 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape Constrained Network for Eye Segmentation in the Wild
Oct 11, 2019

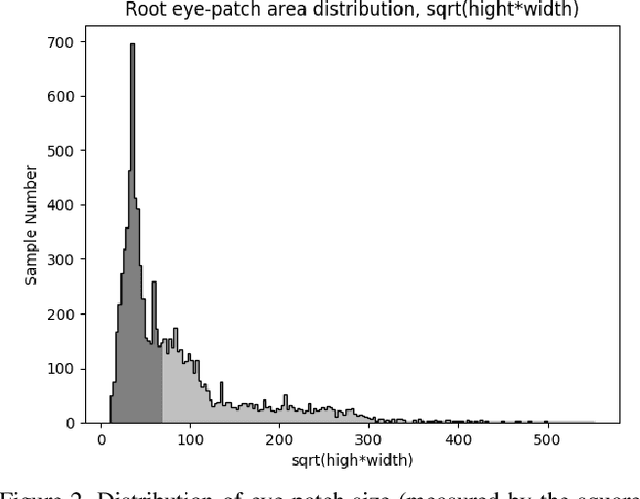
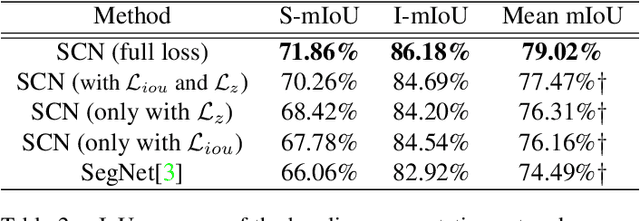
Semantic segmentation of eyes has long been a vital pre-processing step in many biometric applications. Majority of the works focus only on high resolution eye images, while little has been done to segment the eyes from low quality images in the wild. However, this is a particularly interesting and meaningful topic, as eyes play a crucial role in conveying the emotional state and mental well-being of a person. In this work, we take two steps toward solving this problem: (1) We collect and annotate a challenging eye segmentation dataset containing 8882 eye patches from 4461 facial images of different resolutions, illumination conditions and head poses; (2) We develop a novel eye segmentation method, Shape Constrained Network (SCN), that incorporates shape prior into the segmentation network training procedure. Specifically, we learn the shape prior from our dataset using VAE-GAN, and leverage the pre-trained encoder and discriminator to regularise the training of SegNet. To improve the accuracy and quality of predicted masks, we replace the loss of SegNet with three new losses: Intersection-over-Union (IoU) loss, shape discriminator loss and shape embedding loss. Extensive experiments shows that our method outperforms state-of-the-art segmentation and landmark detection methods in terms of mean IoU (mIoU) accuracy and the quality of segmentation masks. The eye segmentation database is available at https://www.dropbox.com/s/yvveouvxsvti08x/Eye_Segmentation_Database.zip?dl=0.
Face Mask Extraction in Video Sequence
Jul 24, 2018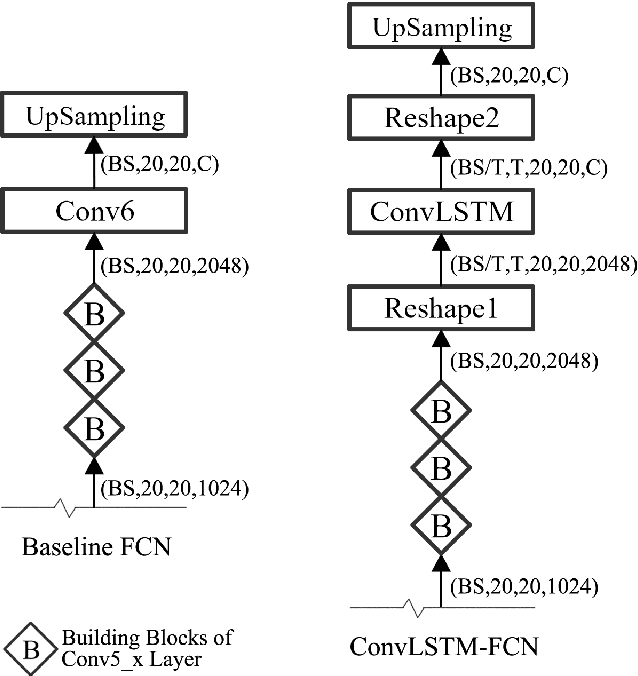
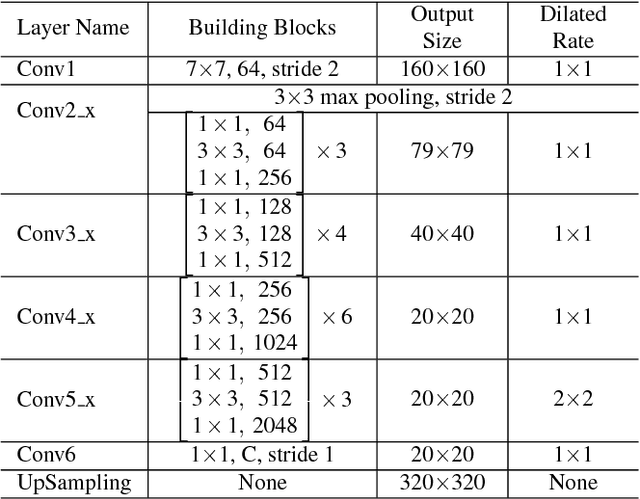
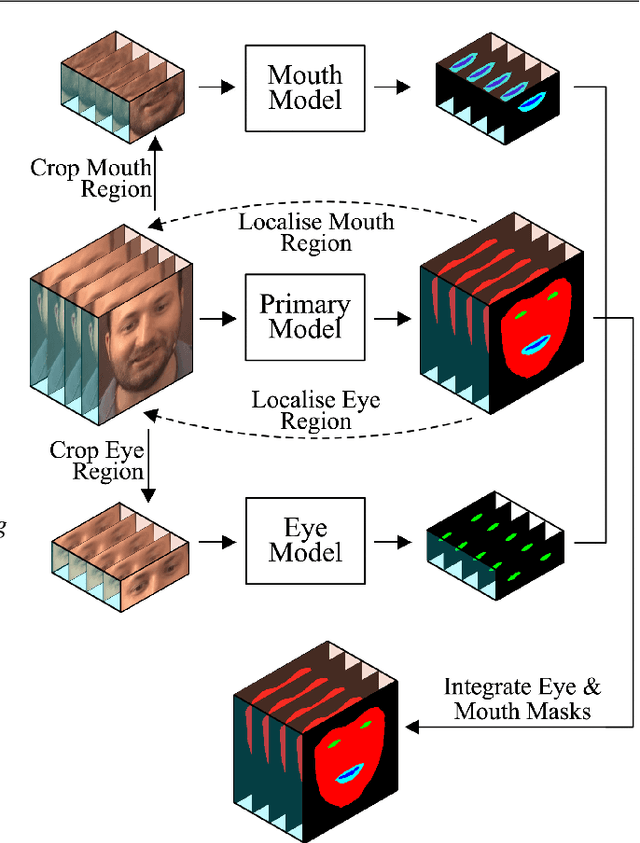
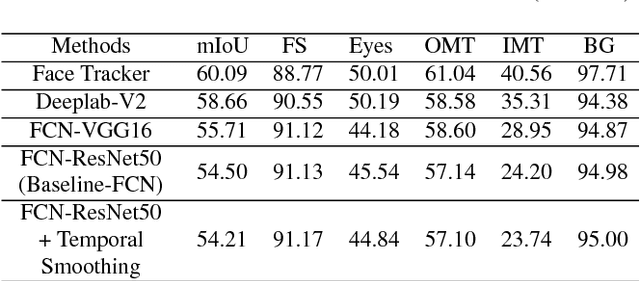
Inspired by the recent development of deep network-based methods in semantic image segmentation, we introduce an end-to-end trainable model for face mask extraction in video sequence. Comparing to landmark-based sparse face shape representation, our method can produce the segmentation masks of individual facial components, which can better reflect their detailed shape variations. By integrating Convolutional LSTM (ConvLSTM) algorithm with Fully Convolutional Networks (FCN), our new ConvLSTM-FCN model works on a per-sequence basis and takes advantage of the temporal correlation in video clips. In addition, we also propose a novel loss function, called Segmentation Loss, to directly optimise the Intersection over Union (IoU) performances. In practice, to further increase segmentation accuracy, one primary model and two additional models were trained to focus on the face, eyes, and mouth regions, respectively. Our experiment shows the proposed method has achieved a 16.99% relative improvement (from 54.50% to 63.76% mean IoU) over the baseline FCN model on the 300 Videos in the Wild (300VW) dataset.