 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Perspective on Literary Metaphor in the Context of Generative AI
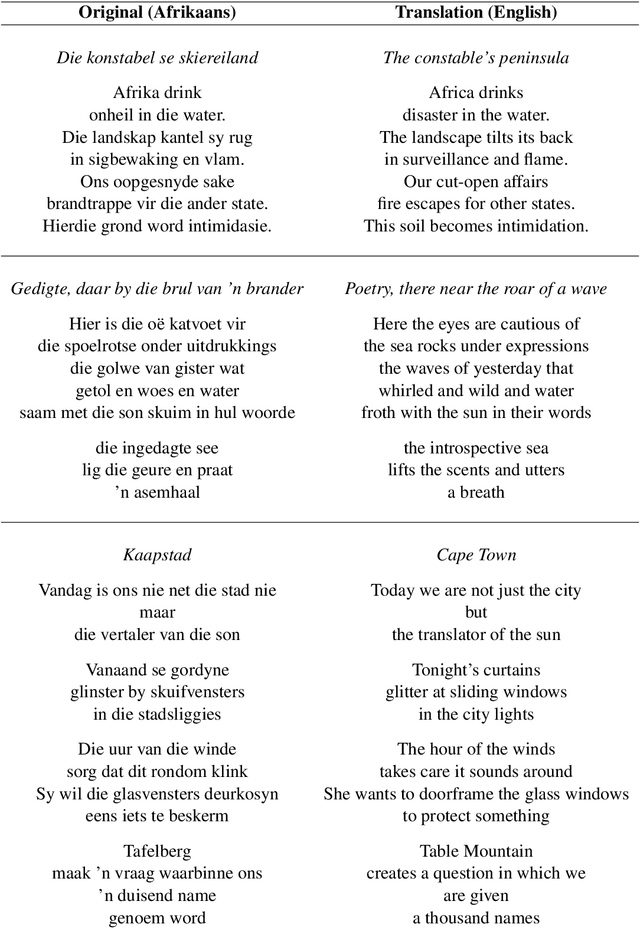
Sep 02, 2024At the intersection of creative text generation and literary theory, this study explores the role of literary metaphor and its capacity to generate a range of meanings. In this regard, literary metaphor is vital to the development of any particular language. To investigate whether the inclusion of original figurative language improves textual quality, we trained an LSTM-based language model in Afrikaans. The network produces phrases containing compellingly novel figures of speech. Specifically, the emphasis falls on how AI might be utilised as a defamiliarisation technique, which disrupts expected uses of language to augment poetic expression. Providing a literary perspective on text generation, the paper raises thought-provoking questions on aesthetic value, interpretation and evaluation.
AfriKI: Machine-in-the-Loop Afrikaans Poetry Generation
Mar 30, 2021
This paper proposes a generative language model called AfriKI. Our approach is based on an LSTM architecture trained on a small corpus of contemporary fiction. With the aim of promoting human creativity, we use the model as an authoring tool to explore machine-in-the-loop Afrikaans poetry generation. To our knowledge, this is the first study to attempt creative text generation in Afrikaans.
Exploring Transformers in Natural Language Generation: GPT, BERT, and XLNet
Feb 16, 2021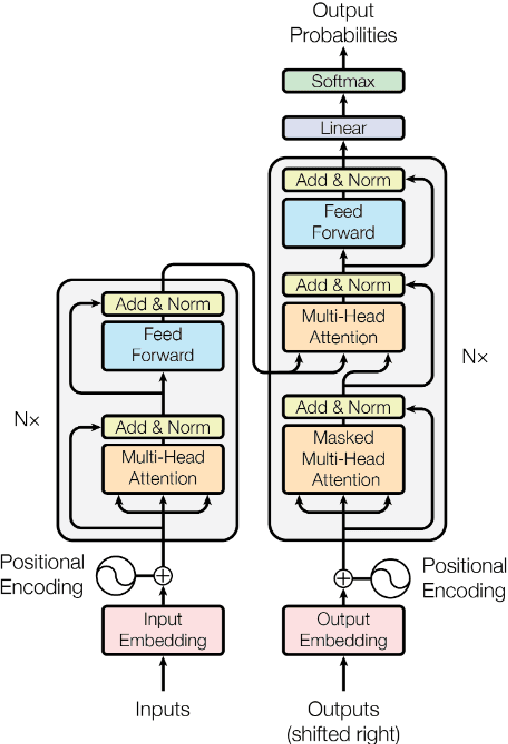


Recent years have seen a proliferation of attention mechanisms and the rise of Transformers in Natural Language Generation (NLG). Previously, state-of-the-art NLG architectures such as RNN and LSTM ran into vanishing gradient problems; as sentences grew larger, distance between positions remained linear, and sequential computation hindered parallelization since sentences were processed word by word. Transformers usher in a new era. In this paper, we explore three major Transformer-based models, namely GPT, BERT, and XLNet, that carry significant implications for the field. NLG is a burgeoning area that is now bolstered with rapid developments in attention mechanisms. From poetry generation to summarization, text generation derives benefit as Transformer-based language models achieve groundbreaking results.
What does 2D geometric information really tell us about 3D face shape?
Apr 16, 2018


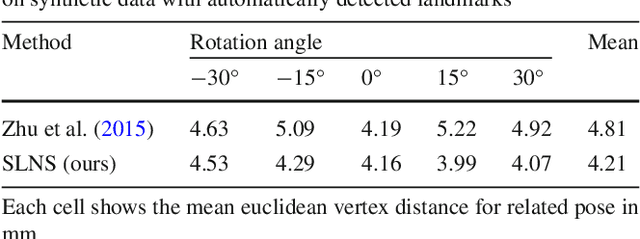
A face image contains geometric cues in the form of configurational information and contours that can be used to estimate 3D face shape. While it is clear that 3D reconstruction from 2D points is highly ambiguous if no further constraints are enforced, one might expect that the face-space constraint solves this problem. We show that this is not the case and that geometric information is an ambiguous cue. There are two sources for this ambiguity. The first is that, within the space of 3D face shapes, there are flexibility modes that remain when some parts of the face are fixed. The second occurs only under perspective projection and is a result of perspective transformation as camera distance varies. Two different faces, when viewed at different distances, can give rise to the same 2D geometry. To demonstrate these ambiguities, we develop new algorithms for fitting a 3D morphable model to 2D landmarks or contours under either orthographic or perspective projection and show how to compute flexibility modes for both cases. We show that both fitting problems can be posed as a separable nonlinear least squares problem and solved efficiently. We provide quantitative and qualitative evidence that the ambiguity exists in synthetic data and real images.
Statistical transformer networks: learning shape and appearance models via self supervision
Apr 07, 2018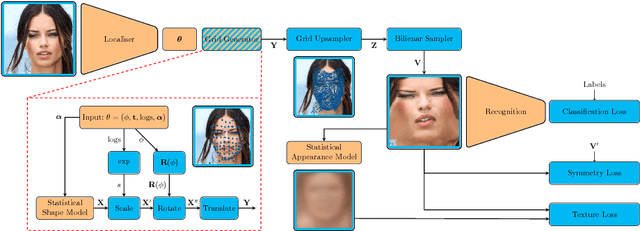
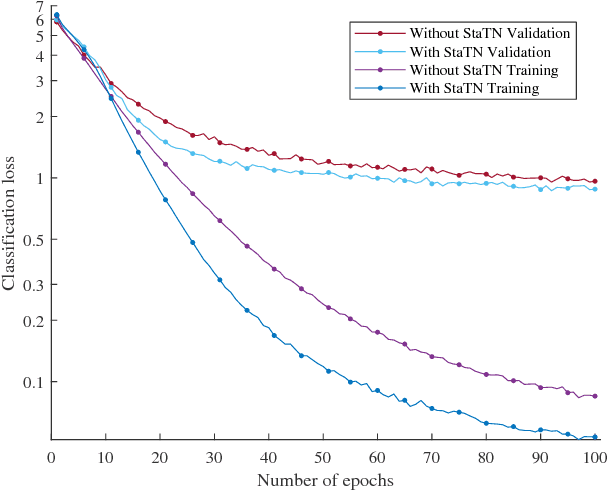

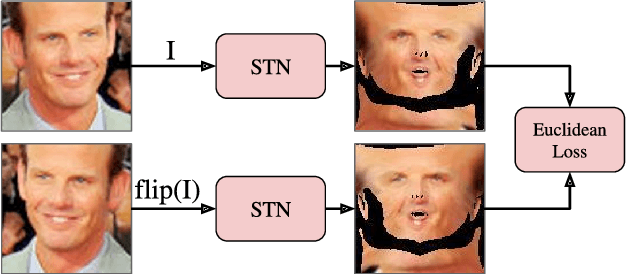
We generalise Spatial Transformer Networks (STN) by replacing the parametric transformation of a fixed, regular sampling grid with a deformable, statistical shape model which is itself learnt. We call this a Statistical Transformer Network (StaTN). By training a network containing a StaTN end-to-end for a particular task, the network learns the optimal nonrigid alignment of the input data for the task. Moreover, the statistical shape model is learnt with no direct supervision (such as landmarks) and can be reused for other tasks. Besides training for a specific task, we also show that a StaTN can learn a shape model using generic loss functions. This includes a loss inspired by the minimum description length principle in which an appearance model is also learnt from scratch. In this configuration, our model learns an active appearance model and a means to fit the model from scratch with no supervision at all, even identity labels.
3D Morphable Models as Spatial Transformer Networks
Aug 23, 2017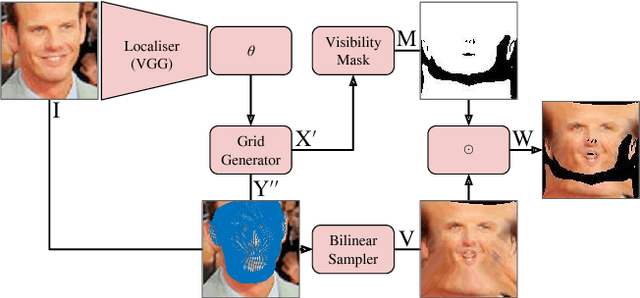
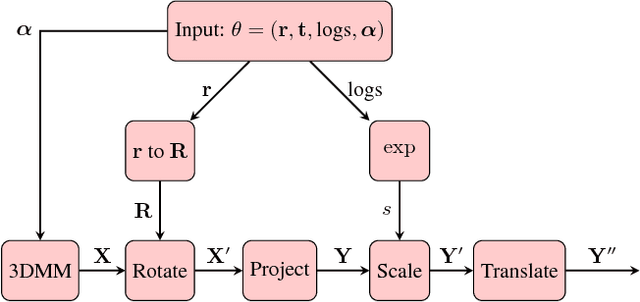

In this paper, we show how a 3D Morphable Model (i.e. a statistical model of the 3D shape of a class of objects such as faces) can be used to spatially transform input data as a module (a 3DMM-STN) within a convolutional neural network. This is an extension of the original spatial transformer network in that we are able to interpret and normalise 3D pose changes and self-occlusions. The trained localisation part of the network is independently useful since it learns to fit a 3D morphable model to a single image. We show that the localiser can be trained using only simple geometric loss functions on a relatively small dataset yet is able to perform robust normalisation on highly uncontrolled images including occlusion, self-occlusion and large pose changes.
Fitting a 3D Morphable Model to Edges: A Comparison Between Hard and Soft Correspondences
Oct 03, 2016
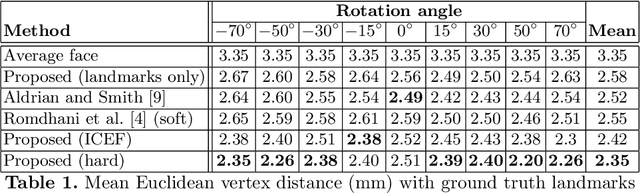
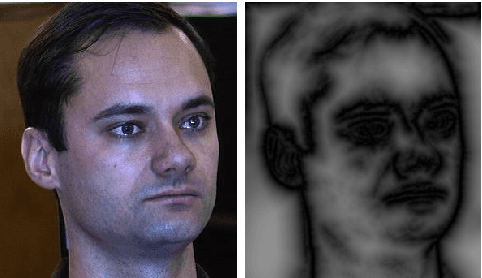
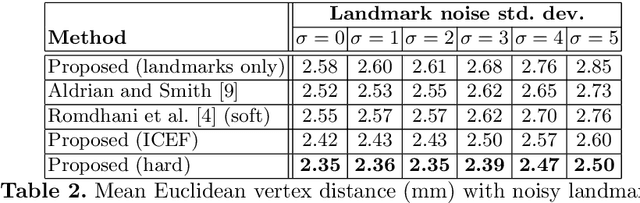
We propose a fully automatic method for fitting a 3D morphable model to single face images in arbitrary pose and lighting. Our approach relies on geometric features (edges and landmarks) and, inspired by the iterated closest point algorithm, is based on computing hard correspondences between model vertices and edge pixels. We demonstrate that this is superior to previous work that uses soft correspondences to form an edge-derived cost surface that is minimised by nonlinear optimisation.