 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFake It Without Making It: Conditioned Face Generation for Accurate 3D Face Shape Estimation
Jul 25, 2023
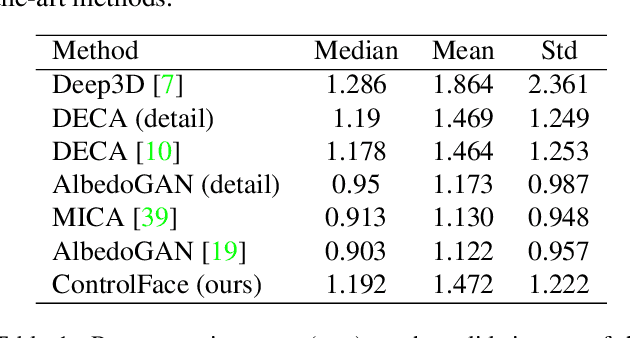
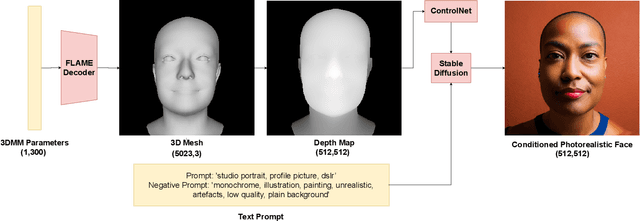

Accurate 3D face shape estimation is an enabling technology with applications in healthcare, security, and creative industries, yet current state-of-the-art methods either rely on self-supervised training with 2D image data or supervised training with very limited 3D data. To bridge this gap, we present a novel approach which uses a conditioned stable diffusion model for face image generation, leveraging the abundance of 2D facial information to inform 3D space. By conditioning stable diffusion on depth maps sampled from a 3D Morphable Model (3DMM) of the human face, we generate diverse and shape-consistent images, forming the basis of SynthFace. We introduce this large-scale synthesised dataset of 250K photorealistic images and corresponding 3DMM parameters. We further propose ControlFace, a deep neural network, trained on SynthFace, which achieves competitive performance on the NoW benchmark, without requiring 3D supervision or manual 3D asset creation.
Text2Face: A Multi-Modal 3D Face Model
Mar 08, 2023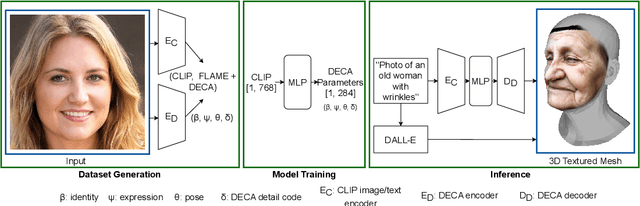



We present the first 3D morphable modelling approach, whereby 3D face shape can be directly and completely defined using a textual prompt. Building on work in multi-modal learning, we extend the FLAME head model to a common image-and-text latent space. This allows for direct 3D Morphable Model (3DMM) parameter generation and therefore shape manipulation from textual descriptions. Our method, Text2Face, has many applications; for example: generating police photofits where the input is already in natural language. It further enables multi-modal 3DMM image fitting to sketches and sculptures, as well as images.