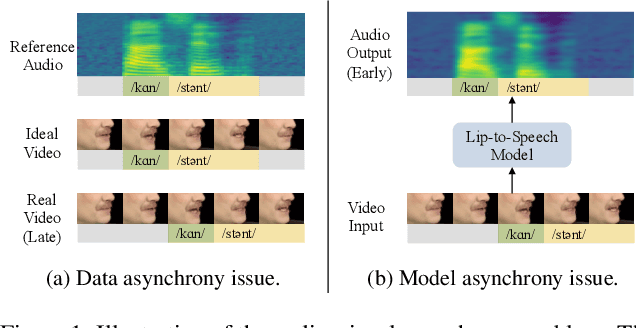

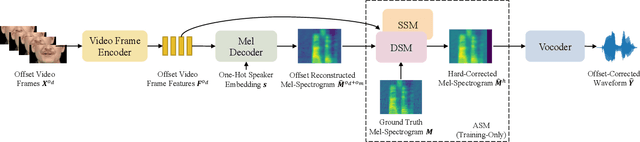

Most lip-to-speech (LTS) synthesis models are trained and evaluated under the assumption that the audio-video pairs in the dataset are perfectly synchronized. In this work, we show that the commonly used audio-visual datasets, such as GRID, TCD-TIMIT, and Lip2Wav, can have data asynchrony issues. Training lip-to-speech with such datasets may further cause the model asynchrony issue -- that is, the generated speech and the input video are out of sync. To address these asynchrony issues, we propose a synchronized lip-to-speech (SLTS) model with an automatic synchronization mechanism (ASM) to correct data asynchrony and penalize model asynchrony. We further demonstrate the limitation of the commonly adopted evaluation metrics for LTS with asynchronous test data and introduce an audio alignment frontend before the metrics sensitive to time alignment for better evaluation. We compare our method with state-of-the-art approaches on conventional and time-aligned metrics to show the benefits of synchronization training.