 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREST: REtrieve & Self-Train for generative action recognition
Paper and Code
Sep 29, 2022

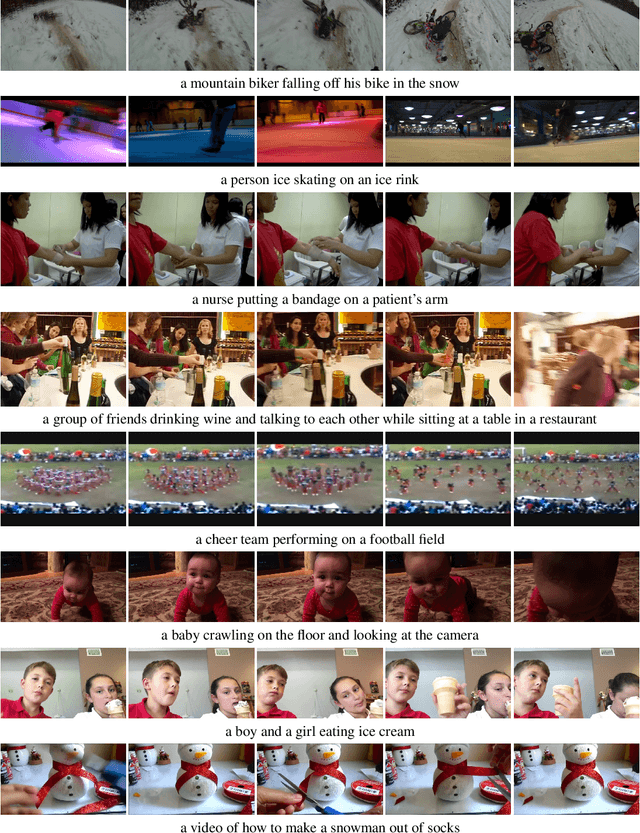
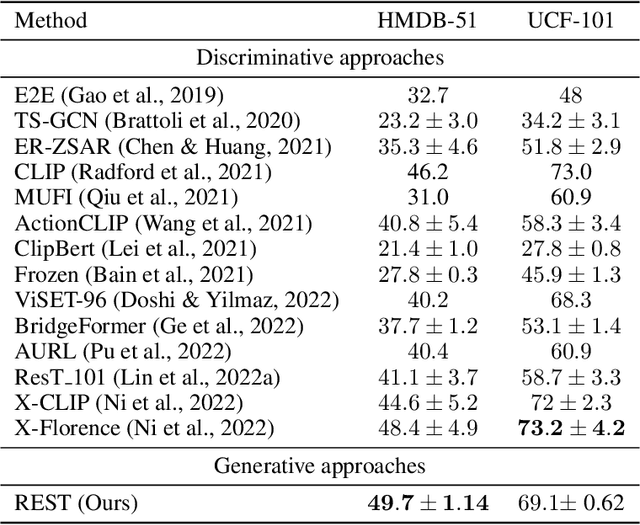
This work is on training a generative action/video recognition model whose output is a free-form action-specific caption describing the video (rather than an action class label). A generative approach has practical advantages like producing more fine-grained and human-readable output, and being naturally open-world. To this end, we propose to adapt a pre-trained generative Vision & Language (V&L) Foundation Model for video/action recognition. While recently there have been a few attempts to adapt V&L models trained with contrastive learning (e.g. CLIP) for video/action, to the best of our knowledge, we propose the very first method that sets outs to accomplish this goal for a generative model. We firstly show that direct fine-tuning of a generative model to produce action classes suffers from severe overfitting. To alleviate this, we introduce REST, a training framework consisting of two key components: an unsupervised method for adapting the generative model to action/video by means of pseudo-caption generation and Self-training, i.e. without using any action-specific labels; (b) a Retrieval approach based on CLIP for discovering a diverse set of pseudo-captions for each video to train the model. Importantly, we show that both components are necessary to obtain high accuracy. We evaluate REST on the problem of zero-shot action recognition where we show that our approach is very competitive when compared to contrastive learning-based methods. Code will be made available.