Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Face: A Multi-Modal 3D Face Model
Paper and Code
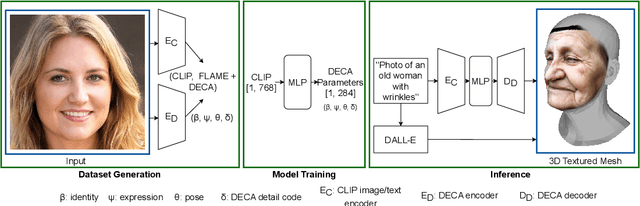



We present the first 3D morphable modelling approach, whereby 3D face shape can be directly and completely defined using a textual prompt. Building on work in multi-modal learning, we extend the FLAME head model to a common image-and-text latent space. This allows for direct 3D Morphable Model (3DMM) parameter generation and therefore shape manipulation from textual descriptions. Our method, Text2Face, has many applications; for example: generating police photofits where the input is already in natural language. It further enables multi-modal 3DMM image fitting to sketches and sculptures, as well as images.
* Fixed formatting and a typo
View paper on