 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Image Super Resolution with a Single Auto-Regressive Model
Jun 05, 2025In this paper we tackle Image Super Resolution (ISR), using recent advances in Visual Auto-Regressive (VAR) modeling. VAR iteratively estimates the residual in latent space between gradually increasing image scales, a process referred to as next-scale prediction. Thus, the strong priors learned during pre-training align well with the downstream task (ISR). To our knowledge, only VARSR has exploited this synergy so far, showing promising results. However, due to the limitations of existing residual quantizers, VARSR works only at a fixed resolution, i.e. it fails to map intermediate outputs to the corresponding image scales. Additionally, it relies on a 1B transformer architecture (VAR-d24), and leverages a large-scale private dataset to achieve state-of-the-art results. We address these limitations through two novel components: a) a Hierarchical Image Tokenization approach with a multi-scale image tokenizer that progressively represents images at different scales while simultaneously enforcing token overlap across scales, and b) a Direct Preference Optimization (DPO) regularization term that, relying solely on the LR and HR tokenizations, encourages the transformer to produce the latter over the former. To the best of our knowledge, this is the first time a quantizer is trained to force semantically consistent residuals at different scales, and the first time that preference-based optimization is used to train a VAR. Using these two components, our model can denoise the LR image and super-resolve at half and full target upscale factors in a single forward pass. Additionally, we achieve \textit{state-of-the-art results on ISR}, while using a small model (300M params vs ~1B params of VARSR), and without using external training data.
MeMSVD: Long-Range Temporal Structure Capturing Using Incremental SVD
Jun 11, 2024



This paper is on long-term video understanding where the goal is to recognise human actions over long temporal windows (up to minutes long). In prior work, long temporal context is captured by constructing a long-term memory bank consisting of past and future video features which are then integrated into standard (short-term) video recognition backbones through the use of attention mechanisms. Two well-known problems related to this approach are the quadratic complexity of the attention operation and the fact that the whole feature bank must be stored in memory for inference. To address both issues, we propose an alternative to attention-based schemes which is based on a low-rank approximation of the memory obtained using Singular Value Decomposition. Our scheme has two advantages: (a) it reduces complexity by more than an order of magnitude, and (b) it is amenable to an efficient implementation for the calculation of the memory bases in an incremental fashion which does not require the storage of the whole feature bank in memory. The proposed scheme matches or surpasses the accuracy achieved by attention-based mechanisms while being memory-efficient. Through extensive experiments, we demonstrate that our framework generalises to different architectures and tasks, outperforming the state-of-the-art in three datasets.
Multiscale Vision Transformers meet Bipartite Matching for efficient single-stage Action Localization
Dec 29, 2023



Action Localization is a challenging problem that combines detection and recognition tasks, which are often addressed separately. State-of-the-art methods rely on off-the-shelf bounding box detections pre-computed at high resolution and propose transformer models that focus on the classification task alone. Such two-stage solutions are prohibitive for real-time deployment. On the other hand, single-stage methods target both tasks by devoting part of the network (generally the backbone) to sharing the majority of the workload, compromising performance for speed. These methods build on adding a DETR head with learnable queries that, after cross- and self-attention can be sent to corresponding MLPs for detecting a person's bounding box and action. However, DETR-like architectures are challenging to train and can incur in big complexity. In this paper, we observe that a straight bipartite matching loss can be applied to the output tokens of a vision transformer. This results in a backbone + MLP architecture that can do both tasks without the need of an extra encoder-decoder head and learnable queries. We show that a single MViT-S architecture trained with bipartite matching to perform both tasks surpasses the same MViT-S when trained with RoI align on pre-computed bounding boxes. With a careful design of token pooling and the proposed training pipeline, our MViTv2-S model achieves +3 mAP on AVA2.2. w.r.t. the two-stage counterpart. Code and models will be released after paper revision.
Variational prompt tuning improves generalization of vision-language models
Oct 05, 2022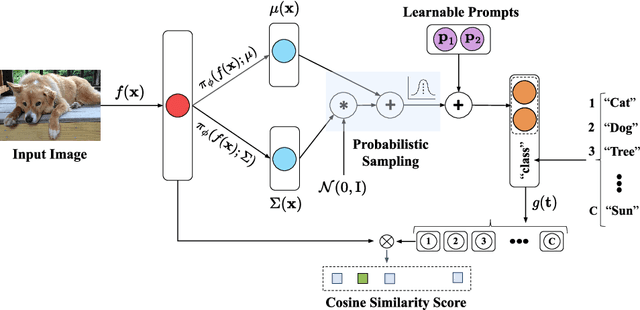
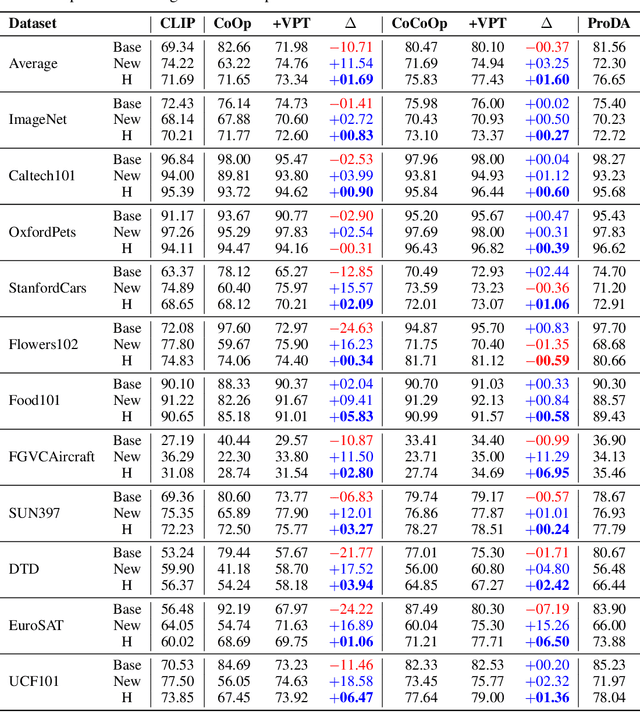
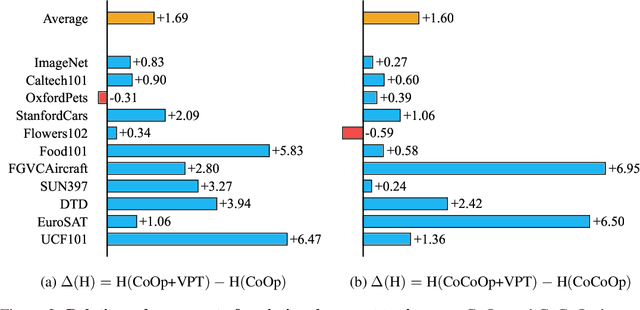
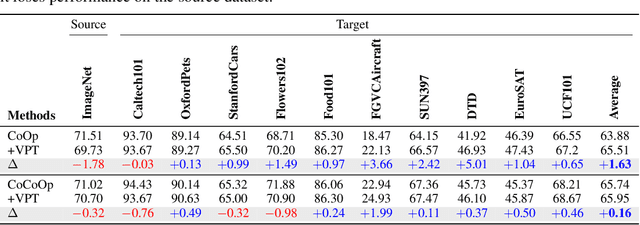
Prompt tuning provides an efficient mechanism to adapt large vision-language models to downstream tasks by treating part of the input language prompts as learnable parameters while freezing the rest of the model. Existing works for prompt tuning are however prone to damaging the generalization capabilities of the foundation models, because the learned prompts lack the capacity of covering certain concepts within the language model. To avoid such limitation, we propose a probabilistic modeling of the underlying distribution of prompts, allowing prompts within the support of an associated concept to be derived through stochastic sampling. This results in a more complete and richer transfer of the information captured by the language model, providing better generalization capabilities for downstream tasks. The resulting algorithm relies on a simple yet powerful variational framework that can be directly integrated with other developments. We show our approach is seamlessly integrated into both standard and conditional prompt learning frameworks, improving the performance on both cases considerably, especially with regards to preserving the generalization capability of the original model. Our method provides the current state-of-the-art for prompt learning, surpassing CoCoOp by 1.6% average Top-1 accuracy on the standard benchmark. Remarkably, it even surpasses the original CLIP model in terms of generalization to new classes. Implementation code will be released.
REST: REtrieve & Self-Train for generative action recognition
Sep 29, 2022

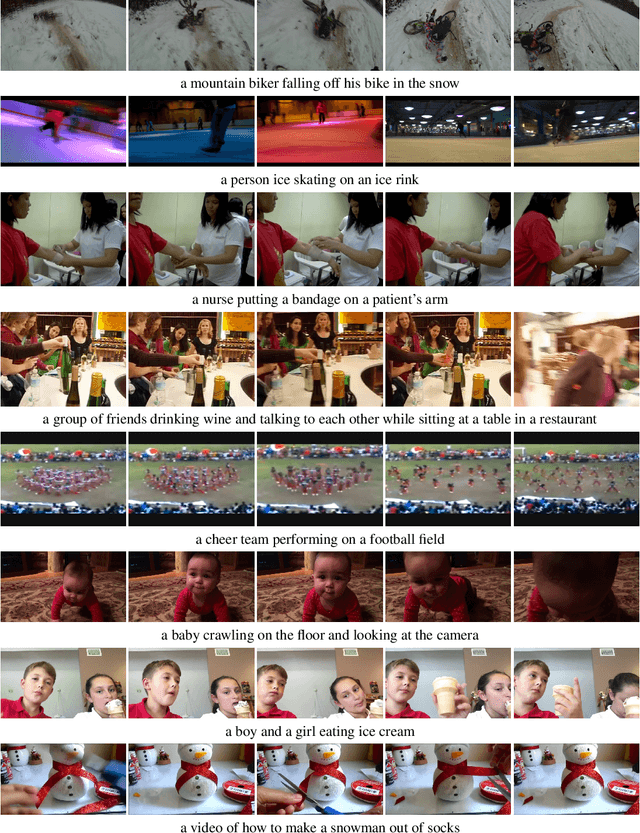
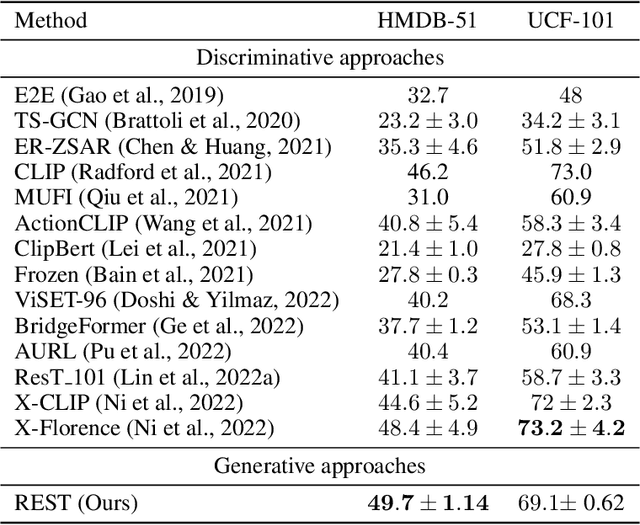
This work is on training a generative action/video recognition model whose output is a free-form action-specific caption describing the video (rather than an action class label). A generative approach has practical advantages like producing more fine-grained and human-readable output, and being naturally open-world. To this end, we propose to adapt a pre-trained generative Vision & Language (V&L) Foundation Model for video/action recognition. While recently there have been a few attempts to adapt V&L models trained with contrastive learning (e.g. CLIP) for video/action, to the best of our knowledge, we propose the very first method that sets outs to accomplish this goal for a generative model. We firstly show that direct fine-tuning of a generative model to produce action classes suffers from severe overfitting. To alleviate this, we introduce REST, a training framework consisting of two key components: an unsupervised method for adapting the generative model to action/video by means of pseudo-caption generation and Self-training, i.e. without using any action-specific labels; (b) a Retrieval approach based on CLIP for discovering a diverse set of pseudo-captions for each video to train the model. Importantly, we show that both components are necessary to obtain high accuracy. We evaluate REST on the problem of zero-shot action recognition where we show that our approach is very competitive when compared to contrastive learning-based methods. Code will be made available.
From Keypoints to Object Landmarks via Self-Training Correspondence: A novel approach to Unsupervised Landmark Discovery
May 31, 2022
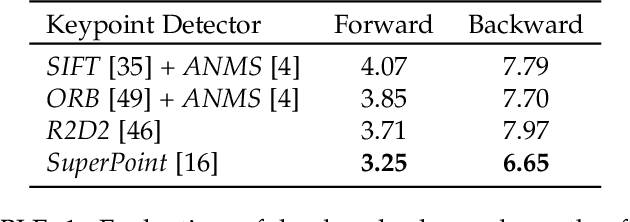
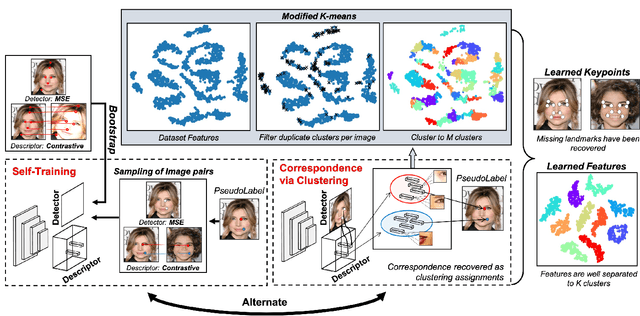
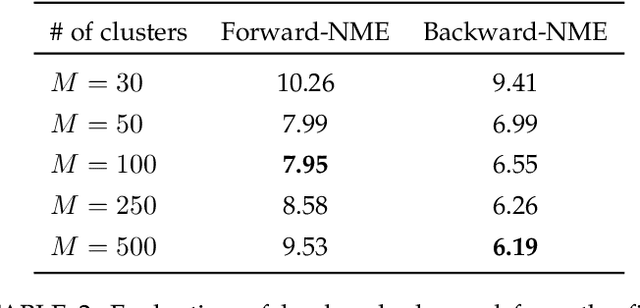
This paper proposes a novel paradigm for the unsupervised learning of object landmark detectors. Contrary to existing methods that build on auxiliary tasks such as image generation or equivariance, we propose a self-training approach where, departing from generic keypoints, a landmark detector and descriptor is trained to improve itself, tuning the keypoints into distinctive landmarks. To this end, we propose an iterative algorithm that alternates between producing new pseudo-labels through feature clustering and learning distinctive features for each pseudo-class through contrastive learning. With a shared backbone for the landmark detector and descriptor, the keypoint locations progressively converge to stable landmarks, filtering those less stable. Compared to previous works, our approach can learn points that are more flexible in terms of capturing large viewpoint changes. We validate our method on a variety of difficult datasets, including LS3D, BBCPose, Human3.6M and PennAction, achieving new state of the art results.
Subpixel Heatmap Regression for Facial Landmark Localization
Nov 03, 2021



Deep Learning models based on heatmap regression have revolutionized the task of facial landmark localization with existing models working robustly under large poses, non-uniform illumination and shadows, occlusions and self-occlusions, low resolution and blur. However, despite their wide adoption, heatmap regression approaches suffer from discretization-induced errors related to both the heatmap encoding and decoding process. In this work we show that these errors have a surprisingly large negative impact on facial alignment accuracy. To alleviate this problem, we propose a new approach for the heatmap encoding and decoding process by leveraging the underlying continuous distribution. To take full advantage of the newly proposed encoding-decoding mechanism, we also introduce a Siamese-based training that enforces heatmap consistency across various geometric image transformations. Our approach offers noticeable gains across multiple datasets setting a new state-of-the-art result in facial landmark localization. Code alongside the pretrained models will be made available at https://www.adrianbulat.com/face-alignment
Pre-training strategies and datasets for facial representation learning
Mar 30, 2021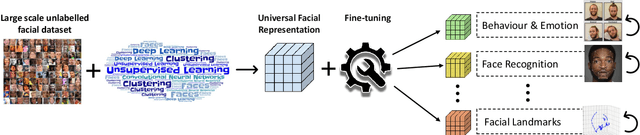
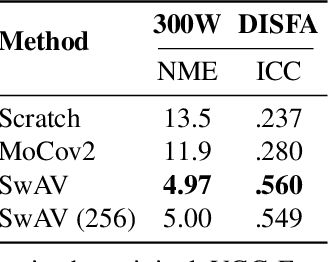
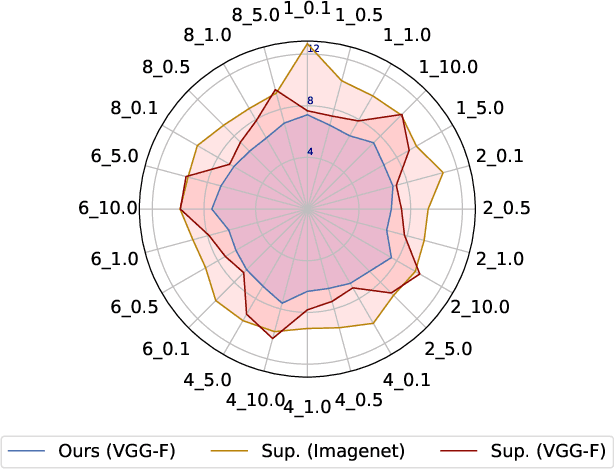
What is the best way to learn a universal face representation? Recent work on Deep Learning in the area of face analysis has focused on supervised learning for specific tasks of interest (e.g. face recognition, facial landmark localization etc.) but has overlooked the overarching question of how to find a facial representation that can be readily adapted to several facial analysis tasks and datasets. To this end, we make the following 4 contributions: (a) we introduce, for the first time, a comprehensive evaluation benchmark for facial representation learning consisting of 5 important face analysis tasks. (b) We systematically investigate two ways of large-scale representation learning applied to faces: supervised and unsupervised pre-training. Importantly, we focus our evaluations on the case of few-shot facial learning. (c) We investigate important properties of the training datasets including their size and quality (labelled, unlabelled or even uncurated). (d) To draw our conclusions, we conducted a very large number of experiments. Our main two findings are: (1) Unsupervised pre-training on completely in-the-wild, uncurated data provides consistent and, in some cases, significant accuracy improvements for all facial tasks considered. (2) Many existing facial video datasets seem to have a large amount of redundancy. We will release code, pre-trained models and data to facilitate future research.
Affective Processes: stochastic modelling of temporal context for emotion and facial expression recognition
Mar 24, 2021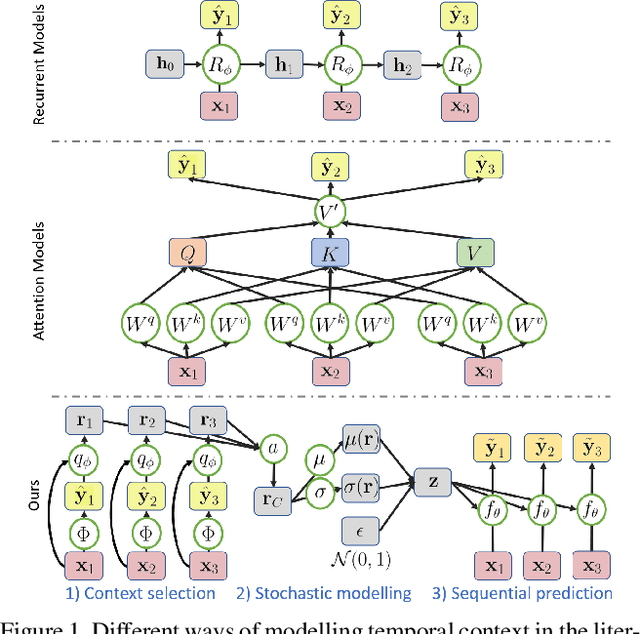
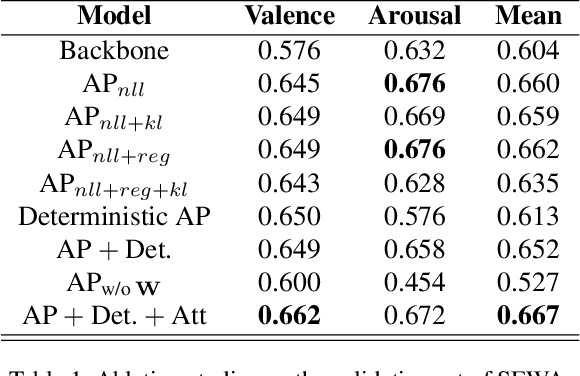
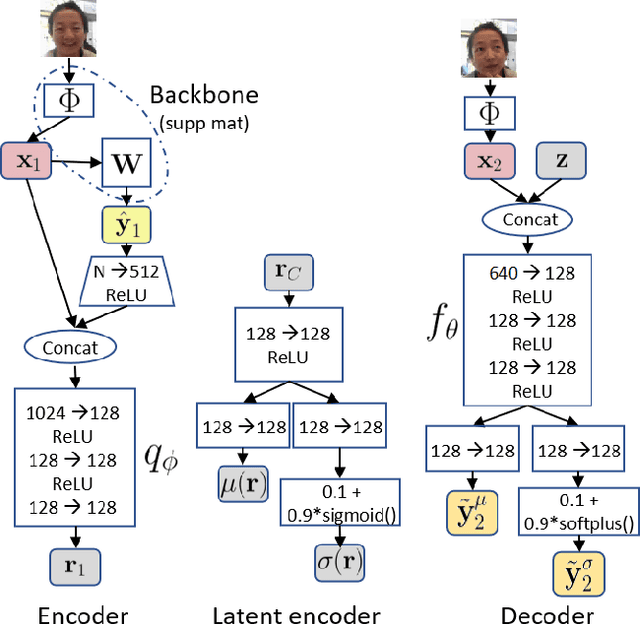

Temporal context is key to the recognition of expressions of emotion. Existing methods, that rely on recurrent or self-attention models to enforce temporal consistency, work on the feature level, ignoring the task-specific temporal dependencies, and fail to model context uncertainty. To alleviate these issues, we build upon the framework of Neural Processes to propose a method for apparent emotion recognition with three key novel components: (a) probabilistic contextual representation with a global latent variable model; (b) temporal context modelling using task-specific predictions in addition to features; and (c) smart temporal context selection. We validate our approach on four databases, two for Valence and Arousal estimation (SEWA and AffWild2), and two for Action Unit intensity estimation (DISFA and BP4D). Results show a consistent improvement over a series of strong baselines as well as over state-of-the-art methods.
Semi-supervised Facial Action Unit Intensity Estimation with Contrastive Learning
Nov 04, 2020


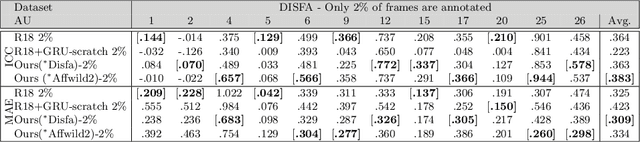
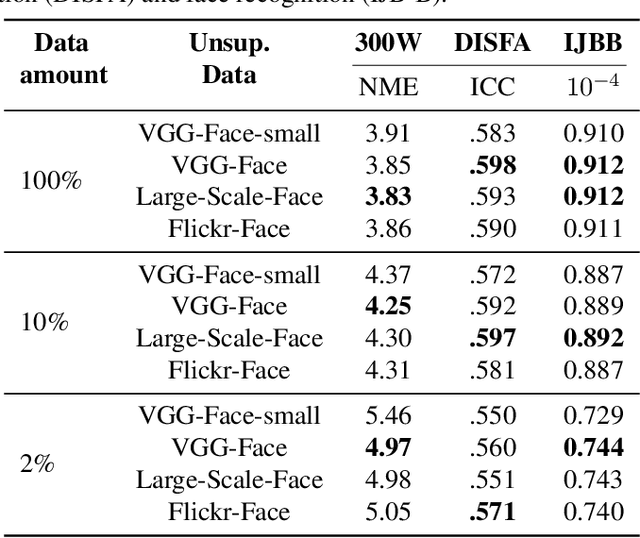
This paper tackles the challenging problem of estimating the intensity of Facial Action Units with few labeled images. Contrary to previous works, our method does not require to manually select key frames, and produces state-of-the-art results with as little as $2\%$ of annotated frames, which are \textit{randomly chosen}. To this end, we propose a semi-supervised learning approach where a spatio-temporal model combining a feature extractor and a temporal module are learned in two stages. The first stage uses datasets of unlabeled videos to learn a strong spatio-temporal representation of facial behavior dynamics based on contrastive learning. To our knowledge we are the first to build upon this framework for modeling facial behavior in an unsupervised manner. The second stage uses another dataset of randomly chosen labeled frames to train a regressor on top of our spatio-temporal model for estimating the AU intensity. We show that although backpropagation through time is applied only with respect to the output of the network for extremely sparse and randomly chosen labeled frames, our model can be effectively trained to estimate AU intensity accurately, thanks to the unsupervised pre-training of the first stage. We experimentally validate that our method outperforms existing methods when working with as little as $2\%$ of randomly chosen data for both DISFA and BP4D datasets, without a careful choice of labeled frames, a time-consuming task still required in previous approaches.