 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaDiS: Taming Masked Diffusion Language Models for Sign Language Generation
Jan 27, 2026Sign language generation (SLG) aims to translate written texts into expressive sign motions, bridging communication barriers for the Deaf and Hard-of-Hearing communities. Recent studies formulate SLG within the language modeling framework using autoregressive language models, which suffer from unidirectional context modeling and slow token-by-token inference. To address these limitations, we present MaDiS, a masked-diffusion-based language model for SLG that captures bidirectional dependencies and supports efficient parallel multi-token generation. We further introduce a tri-level cross-modal pretraining scheme that jointly learns from token-, latent-, and 3D physical-space objectives, leading to richer and more grounded sign representations. To accelerate model convergence in the fine-tuning stage, we design a novel unmasking strategy with temporal checkpoints, reducing the combinatorial complexity of unmasking orders by over $10^{41}$ times. In addition, a mixture-of-parts embedding layer is developed to effectively fuse information stored in different part-wise sign tokens through learnable gates and well-optimized codebooks. Extensive experiments on CSL-Daily, Phoenix-2014T, and How2Sign demonstrate that MaDiS achieves superior performance across multiple metrics, including DTW error and two newly introduced metrics, SiBLEU and SiCLIP, while reducing inference latency by nearly 30%. Code and models will be released on our project page.
Signs as Tokens: An Autoregressive Multilingual Sign Language Generator
Nov 26, 2024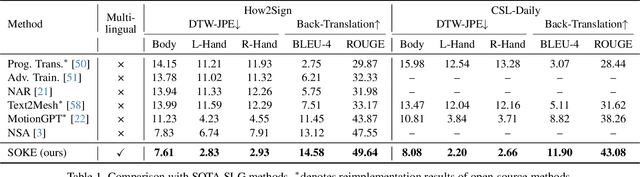
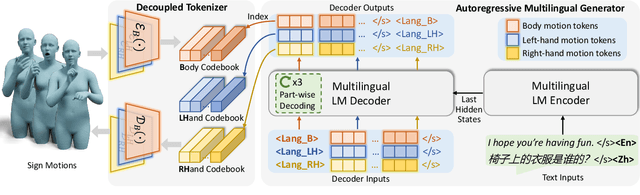
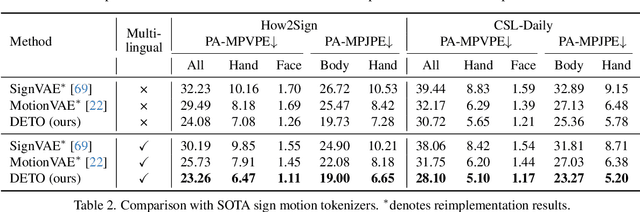

Sign language is a visual language that encompasses all linguistic features of natural languages and serves as the primary communication method for the deaf and hard-of-hearing communities. While many studies have successfully adapted pretrained language models (LMs) for sign language translation (sign-to-text), drawing inspiration from its linguistic characteristics, the reverse task of sign language generation (SLG, text-to-sign) remains largely unexplored. Most existing approaches treat SLG as a visual content generation task, employing techniques such as diffusion models to produce sign videos, 2D keypoints, or 3D avatars based on text inputs, overlooking the linguistic properties of sign languages. In this work, we introduce a multilingual sign language model, Signs as Tokens (SOKE), which can generate 3D sign avatars autoregressively from text inputs using a pretrained LM. To align sign language with the LM, we develop a decoupled tokenizer that discretizes continuous signs into token sequences representing various body parts. These sign tokens are integrated into the raw text vocabulary of the LM, allowing for supervised fine-tuning on sign language datasets. To facilitate multilingual SLG research, we further curate a large-scale Chinese sign language dataset, CSL-Daily, with high-quality 3D pose annotations. Extensive qualitative and quantitative evaluations demonstrate the effectiveness of SOKE. The project page is available at https://2000zrl.github.io/soke/.
ZeroGS: Training 3D Gaussian Splatting from Unposed Images
Nov 24, 2024

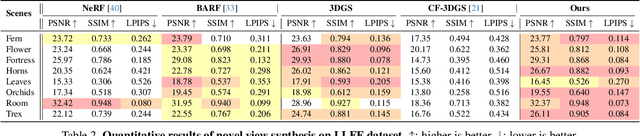

Neural radiance fields (NeRF) and 3D Gaussian Splatting (3DGS) are popular techniques to reconstruct and render photo-realistic images. However, the pre-requisite of running Structure-from-Motion (SfM) to get camera poses limits their completeness. While previous methods can reconstruct from a few unposed images, they are not applicable when images are unordered or densely captured. In this work, we propose ZeroGS to train 3DGS from hundreds of unposed and unordered images. Our method leverages a pretrained foundation model as the neural scene representation. Since the accuracy of the predicted pointmaps does not suffice for accurate image registration and high-fidelity image rendering, we propose to mitigate the issue by initializing and finetuning the pretrained model from a seed image. Images are then progressively registered and added to the training buffer, which is further used to train the model. We also propose to refine the camera poses and pointmaps by minimizing a point-to-camera ray consistency loss across multiple views. Experiments on the LLFF dataset, the MipNeRF360 dataset, and the Tanks-and-Temples dataset show that our method recovers more accurate camera poses than state-of-the-art pose-free NeRF/3DGS methods, and even renders higher quality images than 3DGS with COLMAP poses. Our project page is available at https://aibluefisher.github.io/ZeroGS.
SAGS: Structure-Aware 3D Gaussian Splatting
Apr 29, 2024



Following the advent of NeRFs, 3D Gaussian Splatting (3D-GS) has paved the way to real-time neural rendering overcoming the computational burden of volumetric methods. Following the pioneering work of 3D-GS, several methods have attempted to achieve compressible and high-fidelity performance alternatives. However, by employing a geometry-agnostic optimization scheme, these methods neglect the inherent 3D structure of the scene, thereby restricting the expressivity and the quality of the representation, resulting in various floating points and artifacts. In this work, we propose a structure-aware Gaussian Splatting method (SAGS) that implicitly encodes the geometry of the scene, which reflects to state-of-the-art rendering performance and reduced storage requirements on benchmark novel-view synthesis datasets. SAGS is founded on a local-global graph representation that facilitates the learning of complex scenes and enforces meaningful point displacements that preserve the scene's geometry. Additionally, we introduce a lightweight version of SAGS, using a simple yet effective mid-point interpolation scheme, which showcases a compact representation of the scene with up to 24$\times$ size reduction without the reliance on any compression strategies. Extensive experiments across multiple benchmark datasets demonstrate the superiority of SAGS compared to state-of-the-art 3D-GS methods under both rendering quality and model size. Besides, we demonstrate that our structure-aware method can effectively mitigate floating artifacts and irregular distortions of previous methods while obtaining precise depth maps. Project page https://eververas.github.io/SAGS/.
Neural Sign Actors: A diffusion model for 3D sign language production from text
Dec 05, 2023Sign Languages (SL) serve as the predominant mode of communication for the Deaf and Hard of Hearing communities. The advent of deep learning has aided numerous methods in SL recognition and translation, achieving remarkable results. However, Sign Language Production (SLP) poses a challenge for the computer vision community as the motions generated must be realistic and have precise semantic meanings. Most SLP methods rely on 2D data, thus impeding their ability to attain a necessary level of realism. In this work, we propose a diffusion-based SLP model trained on a curated large-scale dataset of 4D signing avatars and their corresponding text transcripts. The proposed method can generate dynamic sequences of 3D avatars from an unconstrained domain of discourse using a diffusion process formed on a novel and anatomically informed graph neural network defined on the SMPL-X body skeleton. Through a series of quantitative and qualitative experiments, we show that the proposed method considerably outperforms previous methods of SLP. We believe that this work presents an important and necessary step towards realistic neural sign avatars, bridging the communication gap between Deaf and hearing communities. The code, method and generated data will be made publicly available.
Weakly-Supervised Gaze Estimation from Synthetic Views
Dec 06, 20223D gaze estimation is most often tackled as learning a direct mapping between input images and the gaze vector or its spherical coordinates. Recently, it has been shown that pose estimation of the face, body and hands benefits from revising the learning target from few pose parameters to dense 3D coordinates. In this work, we leverage this observation and propose to tackle 3D gaze estimation as regression of 3D eye meshes. We overcome the absence of compatible ground truth by fitting a rigid 3D eyeball template on existing gaze datasets and propose to improve generalization by making use of widely available in-the-wild face images. To this end, we propose an automatic pipeline to retrieve robust gaze pseudo-labels from arbitrary face images and design a multi-view supervision framework to balance their effect during training. In our experiments, our method achieves improvement of 30% compared to state-of-the-art in cross-dataset gaze estimation, when no ground truth data are available for training, and 7% when they are. We make our project publicly available at https://github.com/Vagver/dense3Deyes.
Free-HeadGAN: Neural Talking Head Synthesis with Explicit Gaze Control
Aug 03, 2022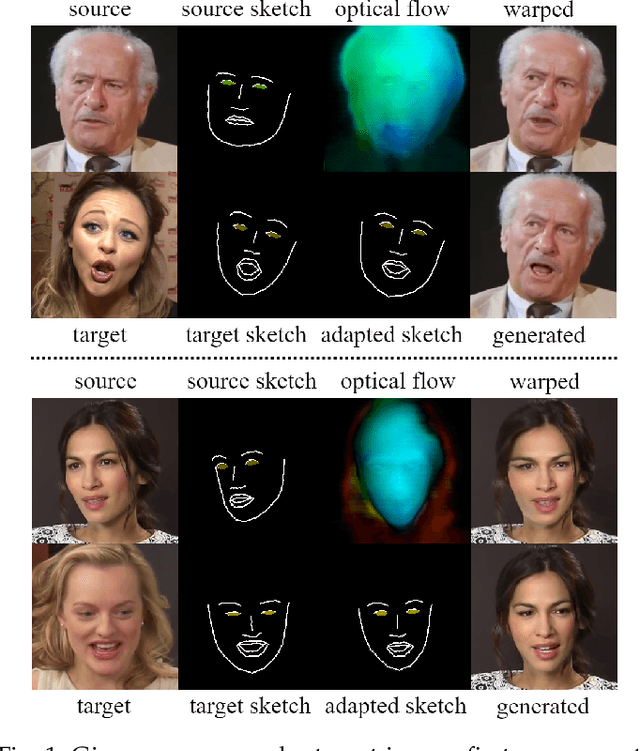
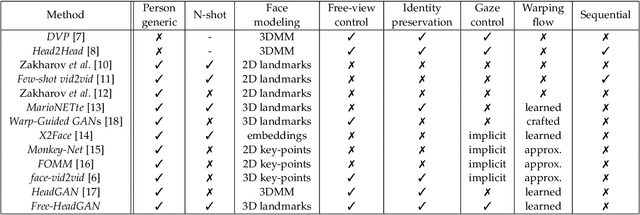
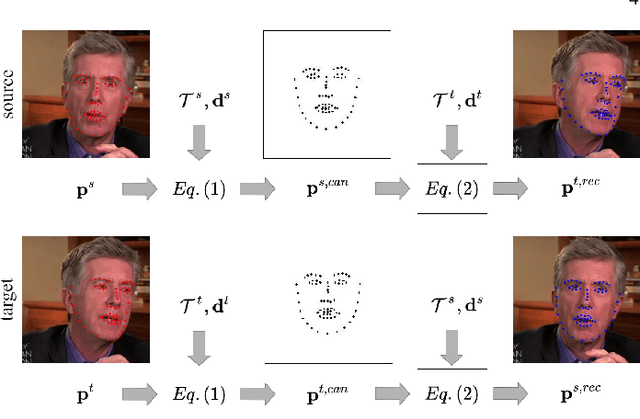
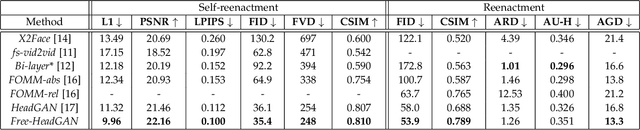
We present Free-HeadGAN, a person-generic neural talking head synthesis system. We show that modeling faces with sparse 3D facial landmarks are sufficient for achieving state-of-the-art generative performance, without relying on strong statistical priors of the face, such as 3D Morphable Models. Apart from 3D pose and facial expressions, our method is capable of fully transferring the eye gaze, from a driving actor to a source identity. Our complete pipeline consists of three components: a canonical 3D key-point estimator that regresses 3D pose and expression-related deformations, a gaze estimation network and a generator that is built upon the architecture of HeadGAN. We further experiment with an extension of our generator to accommodate few-shot learning using an attention mechanism, in case more than one source images are available. Compared to the latest models for reenactment and motion transfer, our system achieves higher photo-realism combined with superior identity preservation, while offering explicit gaze control.
Learning to Generate Customized Dynamic 3D Facial Expressions
Jul 21, 2020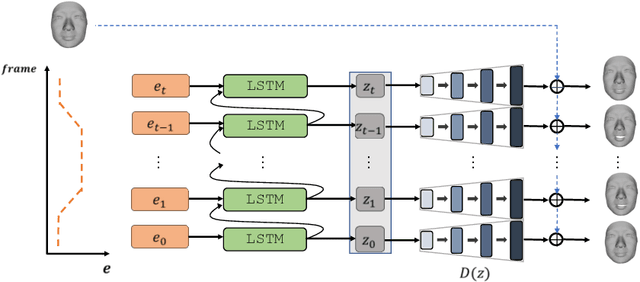
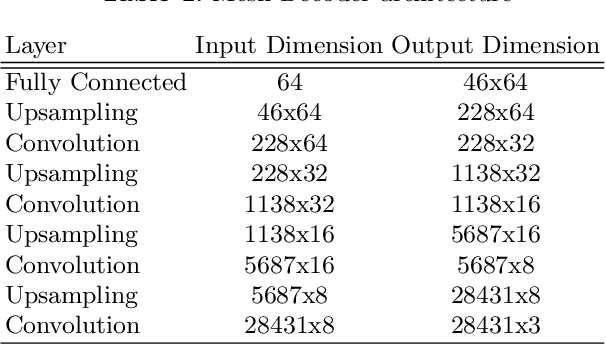
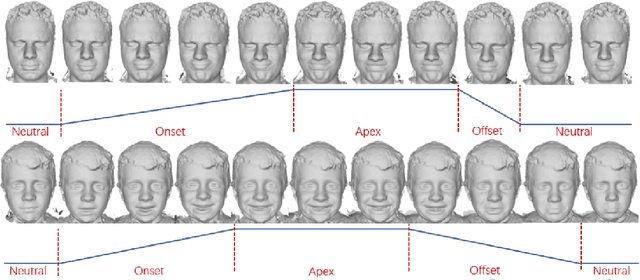

Recent advances in deep learning have significantly pushed the state-of-the-art in photorealistic video animation given a single image. In this paper, we extrapolate those advances to the 3D domain, by studying 3D image-to-video translation with a particular focus on 4D facial expressions. Although 3D facial generative models have been widely explored during the past years, 4D animation remains relatively unexplored. To this end, in this study we employ a deep mesh encoder-decoder like architecture to synthesize realistic high resolution facial expressions by using a single neutral frame along with an expression identification. In addition, processing 3D meshes remains a non-trivial task compared to data that live on grid-like structures, such as images. Given the recent progress in mesh processing with graph convolutions, we make use of a recently introduced learnable operator which acts directly on the mesh structure by taking advantage of local vertex orderings. In order to generalize to 4D facial expressions across subjects, we trained our model using a high resolution dataset with 4D scans of six facial expressions from 180 subjects. Experimental results demonstrate that our approach preserves the subject's identity information even for unseen subjects and generates high quality expressions. To the best of our knowledge, this is the first study tackling the problem of 4D facial expression synthesis.
Towards a complete 3D morphable model of the human head
Nov 18, 2019
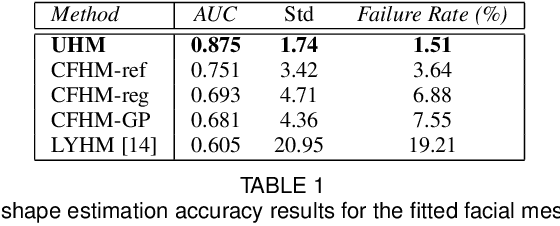
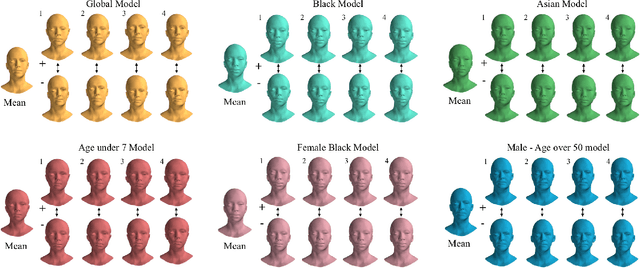
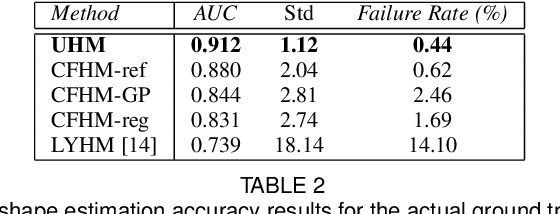
Three-dimensional Morphable Models (3DMMs) are powerful statistical tools for representing the 3D shapes and textures of an object class. Here we present the most complete 3DMM of the human head to date that includes face, cranium, ears, eyes, teeth and tongue. To achieve this, we propose two methods for combining existing 3DMMs of different overlapping head parts: i. use a regressor to complete missing parts of one model using the other, ii. use the Gaussian Process framework to blend covariance matrices from multiple models. Thus we build a new combined face-and-head shape model that blends the variability and facial detail of an existing face model (the LSFM) with the full head modelling capability of an existing head model (the LYHM). Then we construct and fuse a highly-detailed ear model to extend the variation of the ear shape. Eye and eye region models are incorporated into the head model, along with basic models of the teeth, tongue and inner mouth cavity. The new model achieves state-of-the-art performance. We use our model to reconstruct full head representations from single, unconstrained images allowing us to parameterize craniofacial shape and texture, along with the ear shape, eye gaze and eye color.
SliderGAN: Synthesizing Expressive Face Images by Sliding 3D Blendshape Parameters
Aug 26, 2019
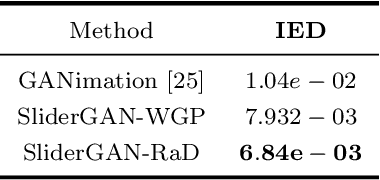


Image-to-image (i2i) translation is the dense regression problem of learning how to transform an input image into an output using aligned image pairs. Remarkable progress has been made in i2i translation with the advent of Deep Convolutional Neural Networks (DCNNs) and particular using the learning paradigm of Generative Adversarial Networks (GANs). In the absence of paired images, i2i translation is tackled with one or multiple domain transformations (i.e., CycleGAN, StarGAN etc.). In this paper, we study a new problem, that of image-to-image translation, under a set of continuous parameters that correspond to a model describing a physical process. In particular, we propose the SliderGAN which transforms an input face image into a new one according to the continuous values of a statistical blendshape model of facial motion. We show that it is possible to edit a facial image according to expression and speech blendshapes, using sliders that control the continuous values of the blendshape model. This provides much more flexibility in various tasks, including but not limited to face editing, expression transfer and face neutralisation, comparing to models based on discrete expressions or action units.