 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Affect to Complex Behavior: Advancing Multimodal Human-Centered AI at the 10th ABAW Workshop & Competition
May 24, 2026The 10th Affective & Behavior Analysis in-the-Wild (ABAW) Workshop and Competition, held at CVPR 2026, continues to advance research on modelling, analysis, understanding of human affect and behavior in real-world, unconstrained environments. The workshop maintains its dual structure, comprising both a competition and a paper track. The ABAW Competition introduces a diverse set of challenges targeting key aspects of affective and behavioral understanding, including continuous affect (valence-arousal) estimation, discrete affect (expression and action unit) recognition, as well as more complex behavior analysis tasks, such as emotional mimicry intensity estimation, ambivalence/hesitancy recognition and fine-grained violence detection. These challenges are built upon large-scale in-the-wild datasets, providing comprehensive benchmarks for state-of-the-art approaches. In parallel, the paper track presents a wide range of contributions spanning pose, motion & behavior estimation, affect modelling & multimodal learning, benchmarks, datasets & evaluation protocols, fairness, robustness & deployment. Overall, the 10th ABAW Workshop and Competition continues to serve as a key platform for benchmarking, collaboration and innovation, shaping the development of next-generation multimodal, human-centered AI systems.
7th ABAW Competition: Multi-Task Learning and Compound Expression Recognition
Jul 04, 2024



This paper describes the 7th Affective Behavior Analysis in-the-wild (ABAW) Competition, which is part of the respective Workshop held in conjunction with ECCV 2024. The 7th ABAW Competition addresses novel challenges in understanding human expressions and behaviors, crucial for the development of human-centered technologies. The Competition comprises of two sub-challenges: i) Multi-Task Learning (the goal is to learn at the same time, in a multi-task learning setting, to estimate two continuous affect dimensions, valence and arousal, to recognise between the mutually exclusive classes of the 7 basic expressions and 'other'), and to detect 12 Action Units); and ii) Compound Expression Recognition (the target is to recognise between the 7 mutually exclusive compound expression classes). s-Aff-Wild2, which is a static version of the A/V Aff-Wild2 database and contains annotations for valence-arousal, expressions and Action Units, is utilized for the purposes of the Multi-Task Learning Challenge; a part of C-EXPR-DB, which is an A/V in-the-wild database with compound expression annotations, is utilized for the purposes of the Compound Expression Recognition Challenge. In this paper, we introduce the two challenges, detailing their datasets and the protocols followed for each. We also outline the evaluation metrics, and highlight the baseline systems and their results. Additional information about the competition can be found at \url{https://affective-behavior-analysis-in-the-wild.github.io/7th}.
The 6th Affective Behavior Analysis in-the-wild Competition
Mar 12, 2024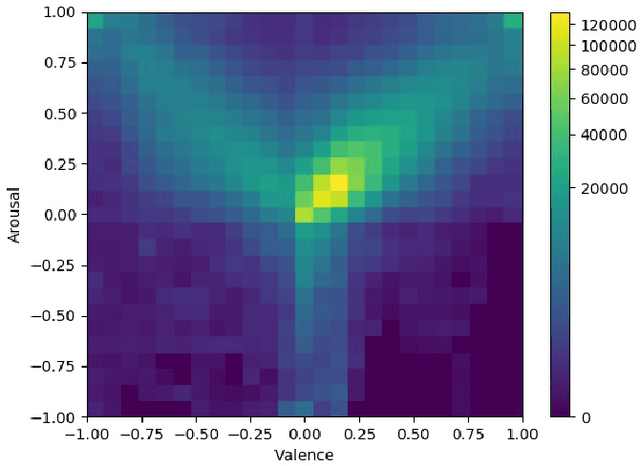
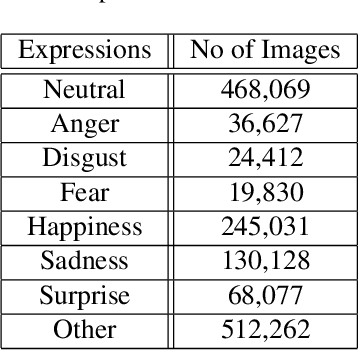
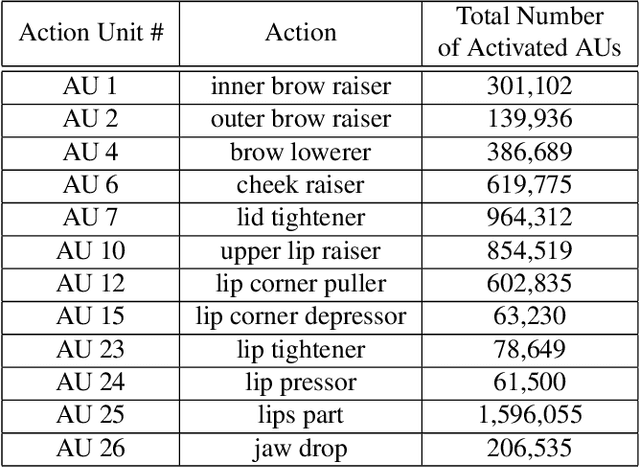
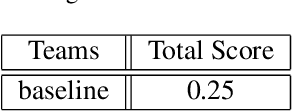
This paper describes the 6th Affective Behavior Analysis in-the-wild (ABAW) Competition, which is part of the respective Workshop held in conjunction with IEEE CVPR 2024. The 6th ABAW Competition addresses contemporary challenges in understanding human emotions and behaviors, crucial for the development of human-centered technologies. In more detail, the Competition focuses on affect related benchmarking tasks and comprises of five sub-challenges: i) Valence-Arousal Estimation (the target is to estimate two continuous affect dimensions, valence and arousal), ii) Expression Recognition (the target is to recognise between the mutually exclusive classes of the 7 basic expressions and 'other'), iii) Action Unit Detection (the target is to detect 12 action units), iv) Compound Expression Recognition (the target is to recognise between the 7 mutually exclusive compound expression classes), and v) Emotional Mimicry Intensity Estimation (the target is to estimate six continuous emotion dimensions). In the paper, we present these Challenges, describe their respective datasets and challenge protocols (we outline the evaluation metrics) and present the baseline systems as well as their obtained performance. More information for the Competition can be found in: https://affective-behavior-analysis-in-the-wild.github.io/6th.
Analysing Affective Behavior in the second ABAW2 Competition
Jul 03, 2021
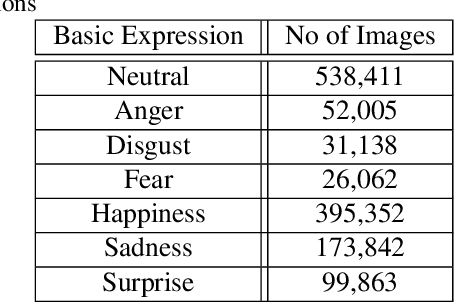
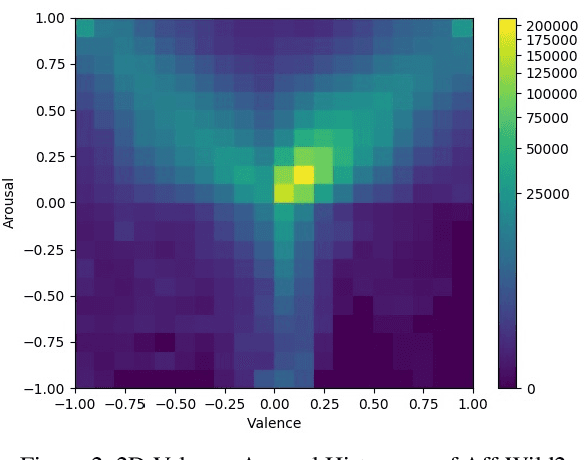
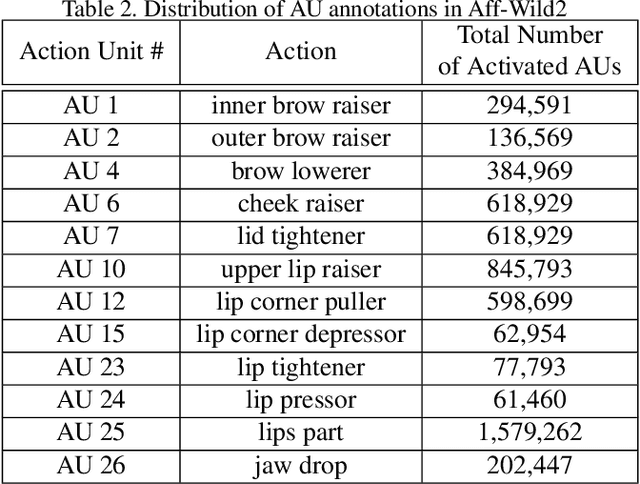
The Affective Behavior Analysis in-the-wild (ABAW2) 2021 Competition is the second -- following the first very successful ABAW Competition held in conjunction with IEEE FG 2020- Competition that aims at automatically analyzing affect. ABAW2 is split into three Challenges, each one addressing one of the three main behavior tasks of valence-arousal estimation, basic expression classification and action unit detection. All three Challenges are based on a common benchmark database, Aff-Wild2, which is a large scale in-the-wild database and the first one to be annotated for all these three tasks. In this paper, we describe this Competition, to be held in conjunction with ICCV 2021. We present the three Challenges, with the utilized Competition corpora. We outline the evaluation metrics and present the baseline system with its results. More information regarding the Competition is provided in the Competition site: https://ibug.doc.ic.ac.uk/resources/iccv-2021-2nd-abaw.
Fast-GANFIT: Generative Adversarial Network for High Fidelity 3D Face Reconstruction
May 16, 2021
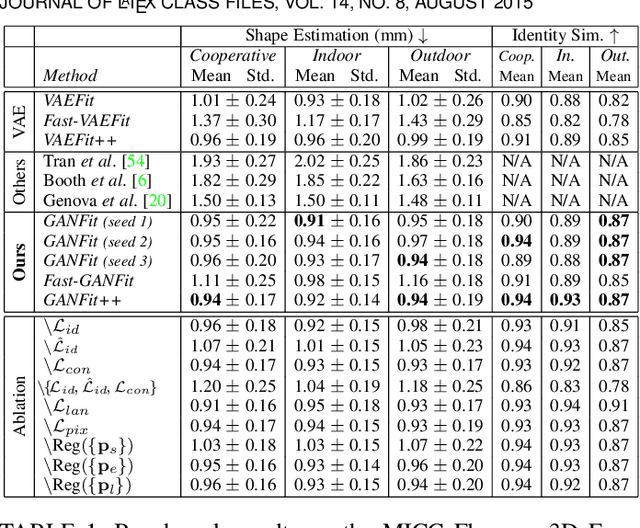
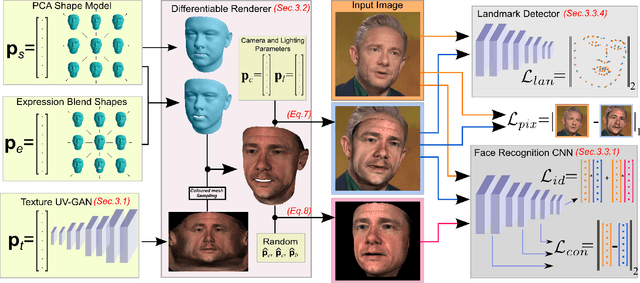
A lot of work has been done towards reconstructing the 3D facial structure from single images by capitalizing on the power of Deep Convolutional Neural Networks (DCNNs). In the recent works, the texture features either correspond to components of a linear texture space or are learned by auto-encoders directly from in-the-wild images. In all cases, the quality of the facial texture reconstruction is still not capable of modeling facial texture with high-frequency details. In this paper, we take a radically different approach and harness the power of Generative Adversarial Networks (GANs) and DCNNs in order to reconstruct the facial texture and shape from single images. That is, we utilize GANs to train a very powerful facial texture prior \edit{from a large-scale 3D texture dataset}. Then, we revisit the original 3D Morphable Models (3DMMs) fitting making use of non-linear optimization to find the optimal latent parameters that best reconstruct the test image but under a new perspective. In order to be robust towards initialisation and expedite the fitting process, we propose a novel self-supervised regression based approach. We demonstrate excellent results in photorealistic and identity preserving 3D face reconstructions and achieve for the first time, to the best of our knowledge, facial texture reconstruction with high-frequency details.
RetinaFace: Single-stage Dense Face Localisation in the Wild
May 04, 2019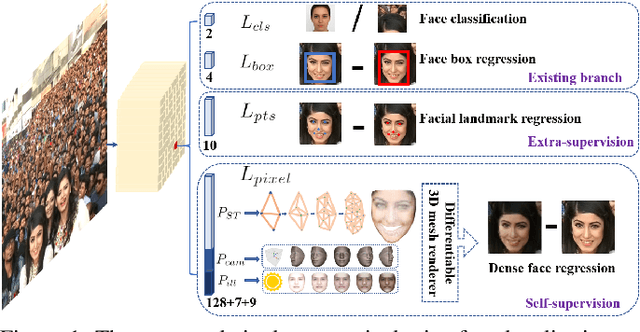

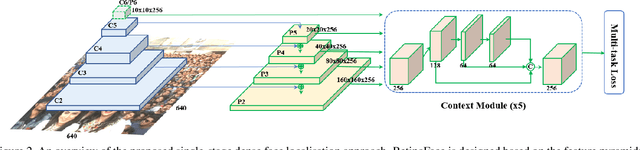

Though tremendous strides have been made in uncontrolled face detection, accurate and efficient face localisation in the wild remains an open challenge. This paper presents a robust single-stage face detector, named RetinaFace, which performs pixel-wise face localisation on various scales of faces by taking advantages of joint extra-supervised and self-supervised multi-task learning. Specifically, We make contributions in the following five aspects: (1) We manually annotate five facial landmarks on the WIDER FACE dataset and observe significant improvement in hard face detection with the assistance of this extra supervision signal. (2) We further add a self-supervised mesh decoder branch for predicting a pixel-wise 3D shape face information in parallel with the existing supervised branches. (3) On the WIDER FACE hard test set, RetinaFace outperforms the state of the art average precision (AP) by 1.1% (achieving AP equal to 91.4%). (4) On the IJB-C test set, RetinaFace enables state of the art methods (ArcFace) to improve their results in face verification (TAR=89.59% for FAR=1e-6). (5) By employing light-weight backbone networks, RetinaFace can run real-time on a single CPU core for a VGA-resolution image. Extra annotations and code have been made available at: https://github.com/deepinsight/insightface/tree/master/RetinaFace.
Dense 3D Face Decoding over 2500FPS: Joint Texture & Shape Convolutional Mesh Decoders
Apr 06, 2019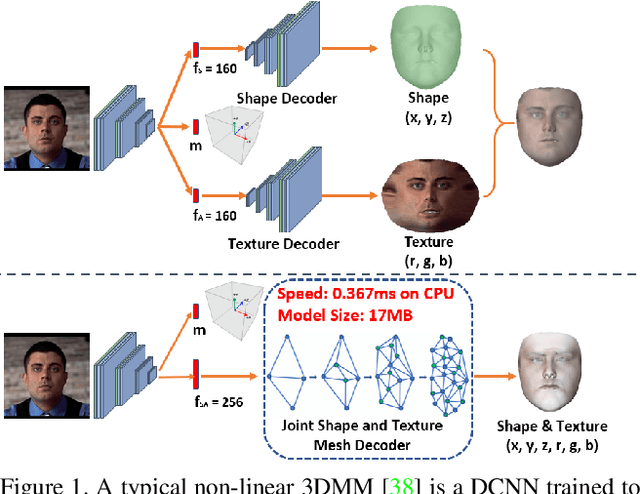
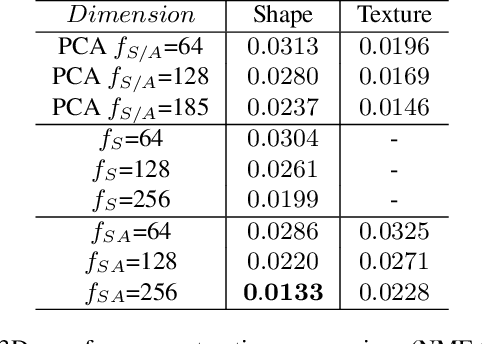
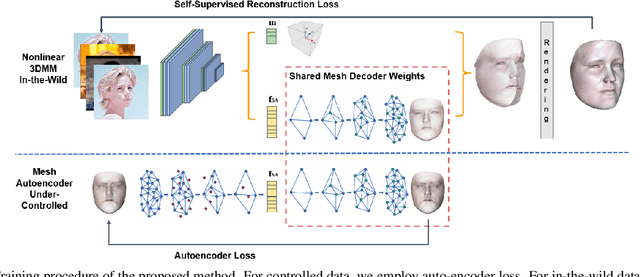

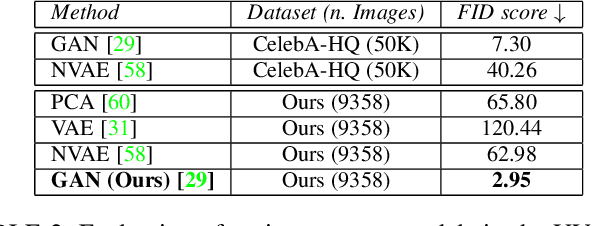
3D Morphable Models (3DMMs) are statistical models that represent facial texture and shape variations using a set of linear bases and more particular Principal Component Analysis (PCA). 3DMMs were used as statistical priors for reconstructing 3D faces from images by solving non-linear least square optimization problems. Recently, 3DMMs were used as generative models for training non-linear mappings (\ie, regressors) from image to the parameters of the models via Deep Convolutional Neural Networks (DCNNs). Nevertheless, all of the above methods use either fully connected layers or 2D convolutions on parametric unwrapped UV spaces leading to large networks with many parameters. In this paper, we present the first, to the best of our knowledge, non-linear 3DMMs by learning joint texture and shape auto-encoders using direct mesh convolutions. We demonstrate how these auto-encoders can be used to train very light-weight models that perform Coloured Mesh Decoding (CMD) in-the-wild at a speed of over 2500 FPS.
GANFIT: Generative Adversarial Network Fitting for High Fidelity 3D Face Reconstruction
Apr 06, 2019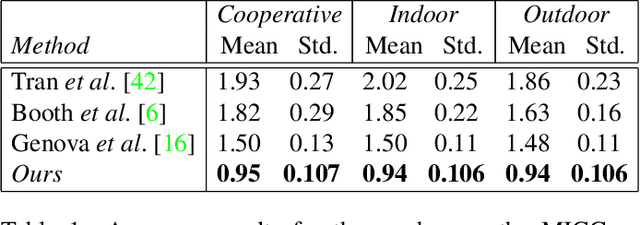
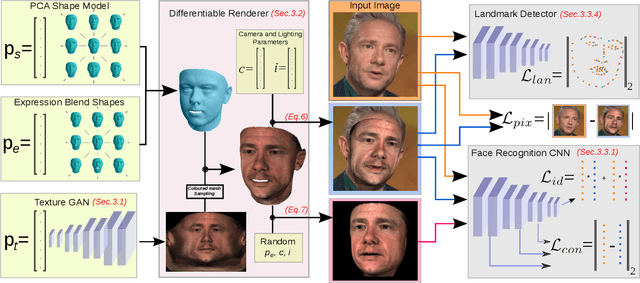

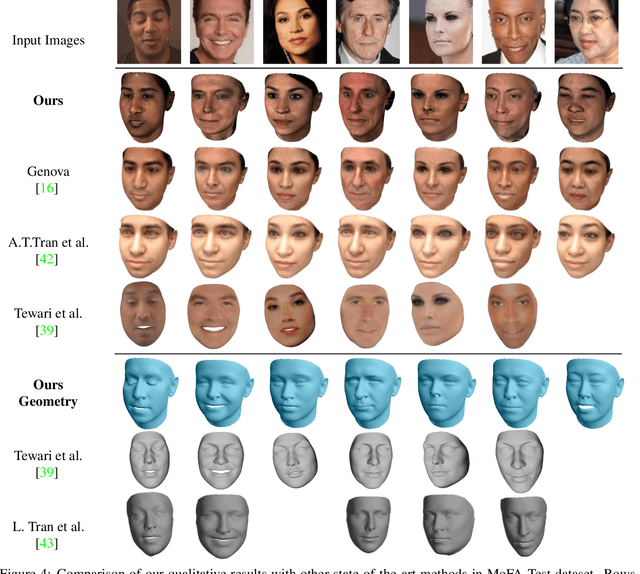
In the past few years, a lot of work has been done towards reconstructing the 3D facial structure from single images by capitalizing on the power of Deep Convolutional Neural Networks (DCNNs). In the most recent works, differentiable renderers were employed in order to learn the relationship between the facial identity features and the parameters of a 3D morphable model for shape and texture. The texture features either correspond to components of a linear texture space or are learned by auto-encoders directly from in-the-wild images. In all cases, the quality of the facial texture reconstruction of the state-of-the-art methods is still not capable of modeling textures in high fidelity. In this paper, we take a radically different approach and harness the power of Generative Adversarial Networks (GANs) and DCNNs in order to reconstruct the facial texture and shape from single images. That is, we utilize GANs to train a very powerful generator of facial texture in UV space. Then, we revisit the original 3D Morphable Models (3DMMs) fitting approaches making use of non-linear optimization to find the optimal latent parameters that best reconstruct the test image but under a new perspective. We optimize the parameters with the supervision of pretrained deep identity features through our end-to-end differentiable framework. We demonstrate excellent results in photorealistic and identity preserving 3D face reconstructions and achieve for the first time, to the best of our knowledge, facial texture reconstruction with high-frequency details.
MeshGAN: Non-linear 3D Morphable Models of Faces
Mar 25, 2019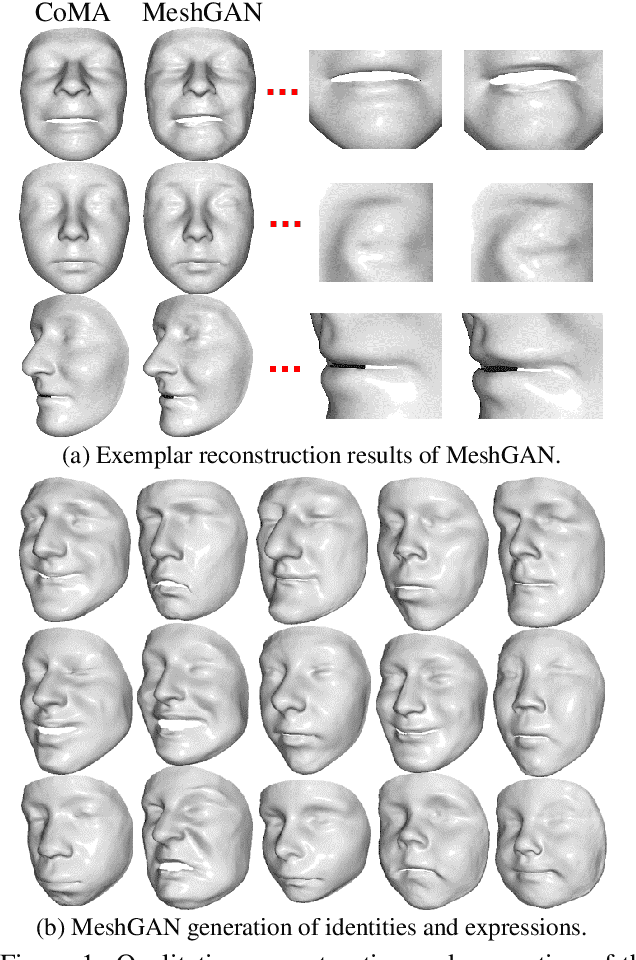


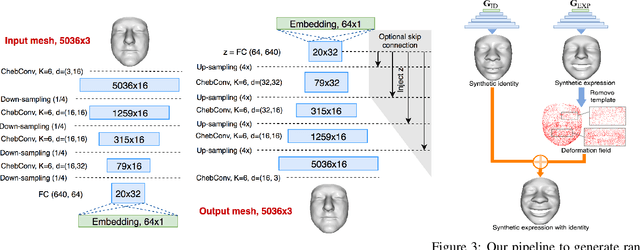
Generative Adversarial Networks (GANs) are currently the method of choice for generating visual data. Certain GAN architectures and training methods have demonstrated exceptional performance in generating realistic synthetic images (in particular, of human faces). However, for 3D object, GANs still fall short of the success they have had with images. One of the reasons is due to the fact that so far GANs have been applied as 3D convolutional architectures to discrete volumetric representations of 3D objects. In this paper, we propose the first intrinsic GANs architecture operating directly on 3D meshes (named as MeshGAN). Both quantitative and qualitative results are provided to show that MeshGAN can be used to generate high-fidelity 3D face with rich identities and expressions.
Generating faces for affect analysis
Nov 12, 2018
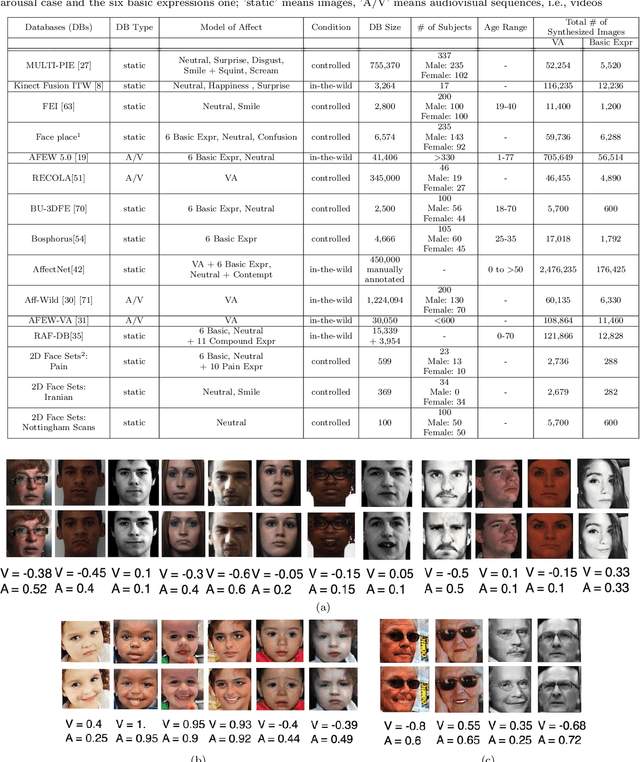

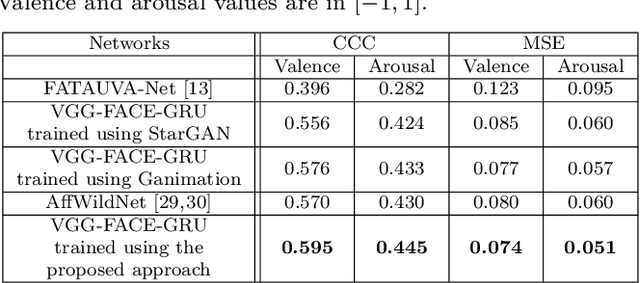
This paper presents a novel approach for synthesizing facial affect; either categorical, in terms of the six basic expressions (i.e., anger, disgust, fear, happiness, sadness and surprise), or dimensional, in terms of valence (i.e., how positive or negative is an emotion) and arousal (i.e., power of the emotion activation). In the Valence-Arousal case, a system is created, based on VA annotation of 600,000 frames from the 4DFAB database; in the categorical case, the system is based on the selection of apex frames of posed expression sequences from the 4DFAB. The proposed system accepts at its input: i) either the basic facial expression, or the pair of valence-arousal emotional state descriptors, which need to be synthesized and ii) a neutral 2D image of a person on which the corresponding affect will be synthesized. The proposed approach consists of the following steps: First, based on the provided desired emotional state, a set of 3D facial meshes is produced from the 4DFAB database and is used to build a blendshape model that generates the new facial affect. To synthesize this affect on the 2D neutral image, 3D Morphable Models fitting is performed and the reconstructed face is then deformed to generate the target facial expressions. Finally, the new face is rendered into the original image. Qualitative experimental studies illustrate the generation of realistic images, when the neutral image is sampled from a variety of well known lab-controlled or in-the-wild databases, including Aff-Wild, RECOLA, AffectNet, AFEW, Multi-PIE, AFEW-VA, BU-3DFE, Bosphorus, RAF-DB. Also, quantitative experiments are conducted, in which deep neural networks, trained using the generated images from each of the above databases in a data-augmentation framework, provide affect recognition; better performances are achieved through the presented approach when compared with the current state-of-the-art.