 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeMSVD: Long-Range Temporal Structure Capturing Using Incremental SVD
Jun 11, 2024



This paper is on long-term video understanding where the goal is to recognise human actions over long temporal windows (up to minutes long). In prior work, long temporal context is captured by constructing a long-term memory bank consisting of past and future video features which are then integrated into standard (short-term) video recognition backbones through the use of attention mechanisms. Two well-known problems related to this approach are the quadratic complexity of the attention operation and the fact that the whole feature bank must be stored in memory for inference. To address both issues, we propose an alternative to attention-based schemes which is based on a low-rank approximation of the memory obtained using Singular Value Decomposition. Our scheme has two advantages: (a) it reduces complexity by more than an order of magnitude, and (b) it is amenable to an efficient implementation for the calculation of the memory bases in an incremental fashion which does not require the storage of the whole feature bank in memory. The proposed scheme matches or surpasses the accuracy achieved by attention-based mechanisms while being memory-efficient. Through extensive experiments, we demonstrate that our framework generalises to different architectures and tasks, outperforming the state-of-the-art in three datasets.
VLLMs Provide Better Context for Emotion Understanding Through Common Sense Reasoning
Apr 10, 2024



Recognising emotions in context involves identifying the apparent emotions of an individual, taking into account contextual cues from the surrounding scene. Previous approaches to this task have involved the design of explicit scene-encoding architectures or the incorporation of external scene-related information, such as captions. However, these methods often utilise limited contextual information or rely on intricate training pipelines. In this work, we leverage the groundbreaking capabilities of Vision-and-Large-Language Models (VLLMs) to enhance in-context emotion classification without introducing complexity to the training process in a two-stage approach. In the first stage, we propose prompting VLLMs to generate descriptions in natural language of the subject's apparent emotion relative to the visual context. In the second stage, the descriptions are used as contextual information and, along with the image input, are used to train a transformer-based architecture that fuses text and visual features before the final classification task. Our experimental results show that the text and image features have complementary information, and our fused architecture significantly outperforms the individual modalities without any complex training methods. We evaluate our approach on three different datasets, namely, EMOTIC, CAER-S, and BoLD, and achieve state-of-the-art or comparable accuracy across all datasets and metrics compared to much more complex approaches. The code will be made publicly available on github: https://github.com/NickyFot/EmoCommonSense.git
Multiscale Vision Transformers meet Bipartite Matching for efficient single-stage Action Localization
Dec 29, 2023



Action Localization is a challenging problem that combines detection and recognition tasks, which are often addressed separately. State-of-the-art methods rely on off-the-shelf bounding box detections pre-computed at high resolution and propose transformer models that focus on the classification task alone. Such two-stage solutions are prohibitive for real-time deployment. On the other hand, single-stage methods target both tasks by devoting part of the network (generally the backbone) to sharing the majority of the workload, compromising performance for speed. These methods build on adding a DETR head with learnable queries that, after cross- and self-attention can be sent to corresponding MLPs for detecting a person's bounding box and action. However, DETR-like architectures are challenging to train and can incur in big complexity. In this paper, we observe that a straight bipartite matching loss can be applied to the output tokens of a vision transformer. This results in a backbone + MLP architecture that can do both tasks without the need of an extra encoder-decoder head and learnable queries. We show that a single MViT-S architecture trained with bipartite matching to perform both tasks surpasses the same MViT-S when trained with RoI align on pre-computed bounding boxes. With a careful design of token pooling and the proposed training pipeline, our MViTv2-S model achieves +3 mAP on AVA2.2. w.r.t. the two-stage counterpart. Code and models will be released after paper revision.
A Transfer Learning approach to Heatmap Regression for Action Unit intensity estimation
Apr 14, 2020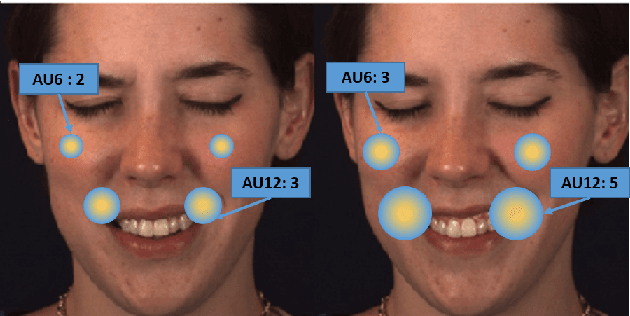
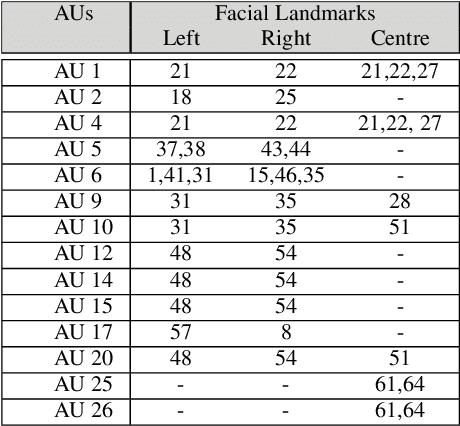
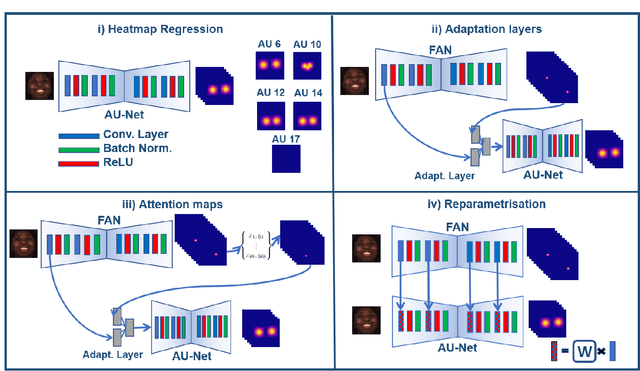
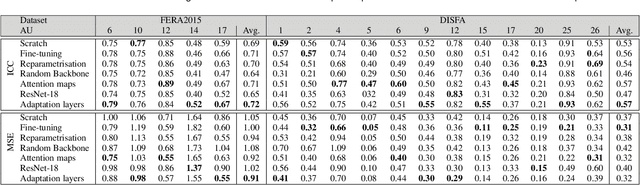
Action Units (AUs) are geometrically-based atomic facial muscle movements known to produce appearance changes at specific facial locations. Motivated by this observation we propose a novel AU modelling problem that consists of jointly estimating their localisation and intensity. To this end, we propose a simple yet efficient approach based on Heatmap Regression that merges both problems into a single task. A Heatmap models whether an AU occurs or not at a given spatial location. To accommodate the joint modelling of AUs intensity, we propose variable size heatmaps, with their amplitude and size varying according to the labelled intensity. Using Heatmap Regression, we can inherit from the progress recently witnessed in facial landmark localisation. Building upon the similarities between both problems, we devise a transfer learning approach where we exploit the knowledge of a network trained on large-scale facial landmark datasets. In particular, we explore different alternatives for transfer learning through a) fine-tuning, b) adaptation layers, c) attention maps, and d) reparametrisation. Our approach effectively inherits the rich facial features produced by a strong face alignment network, with minimal extra computational cost. We empirically validate that our system sets a new state-of-the-art on three popular datasets, namely BP4D, DISFA, and FERA2017.
Attention-Aware Generative Adversarial Networks (ATA-GANs)
Feb 25, 2018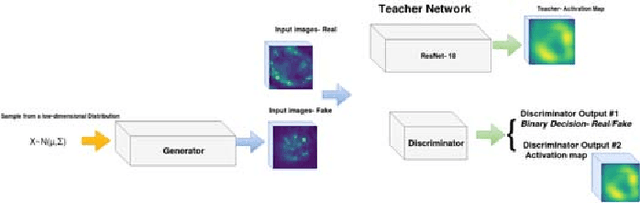
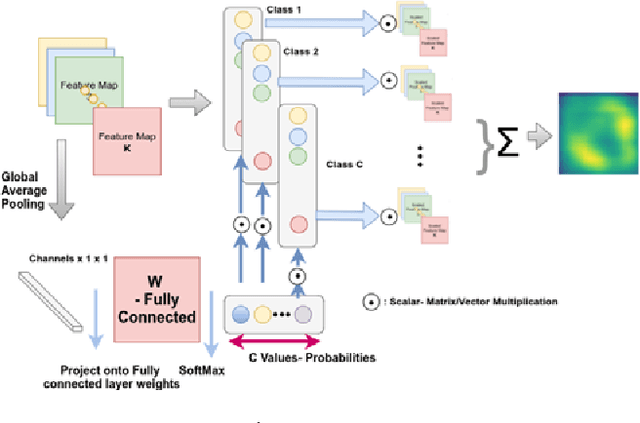
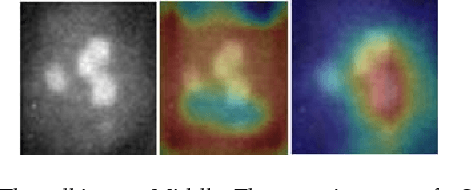
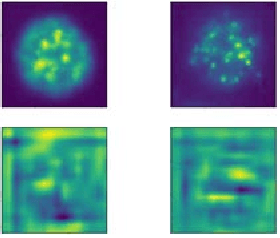
In this work, we present a novel approach for training Generative Adversarial Networks (GANs). Using the attention maps produced by a Teacher- Network we are able to improve the quality of the generated images as well as perform weakly object localization on the generated images. To this end, we generate images of HEp-2 cells captured with Indirect Imunofluoresence (IIF) and study the ability of our network to perform a weakly localization of the cell. Firstly, we demonstrate that whilst GANs can learn the mapping between the input domain and the target distribution efficiently, the discriminator network is not able to detect the regions of interest. Secondly, we present a novel attention transfer mechanism which allows us to enforce the discriminator to put emphasis on the regions of interest via transfer learning. Thirdly, we show that this leads to more realistic images, as the discriminator learns to put emphasis on the area of interest. Fourthly, the proposed method allows one to generate both images as well as attention maps which can be useful for data annotation e.g in object detection.