 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelVAE: Generative Pretraining for few-shot Visual Relationship Detection
Nov 27, 2023Visual relations are complex, multimodal concepts that play an important role in the way humans perceive the world. As a result of their complexity, high-quality, diverse and large scale datasets for visual relations are still absent. In an attempt to overcome this data barrier, we choose to focus on the problem of few-shot Visual Relationship Detection (VRD), a setting that has been so far neglected by the community. In this work we present the first pretraining method for few-shot predicate classification that does not require any annotated relations. We achieve this by introducing a generative model that is able to capture the variation of semantic, visual and spatial information of relations inside a latent space and later exploiting its representations in order to achieve efficient few-shot classification. We construct few-shot training splits and show quantitative experiments on VG200 and VRD datasets where our model outperforms the baselines. Lastly we attempt to interpret the decisions of the model by conducting various qualitative experiments.
Self-Supervised Learning for Visual Relationship Detection through Masked Bounding Box Reconstruction
Nov 08, 2023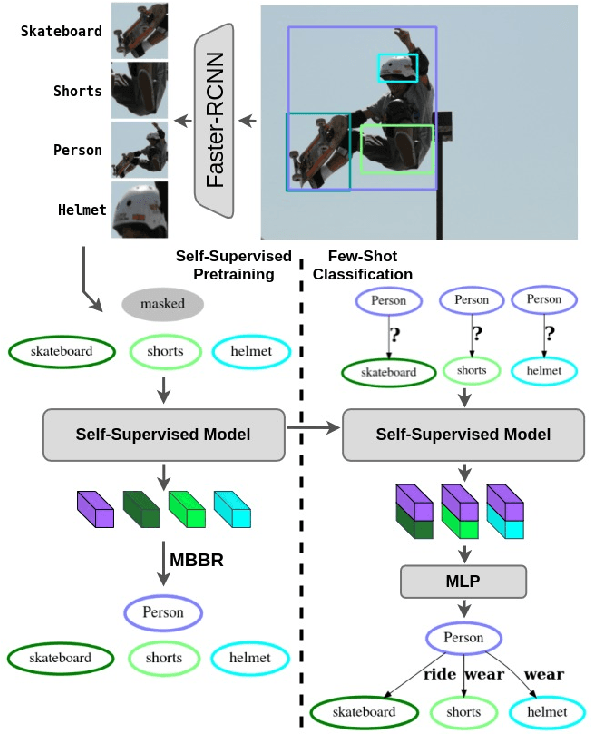
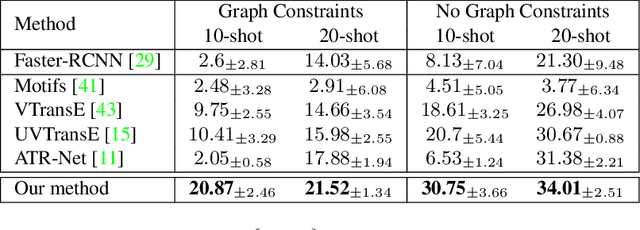
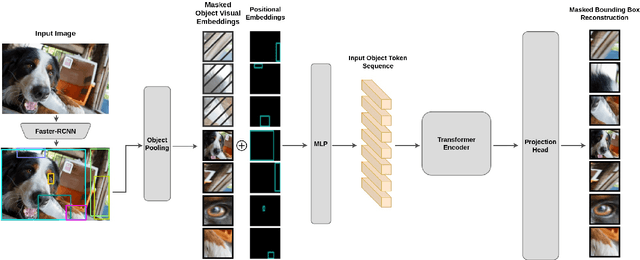
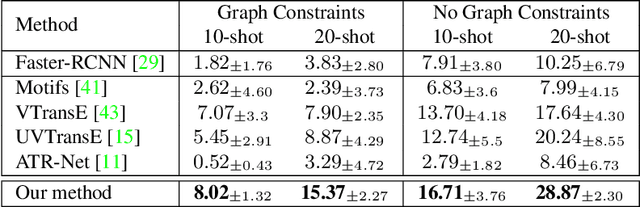
We present a novel self-supervised approach for representation learning, particularly for the task of Visual Relationship Detection (VRD). Motivated by the effectiveness of Masked Image Modeling (MIM), we propose Masked Bounding Box Reconstruction (MBBR), a variation of MIM where a percentage of the entities/objects within a scene are masked and subsequently reconstructed based on the unmasked objects. The core idea is that, through object-level masked modeling, the network learns context-aware representations that capture the interaction of objects within a scene and thus are highly predictive of visual object relationships. We extensively evaluate learned representations, both qualitatively and quantitatively, in a few-shot setting and demonstrate the efficacy of MBBR for learning robust visual representations, particularly tailored for VRD. The proposed method is able to surpass state-of-the-art VRD methods on the Predicate Detection (PredDet) evaluation setting, using only a few annotated samples. We make our code available at https://github.com/deeplab-ai/SelfSupervisedVRD.
Interpretable Visual Question Answering via Reasoning Supervision
Sep 07, 2023Transformer-based architectures have recently demonstrated remarkable performance in the Visual Question Answering (VQA) task. However, such models are likely to disregard crucial visual cues and often rely on multimodal shortcuts and inherent biases of the language modality to predict the correct answer, a phenomenon commonly referred to as lack of visual grounding. In this work, we alleviate this shortcoming through a novel architecture for visual question answering that leverages common sense reasoning as a supervisory signal. Reasoning supervision takes the form of a textual justification of the correct answer, with such annotations being already available on large-scale Visual Common Sense Reasoning (VCR) datasets. The model's visual attention is guided toward important elements of the scene through a similarity loss that aligns the learned attention distributions guided by the question and the correct reasoning. We demonstrate both quantitatively and qualitatively that the proposed approach can boost the model's visual perception capability and lead to performance increase, without requiring training on explicit grounding annotations.
An Incremental Learning framework for Large-scale CTR Prediction
Sep 01, 2022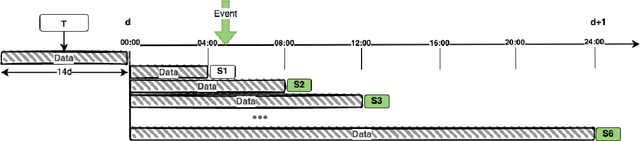
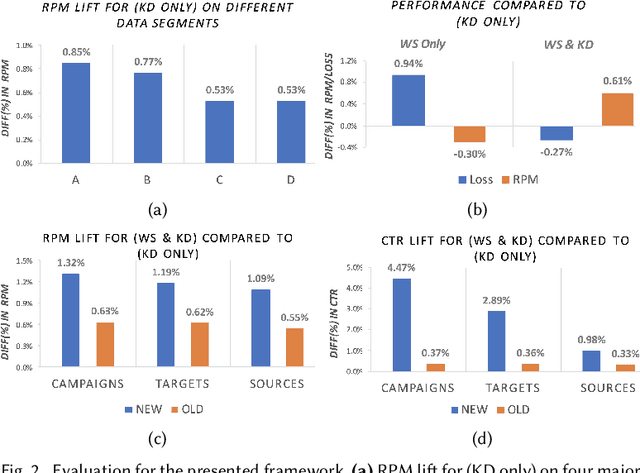
In this work we introduce an incremental learning framework for Click-Through-Rate (CTR) prediction and demonstrate its effectiveness for Taboola's massive-scale recommendation service. Our approach enables rapid capture of emerging trends through warm-starting from previously deployed models and fine tuning on "fresh" data only. Past knowledge is maintained via a teacher-student paradigm, where the teacher acts as a distillation technique, mitigating the catastrophic forgetting phenomenon. Our incremental learning framework enables significantly faster training and deployment cycles (x12 speedup). We demonstrate a consistent Revenue Per Mille (RPM) lift over multiple traffic segments and a significant CTR increase on newly introduced items.
Deeply Supervised Multimodal Attentional Translation Embeddings for Visual Relationship Detection
Feb 15, 2019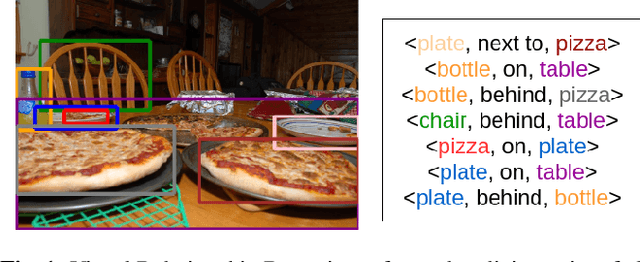
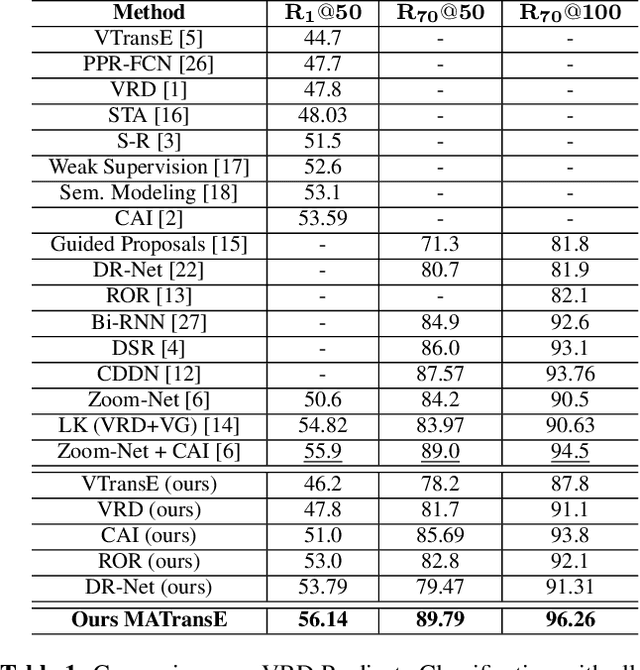
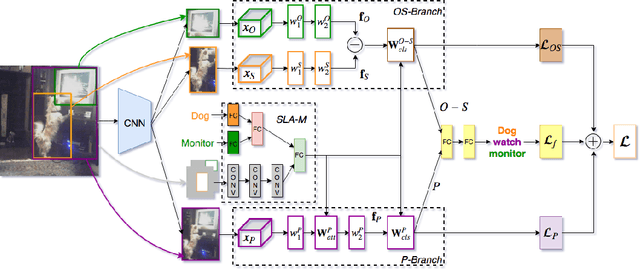
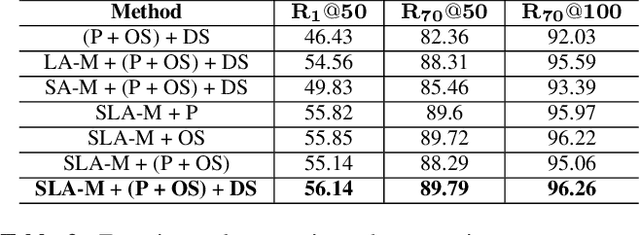
Detecting visual relationships, i.e. <Subject, Predicate, Object> triplets, is a challenging Scene Understanding task approached in the past via linguistic priors or spatial information in a single feature branch. We introduce a new deeply supervised two-branch architecture, the Multimodal Attentional Translation Embeddings, where the visual features of each branch are driven by a multimodal attentional mechanism that exploits spatio-linguistic similarities in a low-dimensional space. We present a variety of experiments comparing against all related approaches in the literature, as well as by re-implementing and fine-tuning several of them. Results on the commonly employed VRD dataset [1] show that the proposed method clearly outperforms all others, while we also justify our claims both quantitatively and qualitatively.