 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFake It Without Making It: Conditioned Face Generation for Accurate 3D Face Shape Estimation
Jul 25, 2023
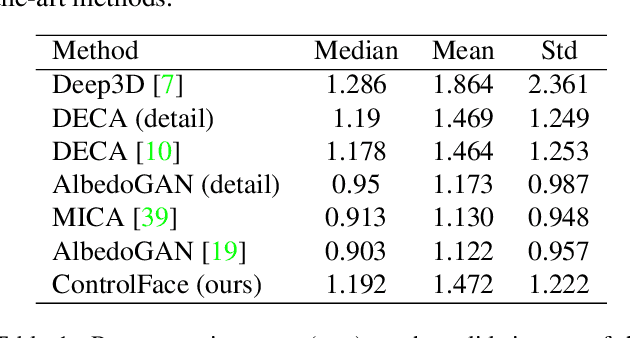
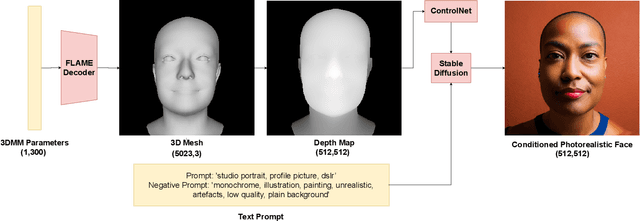

Accurate 3D face shape estimation is an enabling technology with applications in healthcare, security, and creative industries, yet current state-of-the-art methods either rely on self-supervised training with 2D image data or supervised training with very limited 3D data. To bridge this gap, we present a novel approach which uses a conditioned stable diffusion model for face image generation, leveraging the abundance of 2D facial information to inform 3D space. By conditioning stable diffusion on depth maps sampled from a 3D Morphable Model (3DMM) of the human face, we generate diverse and shape-consistent images, forming the basis of SynthFace. We introduce this large-scale synthesised dataset of 250K photorealistic images and corresponding 3DMM parameters. We further propose ControlFace, a deep neural network, trained on SynthFace, which achieves competitive performance on the NoW benchmark, without requiring 3D supervision or manual 3D asset creation.
ID2image: Leakage of non-ID information into face descriptors and inversion from descriptors to images
Apr 15, 2023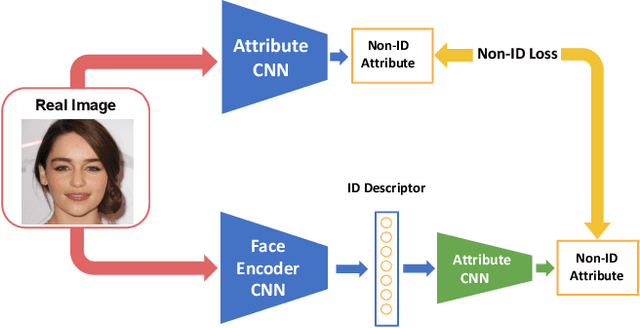



Embedding a face image to a descriptor vector using a deep CNN is a widely used technique in face recognition. Via several possible training strategies, such embeddings are supposed to capture only identity information. Information about the environment (such as background and lighting) or changeable aspects of the face (such as pose, expression, presence of glasses, hat etc.) should be discarded since they are not useful for recognition. In this paper, we present a surprising result that this is not the case. We show that non-ID attributes, as well as landmark positions and the image histogram can be recovered from the ID embedding of state-of-the-art face embedding networks (VGGFace2 and ArcFace). In fact, these non-ID attributes can be predicted from ID embeddings with similar accuracy to a prediction from the original image. Going further, we present an optimisation strategy that uses a generative model (specifically StyleGAN2 for faces) to recover images from an ID embedding. We show photorealistic inversion from ID embedding to face image in which not only is the ID realistically reconstructed but the pose, lighting and background/apparel to some extent as well.
Text2Face: A Multi-Modal 3D Face Model
Mar 08, 2023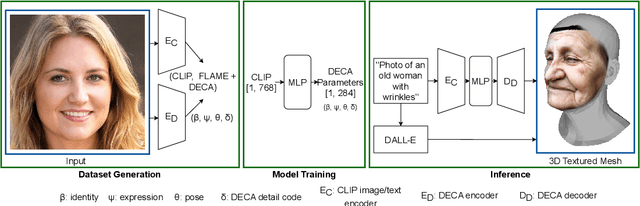



We present the first 3D morphable modelling approach, whereby 3D face shape can be directly and completely defined using a textual prompt. Building on work in multi-modal learning, we extend the FLAME head model to a common image-and-text latent space. This allows for direct 3D Morphable Model (3DMM) parameter generation and therefore shape manipulation from textual descriptions. Our method, Text2Face, has many applications; for example: generating police photofits where the input is already in natural language. It further enables multi-modal 3DMM image fitting to sketches and sculptures, as well as images.
Neural Implicit Surface Reconstruction from Noisy Camera Observations
Oct 02, 2022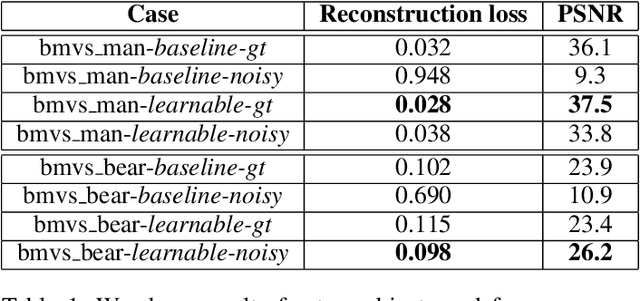


Representing 3D objects and scenes with neural radiance fields has become very popular over the last years. Recently, surface-based representations have been proposed, that allow to reconstruct 3D objects from simple photographs. However, most current techniques require an accurate camera calibration, i.e. camera parameters corresponding to each image, which is often a difficult task to do in real-life situations. To this end, we propose a method for learning 3D surfaces from noisy camera parameters. We show that we can learn camera parameters together with learning the surface representation, and demonstrate good quality 3D surface reconstruction even with noisy camera observations.
Neural apparent BRDF fields for multiview photometric stereo
Jul 14, 2022



We propose to tackle the multiview photometric stereo problem using an extension of Neural Radiance Fields (NeRFs), conditioned on light source direction. The geometric part of our neural representation predicts surface normal direction, allowing us to reason about local surface reflectance. The appearance part of our neural representation is decomposed into a neural bidirectional reflectance function (BRDF), learnt as part of the fitting process, and a shadow prediction network (conditioned on light source direction) allowing us to model the apparent BRDF. This balance of learnt components with inductive biases based on physical image formation models allows us to extrapolate far from the light source and viewer directions observed during training. We demonstrate our approach on a multiview photometric stereo benchmark and show that competitive performance can be obtained with the neural density representation of a NeRF.
Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
Oct 23, 2018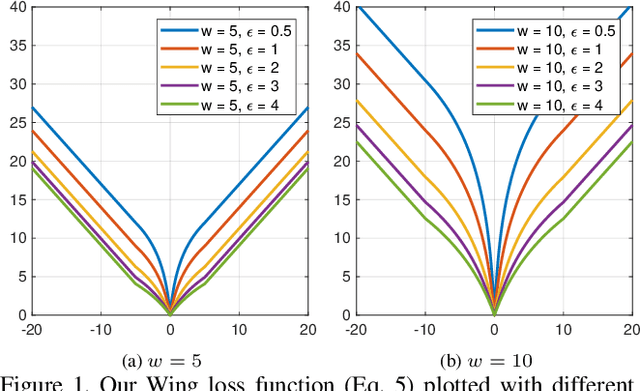


We present a new loss function, namely Wing loss, for robust facial landmark localisation with Convolutional Neural Networks (CNNs). We first compare and analyse different loss functions including L2, L1 and smooth L1. The analysis of these loss functions suggests that, for the training of a CNN-based localisation model, more attention should be paid to small and medium range errors. To this end, we design a piece-wise loss function. The new loss amplifies the impact of errors from the interval (-w, w) by switching from L1 loss to a modified logarithm function. To address the problem of under-representation of samples with large out-of-plane head rotations in the training set, we propose a simple but effective boosting strategy, referred to as pose-based data balancing. In particular, we deal with the data imbalance problem by duplicating the minority training samples and perturbing them by injecting random image rotation, bounding box translation and other data augmentation approaches. Last, the proposed approach is extended to create a two-stage framework for robust facial landmark localisation. The experimental results obtained on AFLW and 300W demonstrate the merits of the Wing loss function, and prove the superiority of the proposed method over the state-of-the-art approaches.
Evaluation of Dense 3D Reconstruction from 2D Face Images in the Wild
Apr 20, 2018
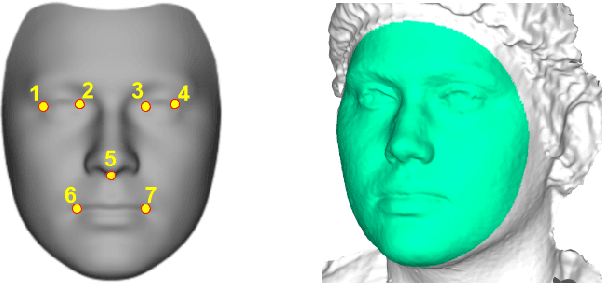

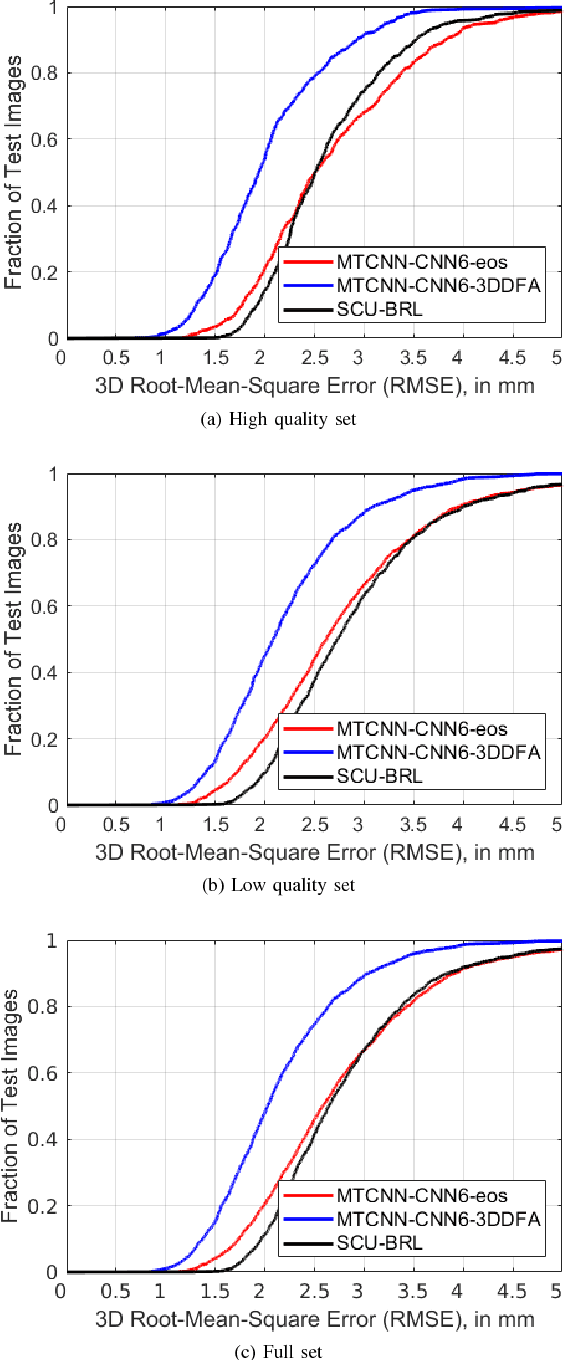
This paper investigates the evaluation of dense 3D face reconstruction from a single 2D image in the wild. To this end, we organise a competition that provides a new benchmark dataset that contains 2000 2D facial images of 135 subjects as well as their 3D ground truth face scans. In contrast to previous competitions or challenges, the aim of this new benchmark dataset is to evaluate the accuracy of a 3D dense face reconstruction algorithm using real, accurate and high-resolution 3D ground truth face scans. In addition to the dataset, we provide a standard protocol as well as a Python script for the evaluation. Last, we report the results obtained by three state-of-the-art 3D face reconstruction systems on the new benchmark dataset. The competition is organised along with the 2018 13th IEEE Conference on Automatic Face & Gesture Recognition.
3D Morphable Models as Spatial Transformer Networks
Aug 23, 2017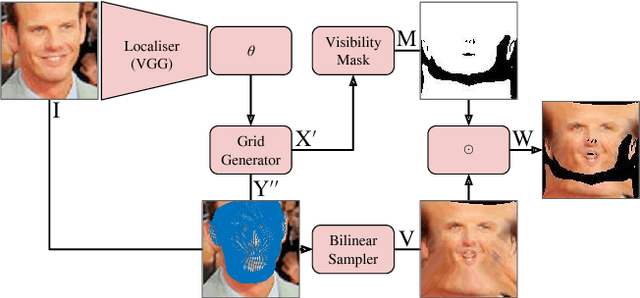
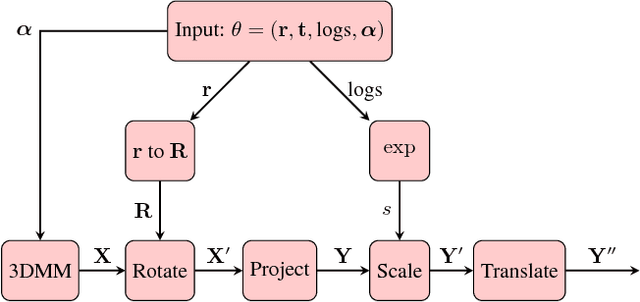

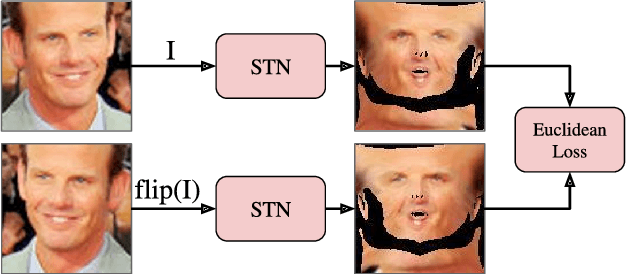
In this paper, we show how a 3D Morphable Model (i.e. a statistical model of the 3D shape of a class of objects such as faces) can be used to spatially transform input data as a module (a 3DMM-STN) within a convolutional neural network. This is an extension of the original spatial transformer network in that we are able to interpret and normalise 3D pose changes and self-occlusions. The trained localisation part of the network is independently useful since it learns to fit a 3D morphable model to a single image. We show that the localiser can be trained using only simple geometric loss functions on a relatively small dataset yet is able to perform robust normalisation on highly uncontrolled images including occlusion, self-occlusion and large pose changes.
Face Detection, Bounding Box Aggregation and Pose Estimation for Robust Facial Landmark Localisation in the Wild
Jun 01, 2017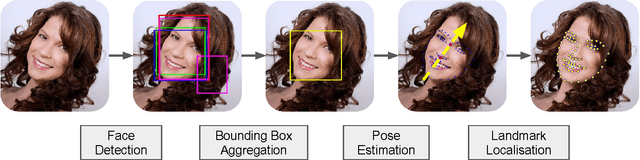



We present a framework for robust face detection and landmark localisation of faces in the wild, which has been evaluated as part of `the 2nd Facial Landmark Localisation Competition'. The framework has four stages: face detection, bounding box aggregation, pose estimation and landmark localisation. To achieve a high detection rate, we use two publicly available CNN-based face detectors and two proprietary detectors. We aggregate the detected face bounding boxes of each input image to reduce false positives and improve face detection accuracy. A cascaded shape regressor, trained using faces with a variety of pose variations, is then employed for pose estimation and image pre-processing. Last, we train the final cascaded shape regressor for fine-grained landmark localisation, using a large number of training samples with limited pose variations. The experimental results obtained on the 300W and Menpo benchmarks demonstrate the superiority of our framework over state-of-the-art methods.
Dynamic Attention-controlled Cascaded Shape Regression Exploiting Training Data Augmentation and Fuzzy-set Sample Weighting
Apr 04, 2017

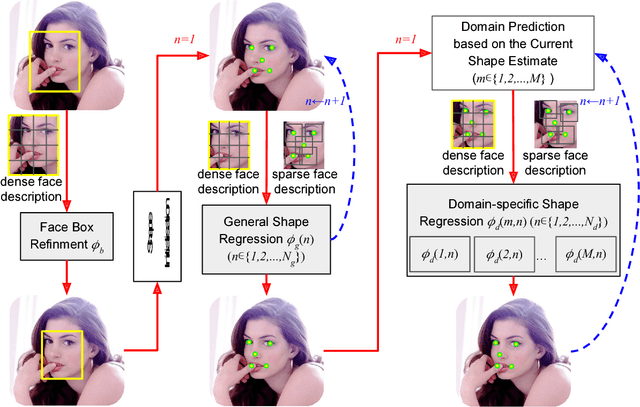

We present a new Cascaded Shape Regression (CSR) architecture, namely Dynamic Attention-Controlled CSR (DAC-CSR), for robust facial landmark detection on unconstrained faces. Our DAC-CSR divides facial landmark detection into three cascaded sub-tasks: face bounding box refinement, general CSR and attention-controlled CSR. The first two stages refine initial face bounding boxes and output intermediate facial landmarks. Then, an online dynamic model selection method is used to choose appropriate domain-specific CSRs for further landmark refinement. The key innovation of our DAC-CSR is the fault-tolerant mechanism, using fuzzy set sample weighting for attention-controlled domain-specific model training. Moreover, we advocate data augmentation with a simple but effective 2D profile face generator, and context-aware feature extraction for better facial feature representation. Experimental results obtained on challenging datasets demonstrate the merits of our DAC-CSR over the state-of-the-art.