 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAD-Assistant: Tool-Augmented VLLMs as Generic CAD Task Solvers?
Dec 18, 2024We propose CAD-Assistant, a general-purpose CAD agent for AI-assisted design. Our approach is based on a powerful Vision and Large Language Model (VLLM) as a planner and a tool-augmentation paradigm using CAD-specific modules. CAD-Assistant addresses multimodal user queries by generating actions that are iteratively executed on a Python interpreter equipped with the FreeCAD software, accessed via its Python API. Our framework is able to assess the impact of generated CAD commands on geometry and adapts subsequent actions based on the evolving state of the CAD design. We consider a wide range of CAD-specific tools including Python libraries, modules of the FreeCAD Python API, helpful routines, rendering functions and other specialized modules. We evaluate our method on multiple CAD benchmarks and qualitatively demonstrate the potential of tool-augmented VLLMs as generic CAD task solvers across diverse CAD workflows.
CAD-Recode: Reverse Engineering CAD Code from Point Clouds
Dec 18, 2024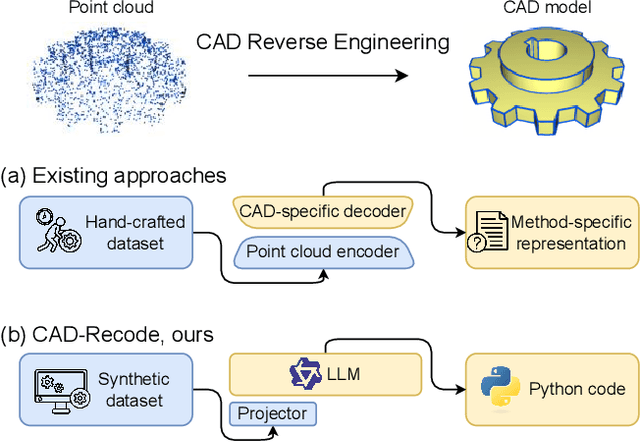
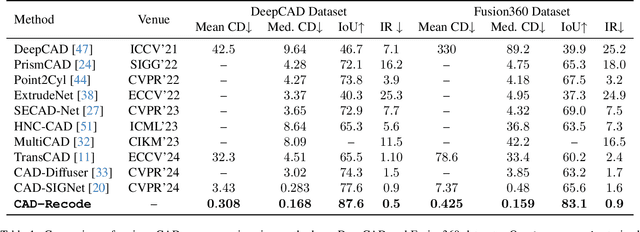

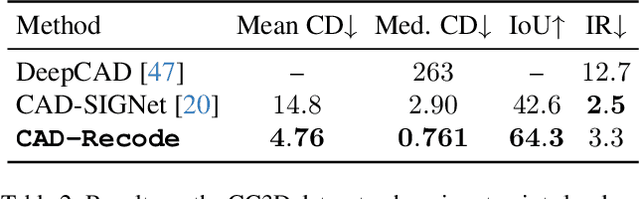
Computer-Aided Design (CAD) models are typically constructed by sequentially drawing parametric sketches and applying CAD operations to obtain a 3D model. The problem of 3D CAD reverse engineering consists of reconstructing the sketch and CAD operation sequences from 3D representations such as point clouds. In this paper, we address this challenge through novel contributions across three levels: CAD sequence representation, network design, and dataset. In particular, we represent CAD sketch-extrude sequences as Python code. The proposed CAD-Recode translates a point cloud into Python code that, when executed, reconstructs the CAD model. Taking advantage of the exposure of pre-trained Large Language Models (LLMs) to Python code, we leverage a relatively small LLM as a decoder for CAD-Recode and combine it with a lightweight point cloud projector. CAD-Recode is trained solely on a proposed synthetic dataset of one million diverse CAD sequences. CAD-Recode significantly outperforms existing methods across three datasets while requiring fewer input points. Notably, it achieves 10 times lower mean Chamfer distance than state-of-the-art methods on DeepCAD and Fusion360 datasets. Furthermore, we show that our CAD Python code output is interpretable by off-the-shelf LLMs, enabling CAD editing and CAD-specific question answering from point clouds.
DAVINCI: A Single-Stage Architecture for Constrained CAD Sketch Inference
Oct 30, 2024This work presents DAVINCI, a unified architecture for single-stage Computer-Aided Design (CAD) sketch parameterization and constraint inference directly from raster sketch images. By jointly learning both outputs, DAVINCI minimizes error accumulation and enhances the performance of constrained CAD sketch inference. Notably, DAVINCI achieves state-of-the-art results on the large-scale SketchGraphs dataset, demonstrating effectiveness on both precise and hand-drawn raster CAD sketches. To reduce DAVINCI's reliance on large-scale annotated datasets, we explore the efficacy of CAD sketch augmentations. We introduce Constraint-Preserving Transformations (CPTs), i.e. random permutations of the parametric primitives of a CAD sketch that preserve its constraints. This data augmentation strategy allows DAVINCI to achieve reasonable performance when trained with only 0.1% of the SketchGraphs dataset. Furthermore, this work contributes a new version of SketchGraphs, augmented with CPTs. The newly introduced CPTSketchGraphs dataset includes 80 million CPT-augmented sketches, thus providing a rich resource for future research in the CAD sketch domain.
TransCAD: A Hierarchical Transformer for CAD Sequence Inference from Point Clouds
Jul 18, 20243D reverse engineering, in which a CAD model is inferred given a 3D scan of a physical object, is a research direction that offers many promising practical applications. This paper proposes TransCAD, an end-to-end transformer-based architecture that predicts the CAD sequence from a point cloud. TransCAD leverages the structure of CAD sequences by using a hierarchical learning strategy. A loop refiner is also introduced to regress sketch primitive parameters. Rigorous experimentation on the DeepCAD and Fusion360 datasets show that TransCAD achieves state-of-the-art results. The result analysis is supported with a proposed metric for CAD sequence, the mean Average Precision of CAD Sequence, that addresses the limitations of existing metrics.
PICASSO: A Feed-Forward Framework for Parametric Inference of CAD Sketches via Rendering Self-Supervision
Jul 18, 2024We propose PICASSO, a novel framework CAD sketch parameterization from hand-drawn or precise sketch images via rendering self-supervision. Given a drawing of a CAD sketch, the proposed framework turns it into parametric primitives that can be imported into CAD software. Compared to existing methods, PICASSO enables the learning of parametric CAD sketches from either precise or hand-drawn sketch images, even in cases where annotations at the parameter level are scarce or unavailable. This is achieved by leveraging the geometric characteristics of sketches as a learning cue to pre-train a CAD parameterization network. Specifically, PICASSO comprises two primary components: (1) a Sketch Parameterization Network (SPN) that predicts a series of parametric primitives from CAD sketch images, and (2) a Sketch Rendering Network (SRN) that renders parametric CAD sketches in a differentiable manner. SRN facilitates the computation of a image-to-image loss, which can be utilized to pre-train SPN, thereby enabling zero- and few-shot learning scenarios for the parameterization of hand-drawn sketches. Extensive evaluation on the widely used SketchGraphs dataset validates the effectiveness of the proposed framework.
Self-Supervised Learning for Visual Relationship Detection through Masked Bounding Box Reconstruction
Nov 08, 2023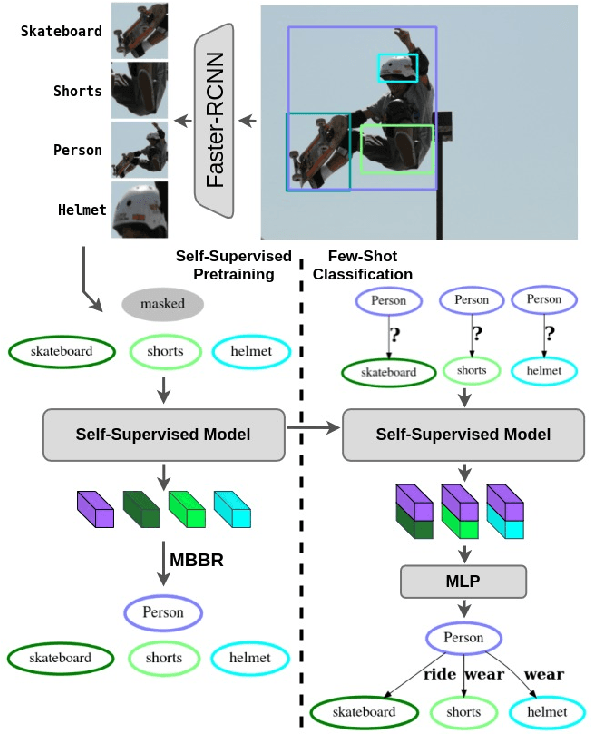
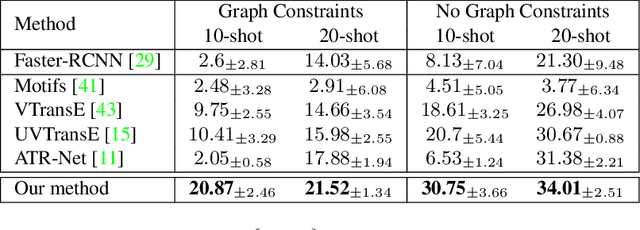
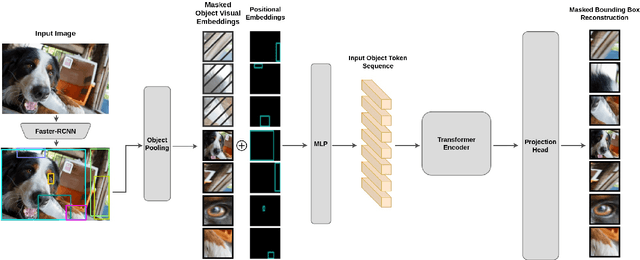
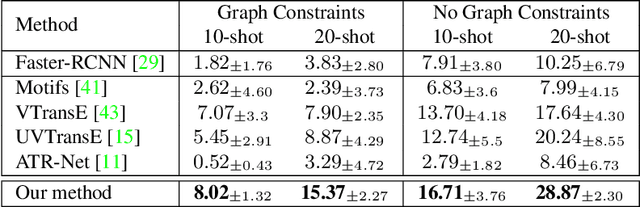
We present a novel self-supervised approach for representation learning, particularly for the task of Visual Relationship Detection (VRD). Motivated by the effectiveness of Masked Image Modeling (MIM), we propose Masked Bounding Box Reconstruction (MBBR), a variation of MIM where a percentage of the entities/objects within a scene are masked and subsequently reconstructed based on the unmasked objects. The core idea is that, through object-level masked modeling, the network learns context-aware representations that capture the interaction of objects within a scene and thus are highly predictive of visual object relationships. We extensively evaluate learned representations, both qualitatively and quantitatively, in a few-shot setting and demonstrate the efficacy of MBBR for learning robust visual representations, particularly tailored for VRD. The proposed method is able to surpass state-of-the-art VRD methods on the Predicate Detection (PredDet) evaluation setting, using only a few annotated samples. We make our code available at https://github.com/deeplab-ai/SelfSupervisedVRD.
Interpretable Visual Question Answering via Reasoning Supervision
Sep 07, 2023Transformer-based architectures have recently demonstrated remarkable performance in the Visual Question Answering (VQA) task. However, such models are likely to disregard crucial visual cues and often rely on multimodal shortcuts and inherent biases of the language modality to predict the correct answer, a phenomenon commonly referred to as lack of visual grounding. In this work, we alleviate this shortcoming through a novel architecture for visual question answering that leverages common sense reasoning as a supervisory signal. Reasoning supervision takes the form of a textual justification of the correct answer, with such annotations being already available on large-scale Visual Common Sense Reasoning (VCR) datasets. The model's visual attention is guided toward important elements of the scene through a similarity loss that aligns the learned attention distributions guided by the question and the correct reasoning. We demonstrate both quantitatively and qualitatively that the proposed approach can boost the model's visual perception capability and lead to performance increase, without requiring training on explicit grounding annotations.
SHARP Challenge 2023: Solving CAD History and pArameters Recovery from Point clouds and 3D scans. Overview, Datasets, Metrics, and Baselines
Aug 30, 2023



Recent breakthroughs in geometric Deep Learning (DL) and the availability of large Computer-Aided Design (CAD) datasets have advanced the research on learning CAD modeling processes and relating them to real objects. In this context, 3D reverse engineering of CAD models from 3D scans is considered to be one of the most sought-after goals for the CAD industry. However, recent efforts assume multiple simplifications limiting the applications in real-world settings. The SHARP Challenge 2023 aims at pushing the research a step closer to the real-world scenario of CAD reverse engineering through dedicated datasets and tracks. In this paper, we define the proposed SHARP 2023 tracks, describe the provided datasets, and propose a set of baseline methods along with suitable evaluation metrics to assess the performance of the track solutions. All proposed datasets along with useful routines and the evaluation metrics are publicly available.
An Incremental Learning framework for Large-scale CTR Prediction
Sep 01, 2022
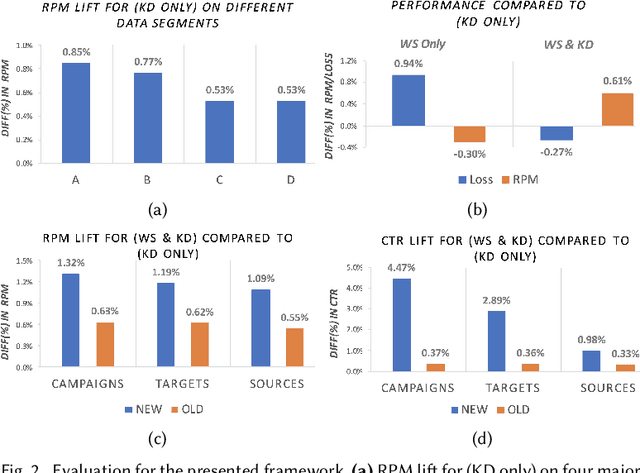
In this work we introduce an incremental learning framework for Click-Through-Rate (CTR) prediction and demonstrate its effectiveness for Taboola's massive-scale recommendation service. Our approach enables rapid capture of emerging trends through warm-starting from previously deployed models and fine tuning on "fresh" data only. Past knowledge is maintained via a teacher-student paradigm, where the teacher acts as a distillation technique, mitigating the catastrophic forgetting phenomenon. Our incremental learning framework enables significantly faster training and deployment cycles (x12 speedup). We demonstrate a consistent Revenue Per Mille (RPM) lift over multiple traffic segments and a significant CTR increase on newly introduced items.
From Keypoints to Object Landmarks via Self-Training Correspondence: A novel approach to Unsupervised Landmark Discovery
May 31, 2022
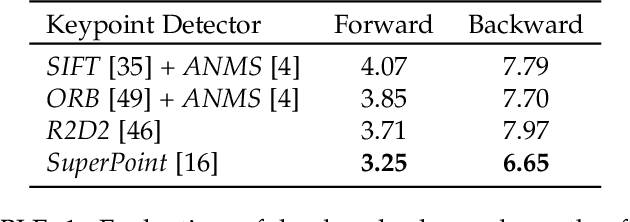
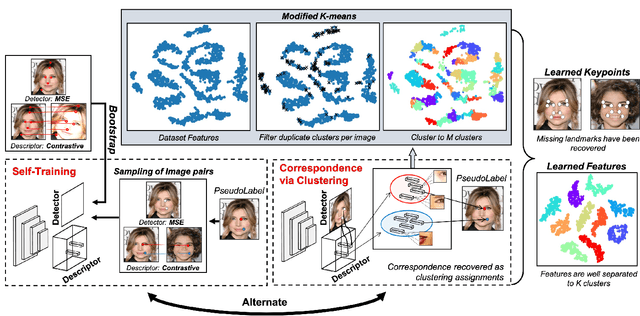
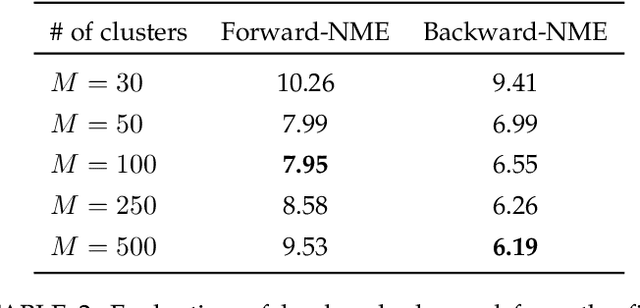
This paper proposes a novel paradigm for the unsupervised learning of object landmark detectors. Contrary to existing methods that build on auxiliary tasks such as image generation or equivariance, we propose a self-training approach where, departing from generic keypoints, a landmark detector and descriptor is trained to improve itself, tuning the keypoints into distinctive landmarks. To this end, we propose an iterative algorithm that alternates between producing new pseudo-labels through feature clustering and learning distinctive features for each pseudo-class through contrastive learning. With a shared backbone for the landmark detector and descriptor, the keypoint locations progressively converge to stable landmarks, filtering those less stable. Compared to previous works, our approach can learn points that are more flexible in terms of capturing large viewpoint changes. We validate our method on a variety of difficult datasets, including LS3D, BBCPose, Human3.6M and PennAction, achieving new state of the art results.