 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training strategies and datasets for facial representation learning
Mar 30, 2021
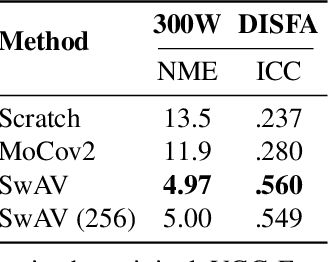
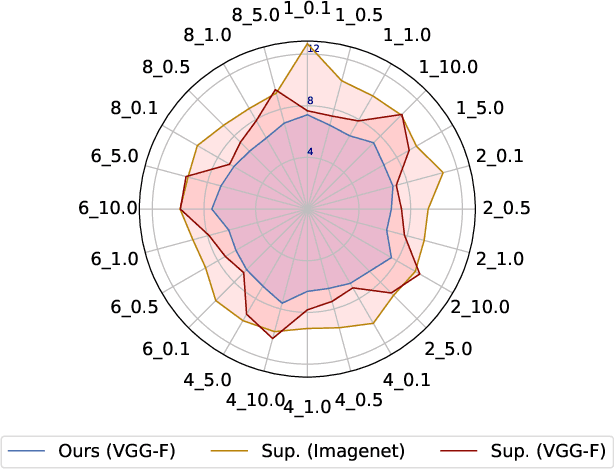
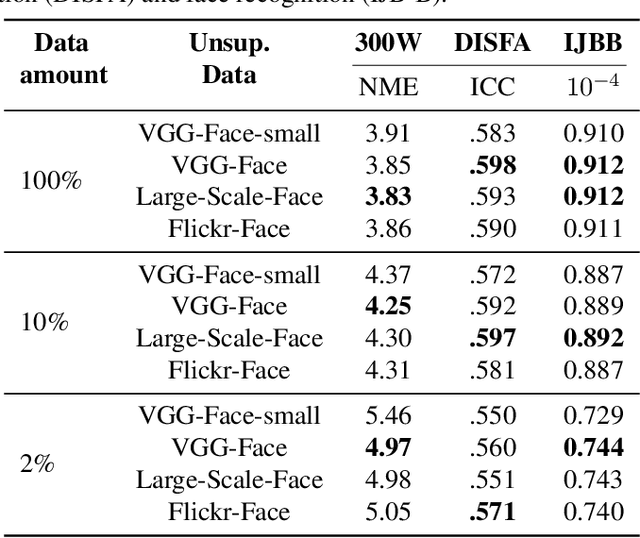
What is the best way to learn a universal face representation? Recent work on Deep Learning in the area of face analysis has focused on supervised learning for specific tasks of interest (e.g. face recognition, facial landmark localization etc.) but has overlooked the overarching question of how to find a facial representation that can be readily adapted to several facial analysis tasks and datasets. To this end, we make the following 4 contributions: (a) we introduce, for the first time, a comprehensive evaluation benchmark for facial representation learning consisting of 5 important face analysis tasks. (b) We systematically investigate two ways of large-scale representation learning applied to faces: supervised and unsupervised pre-training. Importantly, we focus our evaluations on the case of few-shot facial learning. (c) We investigate important properties of the training datasets including their size and quality (labelled, unlabelled or even uncurated). (d) To draw our conclusions, we conducted a very large number of experiments. Our main two findings are: (1) Unsupervised pre-training on completely in-the-wild, uncurated data provides consistent and, in some cases, significant accuracy improvements for all facial tasks considered. (2) Many existing facial video datasets seem to have a large amount of redundancy. We will release code, pre-trained models and data to facilitate future research.
Towards Pose-invariant Lip-Reading
Nov 14, 2019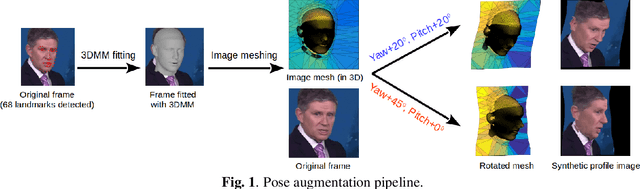
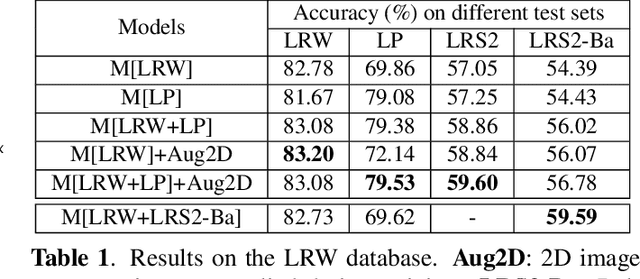
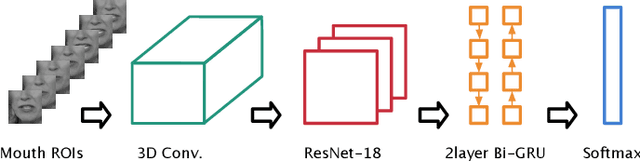
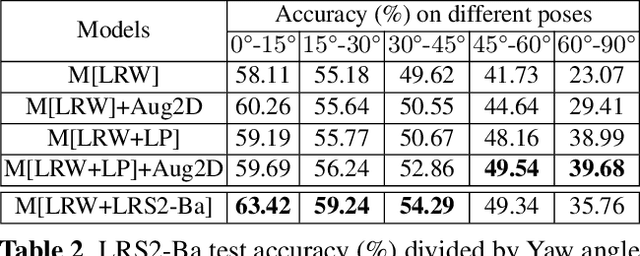
Lip-reading models have been significantly improved recently thanks to powerful deep learning architectures. However, most works focused on frontal or near frontal views of the mouth. As a consequence, lip-reading performance seriously deteriorates in non-frontal mouth views. In this work, we present a framework for training pose-invariant lip-reading models on synthetic data instead of collecting and annotating non-frontal data which is costly and tedious. The proposed model significantly outperforms previous approaches on non-frontal views while retaining the superior performance on frontal and near frontal mouth views. Specifically, we propose to use a 3D Morphable Model (3DMM) to augment LRW, an existing large-scale but mostly frontal dataset, by generating synthetic facial data in arbitrary poses. The newly derived dataset, is used to train a state-of-the-art neural network for lip-reading. We conducted a cross-database experiment for isolated word recognition on the LRS2 dataset, and reported an absolute improvement of 2.55%. The benefit of the proposed approach becomes clearer in extreme poses where an absolute improvement of up to 20.64% over the baseline is achieved.
Shape Constrained Network for Eye Segmentation in the Wild
Oct 11, 2019

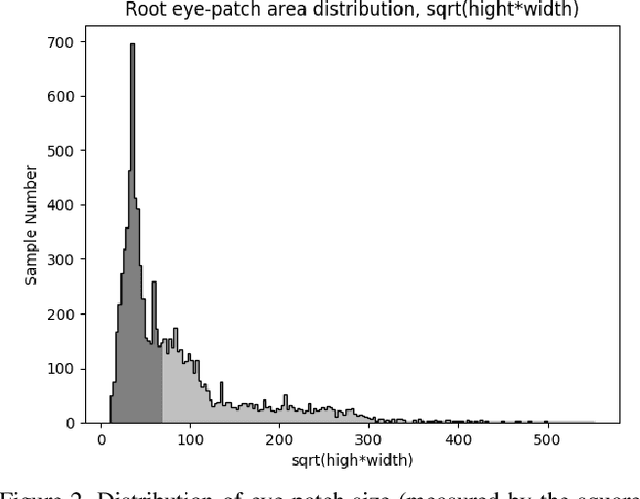
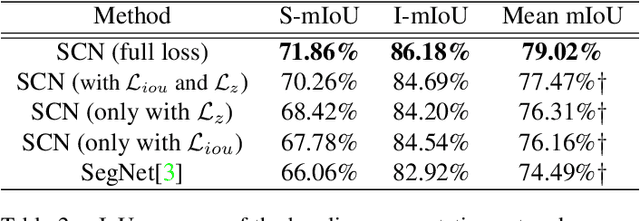
Semantic segmentation of eyes has long been a vital pre-processing step in many biometric applications. Majority of the works focus only on high resolution eye images, while little has been done to segment the eyes from low quality images in the wild. However, this is a particularly interesting and meaningful topic, as eyes play a crucial role in conveying the emotional state and mental well-being of a person. In this work, we take two steps toward solving this problem: (1) We collect and annotate a challenging eye segmentation dataset containing 8882 eye patches from 4461 facial images of different resolutions, illumination conditions and head poses; (2) We develop a novel eye segmentation method, Shape Constrained Network (SCN), that incorporates shape prior into the segmentation network training procedure. Specifically, we learn the shape prior from our dataset using VAE-GAN, and leverage the pre-trained encoder and discriminator to regularise the training of SegNet. To improve the accuracy and quality of predicted masks, we replace the loss of SegNet with three new losses: Intersection-over-Union (IoU) loss, shape discriminator loss and shape embedding loss. Extensive experiments shows that our method outperforms state-of-the-art segmentation and landmark detection methods in terms of mean IoU (mIoU) accuracy and the quality of segmentation masks. The eye segmentation database is available at https://www.dropbox.com/s/yvveouvxsvti08x/Eye_Segmentation_Database.zip?dl=0.
Dynamic Face Video Segmentation via Reinforcement Learning
Jul 02, 2019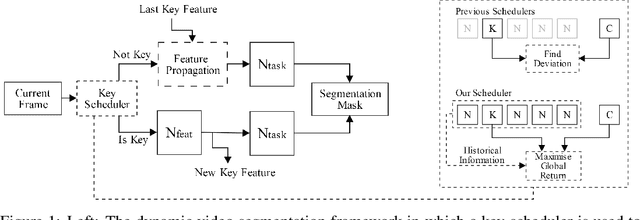
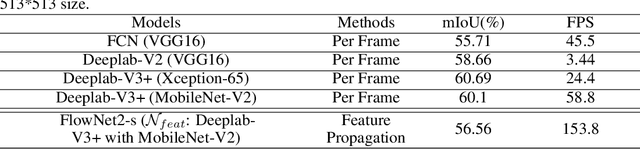
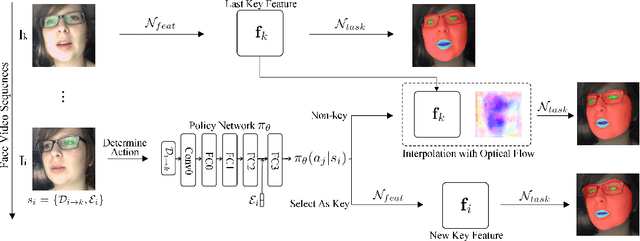
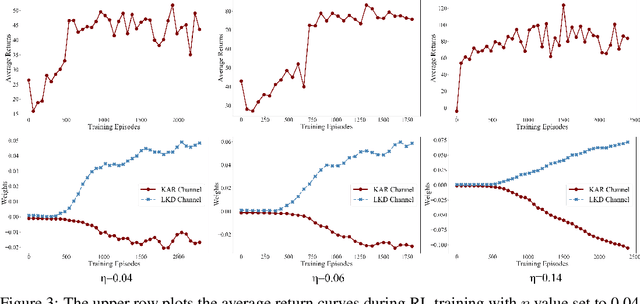
For real-time semantic video segmentation, most recent works utilise a dynamic framework with a key scheduler to make online key/non-key decisions. Some works used a fixed key scheduling policy, while others proposed adaptive key scheduling methods based on heuristic strategies, both of which may lead to suboptimal global performance. To overcome this limitation, we propose to model the online key decision process in dynamic video segmentation as a deep reinforcement learning problem, and to learn an efficient and effective scheduling policy from expert information about decision history and from the process of maximising global return. Moreover, we study the application of dynamic video segmentation on face videos, a field that has not been investigated before. By evaluating on the 300VW dataset, we show that the performance of our reinforcement key scheduler outperforms that of various baseline approaches, and our method could also achieve real-time processing speed. To the best of our knowledge, this is the first work to use reinforcement learning for online key-frame decision in dynamic video segmentation, and also the first work on its application on face videos.
MeshGAN: Non-linear 3D Morphable Models of Faces
Mar 25, 2019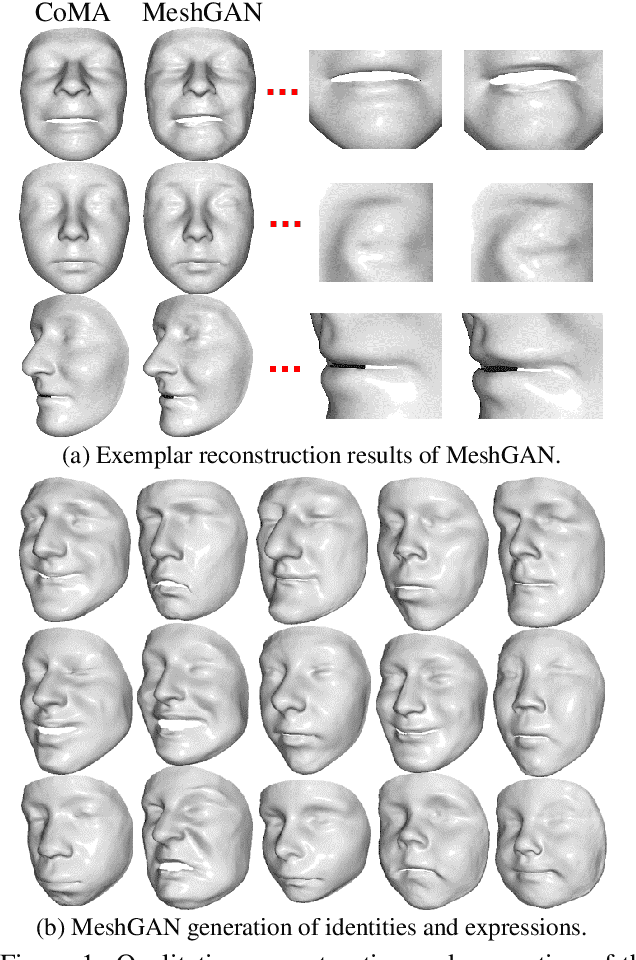


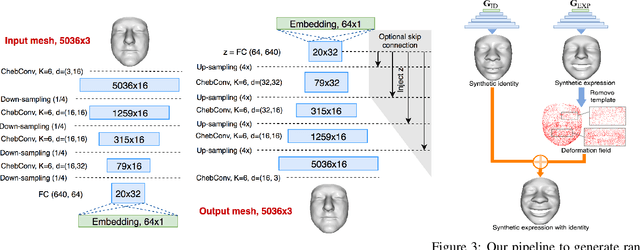
Generative Adversarial Networks (GANs) are currently the method of choice for generating visual data. Certain GAN architectures and training methods have demonstrated exceptional performance in generating realistic synthetic images (in particular, of human faces). However, for 3D object, GANs still fall short of the success they have had with images. One of the reasons is due to the fact that so far GANs have been applied as 3D convolutional architectures to discrete volumetric representations of 3D objects. In this paper, we propose the first intrinsic GANs architecture operating directly on 3D meshes (named as MeshGAN). Both quantitative and qualitative results are provided to show that MeshGAN can be used to generate high-fidelity 3D face with rich identities and expressions.
Generating faces for affect analysis
Nov 12, 2018
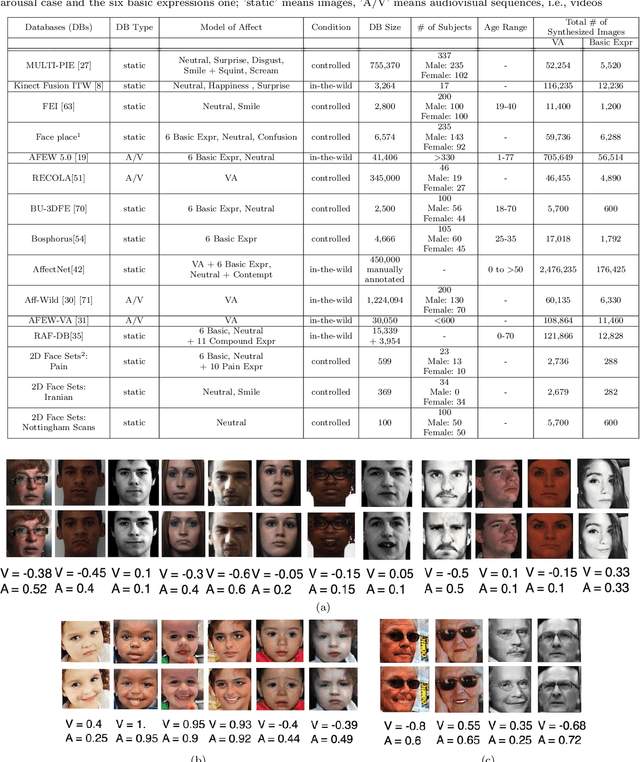

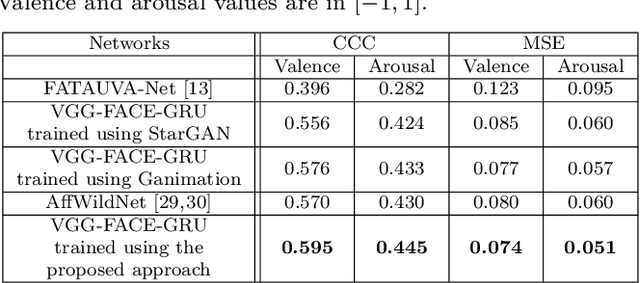
This paper presents a novel approach for synthesizing facial affect; either categorical, in terms of the six basic expressions (i.e., anger, disgust, fear, happiness, sadness and surprise), or dimensional, in terms of valence (i.e., how positive or negative is an emotion) and arousal (i.e., power of the emotion activation). In the Valence-Arousal case, a system is created, based on VA annotation of 600,000 frames from the 4DFAB database; in the categorical case, the system is based on the selection of apex frames of posed expression sequences from the 4DFAB. The proposed system accepts at its input: i) either the basic facial expression, or the pair of valence-arousal emotional state descriptors, which need to be synthesized and ii) a neutral 2D image of a person on which the corresponding affect will be synthesized. The proposed approach consists of the following steps: First, based on the provided desired emotional state, a set of 3D facial meshes is produced from the 4DFAB database and is used to build a blendshape model that generates the new facial affect. To synthesize this affect on the 2D neutral image, 3D Morphable Models fitting is performed and the reconstructed face is then deformed to generate the target facial expressions. Finally, the new face is rendered into the original image. Qualitative experimental studies illustrate the generation of realistic images, when the neutral image is sampled from a variety of well known lab-controlled or in-the-wild databases, including Aff-Wild, RECOLA, AffectNet, AFEW, Multi-PIE, AFEW-VA, BU-3DFE, Bosphorus, RAF-DB. Also, quantitative experiments are conducted, in which deep neural networks, trained using the generated images from each of the above databases in a data-augmentation framework, provide affect recognition; better performances are achieved through the presented approach when compared with the current state-of-the-art.
Photorealistic Facial Synthesis in the Dimensional Affect Space
Nov 11, 2018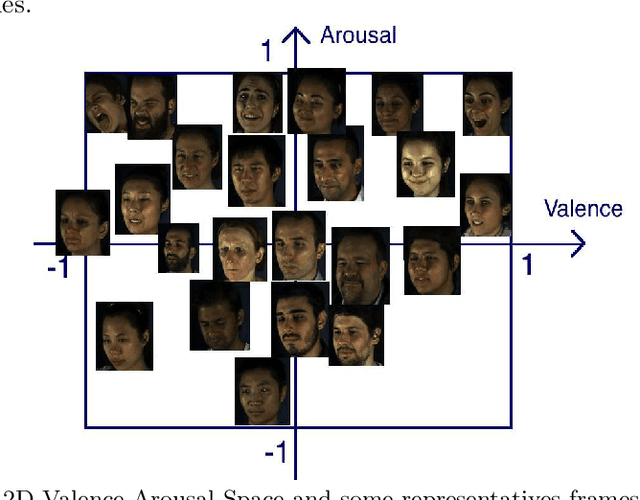
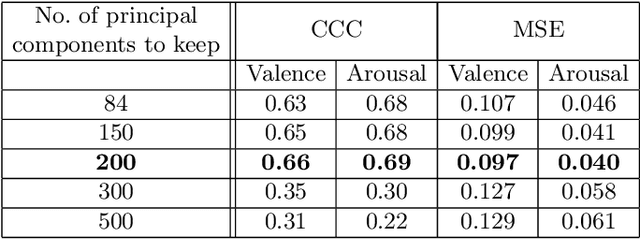
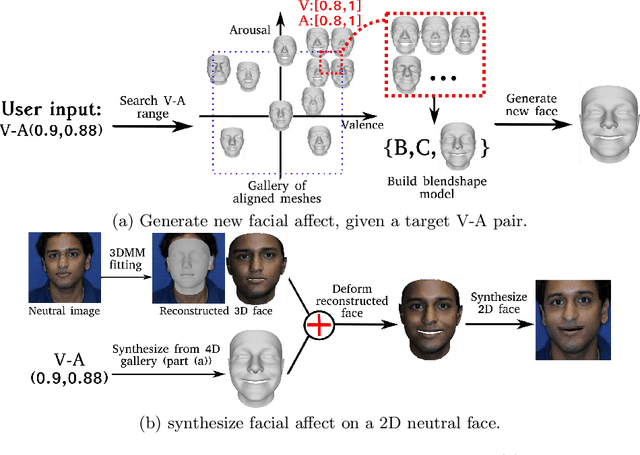

This paper presents a novel approach for synthesizing facial affect, which is based on our annotating 600,000 frames of the 4DFAB database in terms of valence and arousal. The input of this approach is a pair of these emotional state descriptors and a neutral 2D image of a person to whom the corresponding affect will be synthesized. Given this target pair, a set of 3D facial meshes is selected, which is used to build a blendshape model and generate the new facial affect. To synthesize the affect on the 2D neutral image, 3DMM fitting is performed and the reconstructed face is deformed to generate the target facial expressions. Last, the new face is rendered into the original image. Both qualitative and quantitative experimental studies illustrate the generation of realistic images, when the neutral image is sampled from a variety of well known databases, such as the Aff-Wild, AFEW, Multi-PIE, AFEW-VA, BU-3DFE, Bosphorus.
4DFAB: A Large Scale 4D Facial Expression Database for Biometric Applications
Jun 14, 2018
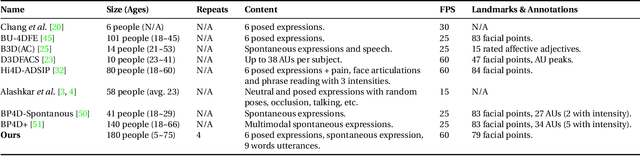


The progress we are currently witnessing in many computer vision applications, including automatic face analysis, would not be made possible without tremendous efforts in collecting and annotating large scale visual databases. To this end, we propose 4DFAB, a new large scale database of dynamic high-resolution 3D faces (over 1,800,000 3D meshes). 4DFAB contains recordings of 180 subjects captured in four different sessions spanning over a five-year period. It contains 4D videos of subjects displaying both spontaneous and posed facial behaviours. The database can be used for both face and facial expression recognition, as well as behavioural biometrics. It can also be used to learn very powerful blendshapes for parametrising facial behaviour. In this paper, we conduct several experiments and demonstrate the usefulness of the database for various applications. The database will be made publicly available for research purposes.
Mobile Face Tracking: A Survey and Benchmark
May 24, 2018

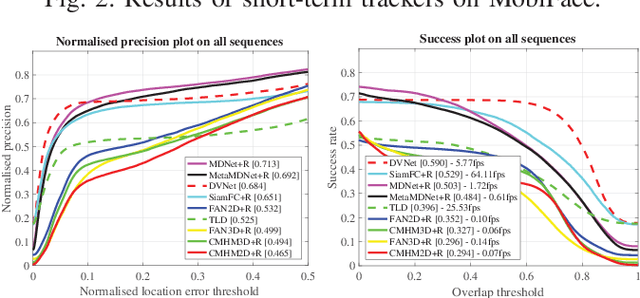
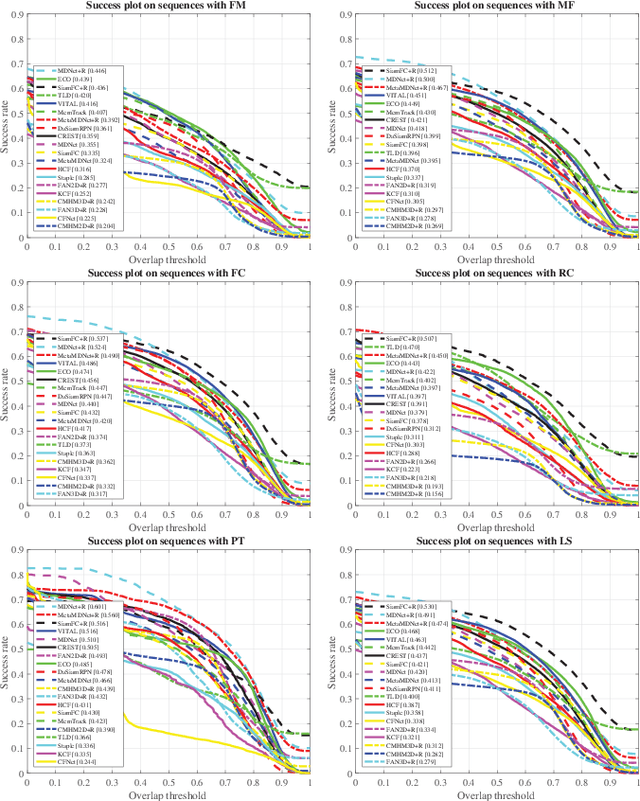
With the rapid development of smartphones, facial analysis has been playing an increasingly important role in a multitude of mobile applications. In most scenarios, face tracking serves as a crucial first step because more often than not, a mobile application would only need to focus on analysing a specific face in a complex setting. Albeit inheriting many commons traits of the generic visual tracking problem, face tracking in mobile scenarios is characterised by a unique set of challenges. In this work, we propose iBUG MobiFace benchmark, the first mobile face tracking benchmark consisting of 50 sequences captured by smartphone users in unconstrained environments. The sequences contain a total of 50,736 frames with 46 distinct identities to be tracked. The tracking target in each sequence is selected with varying difficulties in mobile scenarios. In addition to frame by frame bounding box, the annotations of 9 sequence attributes(e.g. multiple faces) are provided. We further provide a survey of 23 state-of-the-art visual trackers and a comprehensive quantitative evaluation of these methods on the proposed benchmark. In particular, trackers from two most popular frameworks, namely, correlation filter-based tracking and deep learning-based tracking, are studied. Our experiment shows that (a) the performance of all existing generic object trackers drops significantly on the mobile face tracking scenario, suggesting the need of more research effort into mobile face tracking, and (b) the effective combination of deep learning tracking and face-related algorithms(e.g. face detection) provides the most promising basis for future developments in the field. The database, annotations and evaluation protocol/code will be made publicly available on the iBUG website.
An Adversarial Neuro-Tensorial Approach For Learning Disentangled Representations
Feb 24, 2018

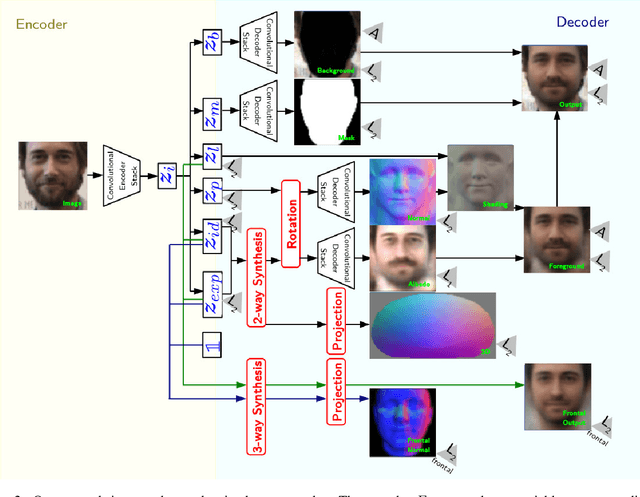

Several factors contribute to the appearance of an object in a visual scene, including pose, illumination, and deformation, among others. Each factor accounts for a source of variability in the data, while the multiplicative interactions of these factors emulate the entangled variability, giving rise to the rich structure of visual object appearance. Disentangling such unobserved factors from visual data is a challenging task, especially when the data have been captured in uncontrolled recording conditions (also referred to as "in-the-wild") and label information is not available. In this paper, we propose the first unsupervised deep learning method (with pseudo-supervision) for disentangling multiple latent factors of variation in face images captured in-the-wild. To this end, we propose a deep latent variable model, where the multiplicative interactions of multiple latent factors of variation are explicitly modelled by means of multilinear (tensor) structure. We demonstrate that the proposed approach indeed learns disentangled representations of facial expressions and pose, which can be used in various applications, including face editing, as well as 3D face reconstruction and classification of facial expression, identity and pose.