 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVENI: Variational Encoder for Natural Illumination
Jan 20, 2026Inverse rendering is an ill-posed problem, but priors like illumination priors, can simplify it. Existing work either disregards the spherical and rotation-equivariant nature of illumination environments or does not provide a well-behaved latent space. We propose a rotation-equivariant variational autoencoder that models natural illumination on the sphere without relying on 2D projections. To preserve the SO(2)-equivariance of environment maps, we use a novel Vector Neuron Vision Transformer (VN-ViT) as encoder and a rotation-equivariant conditional neural field as decoder. In the encoder, we reduce the equivariance from SO(3) to SO(2) using a novel SO(2)-equivariant fully connected layer, an extension of Vector Neurons. We show that our SO(2)-equivariant fully connected layer outperforms standard Vector Neurons when used in our SO(2)-equivariant model. Compared to previous methods, our variational autoencoder enables smoother interpolation in latent space and offers a more well-behaved latent space.
Metrics that matter: Evaluating image quality metrics for medical image generation
May 12, 2025Evaluating generative models for synthetic medical imaging is crucial yet challenging, especially given the high standards of fidelity, anatomical accuracy, and safety required for clinical applications. Standard evaluation of generated images often relies on no-reference image quality metrics when ground truth images are unavailable, but their reliability in this complex domain is not well established. This study comprehensively assesses commonly used no-reference image quality metrics using brain MRI data, including tumour and vascular images, providing a representative exemplar for the field. We systematically evaluate metric sensitivity to a range of challenges, including noise, distribution shifts, and, critically, localised morphological alterations designed to mimic clinically relevant inaccuracies. We then compare these metric scores against model performance on a relevant downstream segmentation task, analysing results across both controlled image perturbations and outputs from different generative model architectures. Our findings reveal significant limitations: many widely-used no-reference image quality metrics correlate poorly with downstream task suitability and exhibit a profound insensitivity to localised anatomical details crucial for clinical validity. Furthermore, these metrics can yield misleading scores regarding distribution shifts, e.g. data memorisation. This reveals the risk of misjudging model readiness, potentially leading to the deployment of flawed tools that could compromise patient safety. We conclude that ensuring generative models are truly fit for clinical purpose requires a multifaceted validation framework, integrating performance on relevant downstream tasks with the cautious interpretation of carefully selected no-reference image quality metrics.
NeuRaLaTeX: A machine learning library written in pure LaTeX
Mar 31, 2025In this paper, we introduce NeuRaLaTeX, which we believe to be the first deep learning library written entirely in LaTeX. As part of your LaTeX document you can specify the architecture of a neural network and its loss functions, define how to generate or load training data, and specify training hyperparameters and experiments. When the document is compiled, the LaTeX compiler will generate or load training data, train the network, run experiments, and generate figures. This paper generates a random 100 point spiral dataset, trains a two layer MLP on it, evaluates on a different random spiral dataset, produces plots and tables of results. The paper took 48 hours to compile and the entire source code for NeuRaLaTeX is contained within the source code of the paper. We propose two new metrics: the Written In Latex (WIL) metric measures the proportion of a machine learning library that is written in pure LaTeX, while the Source Code Of Method in Source Code of Paper (SCOMISCOP) metric measures the proportion of a paper's implementation that is contained within the paper source. We are state-of-the-art for both metrics, outperforming the ResNet and Transformer papers, as well as the PyTorch and Tensorflow libraries. Source code, documentation, videos, crypto scams and an invitation to invest in the commercialisation of NeuRaLaTeX are available at https://www.neuralatex.com
Track Anything Behind Everything: Zero-Shot Amodal Video Object Segmentation
Nov 28, 2024



We present Track Anything Behind Everything (TABE), a novel dataset, pipeline, and evaluation framework for zero-shot amodal completion from visible masks. Unlike existing methods that require pretrained class labels, our approach uses a single query mask from the first frame where the object is visible, enabling flexible, zero-shot inference. Our dataset, TABE-51 provides highly accurate ground truth amodal segmentation masks without the need for human estimation or 3D reconstruction. Our TABE pipeline is specifically designed to handle amodal completion, even in scenarios where objects are completely occluded. We also introduce a specialised evaluation framework that isolates amodal completion performance, free from the influence of traditional visual segmentation metrics.
The Sky's the Limit: Re-lightable Outdoor Scenes via a Sky-pixel Constrained Illumination Prior and Outside-In Visibility
Nov 28, 2023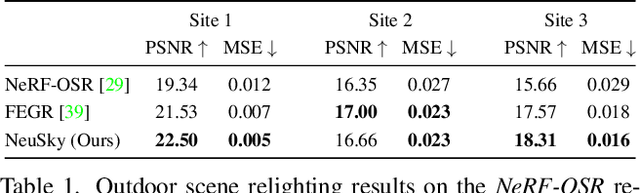
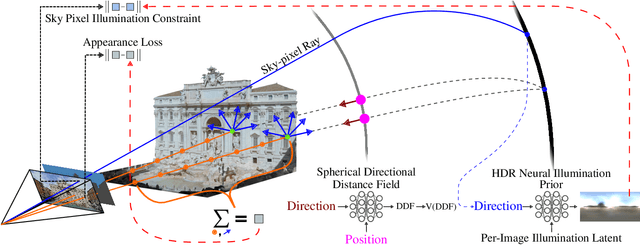
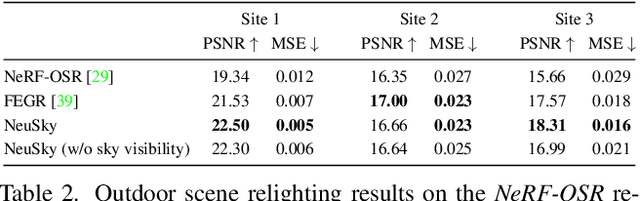
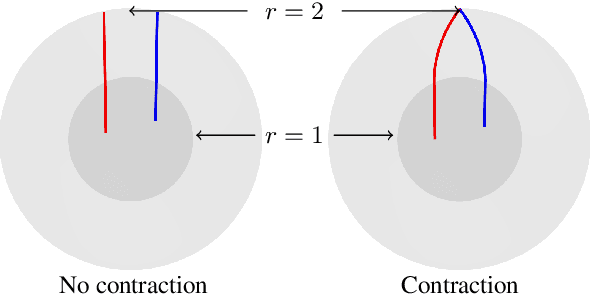
Inverse rendering of outdoor scenes from unconstrained image collections is a challenging task, particularly illumination/albedo ambiguities and occlusion of the illumination environment (shadowing) caused by geometry. However, there are many cues in an image that can aid in the disentanglement of geometry, albedo and shadows. We exploit the fact that any sky pixel provides a direct measurement of distant lighting in the corresponding direction and, via a neural illumination prior, a statistical cue as to the remaining illumination environment. We also introduce a novel `outside-in' method for computing differentiable sky visibility based on a neural directional distance function. This is efficient and can be trained in parallel with the neural scene representation, allowing gradients from appearance loss to flow from shadows to influence estimation of illumination and geometry. Our method estimates high-quality albedo, geometry, illumination and sky visibility, achieving state-of-the-art results on the NeRF-OSR relighting benchmark. Our code and models can be found https://github.com/JADGardner/neusky
RENI++ A Rotation-Equivariant, Scale-Invariant, Natural Illumination Prior
Nov 15, 2023Inverse rendering is an ill-posed problem. Previous work has sought to resolve this by focussing on priors for object or scene shape or appearance. In this work, we instead focus on a prior for natural illuminations. Current methods rely on spherical harmonic lighting or other generic representations and, at best, a simplistic prior on the parameters. This results in limitations for the inverse setting in terms of the expressivity of the illumination conditions, especially when taking specular reflections into account. We propose a conditional neural field representation based on a variational auto-decoder and a transformer decoder. We extend Vector Neurons to build equivariance directly into our architecture, and leveraging insights from depth estimation through a scale-invariant loss function, we enable the accurate representation of High Dynamic Range (HDR) images. The result is a compact, rotation-equivariant HDR neural illumination model capable of capturing complex, high-frequency features in natural environment maps. Training our model on a curated dataset of 1.6K HDR environment maps of natural scenes, we compare it against traditional representations, demonstrate its applicability for an inverse rendering task and show environment map completion from partial observations. We share our PyTorch implementation, dataset and trained models at https://github.com/JADGardner/ns_reni
ID2image: Leakage of non-ID information into face descriptors and inversion from descriptors to images
Apr 15, 2023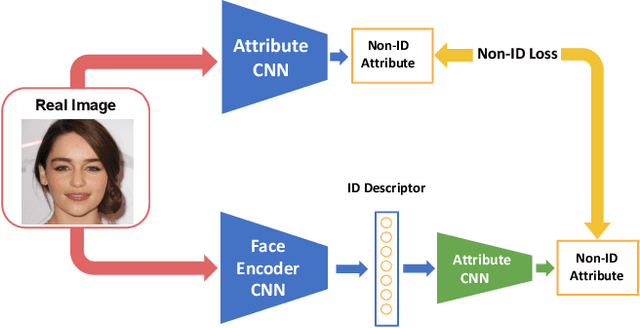



Embedding a face image to a descriptor vector using a deep CNN is a widely used technique in face recognition. Via several possible training strategies, such embeddings are supposed to capture only identity information. Information about the environment (such as background and lighting) or changeable aspects of the face (such as pose, expression, presence of glasses, hat etc.) should be discarded since they are not useful for recognition. In this paper, we present a surprising result that this is not the case. We show that non-ID attributes, as well as landmark positions and the image histogram can be recovered from the ID embedding of state-of-the-art face embedding networks (VGGFace2 and ArcFace). In fact, these non-ID attributes can be predicted from ID embeddings with similar accuracy to a prediction from the original image. Going further, we present an optimisation strategy that uses a generative model (specifically StyleGAN2 for faces) to recover images from an ID embedding. We show photorealistic inversion from ID embedding to face image in which not only is the ID realistically reconstructed but the pose, lighting and background/apparel to some extent as well.
If At First You Don't Succeed: Test Time Re-ranking for Zero-shot, Cross-domain Retrieval
Mar 30, 2023



In this paper we propose a novel method for zero-shot, cross-domain image retrieval in which we make two key contributions. The first is a test-time re-ranking procedure that enables query-gallery pairs, without meaningful shared visual features, to be matched by incorporating gallery-gallery ranks into an iterative re-ranking process. The second is the use of cross-attention at training time and knowledge distillation to encourage cross-attention-like features to be extracted at test time from a single image. When combined with the Vision Transformer architecture and zero-shot retrieval losses, our approach yields state-of-the-art results on the Sketchy and TU-Berlin sketch-based image retrieval benchmarks. However, unlike many previous methods, none of the components in our approach are engineered specifically towards the sketch-based image retrieval task - it can be generally applied to any cross-domain, zero-shot retrieval task. We therefore also show results on zero-shot cartoon-to-photo retrieval using the Office-Home dataset.
Neural apparent BRDF fields for multiview photometric stereo
Jul 14, 2022



We propose to tackle the multiview photometric stereo problem using an extension of Neural Radiance Fields (NeRFs), conditioned on light source direction. The geometric part of our neural representation predicts surface normal direction, allowing us to reason about local surface reflectance. The appearance part of our neural representation is decomposed into a neural bidirectional reflectance function (BRDF), learnt as part of the fitting process, and a shadow prediction network (conditioned on light source direction) allowing us to model the apparent BRDF. This balance of learnt components with inductive biases based on physical image formation models allows us to extrapolate far from the light source and viewer directions observed during training. We demonstrate our approach on a multiview photometric stereo benchmark and show that competitive performance can be obtained with the neural density representation of a NeRF.
Rotation-Equivariant Conditional Spherical Neural Fields for Learning a Natural Illumination Prior
Jun 10, 2022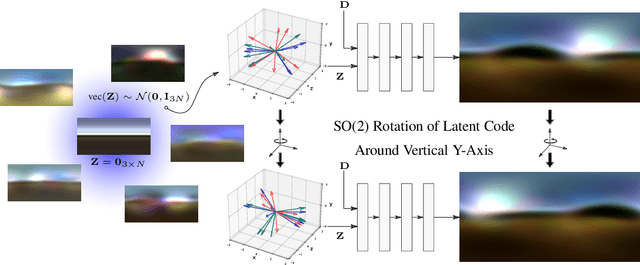
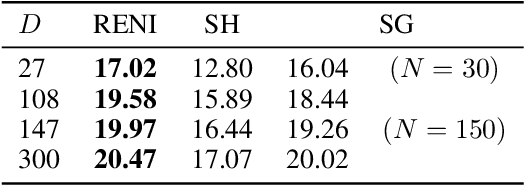


Inverse rendering is an ill-posed problem. Previous work has sought to resolve this by focussing on priors for object or scene shape or appearance. In this work, we instead focus on a prior for natural illuminations. Current methods rely on spherical harmonic lighting or other generic representations and, at best, a simplistic prior on the parameters. We propose a conditional neural field representation based on a variational auto-decoder with a SIREN network and, extending Vector Neurons, build equivariance directly into the network. Using this we develop a rotation-equivariant, high dynamic range (HDR) neural illumination model that is compact and able to express complex, high-frequency features of natural environment maps. Training our model on a curated dataset of 1.6K HDR environment maps of natural scenes, we compare it against traditional representations, demonstrate its applicability for an inverse rendering task and show environment map completion from partial observations. A PyTorch implementation, our dataset and trained models can be found at jadgardner.github.io/RENI.