 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspective Reconstruction of Human Faces by Joint Mesh and Landmark Regression
Aug 15, 2022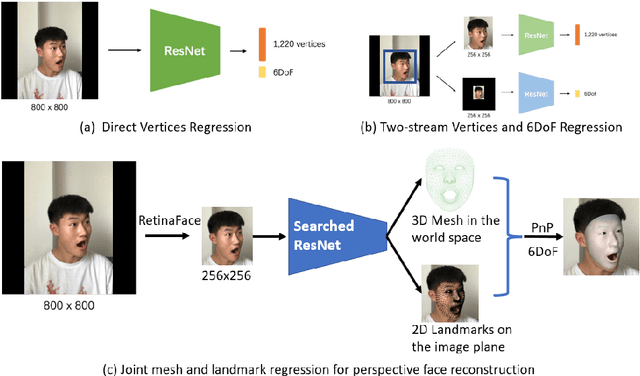

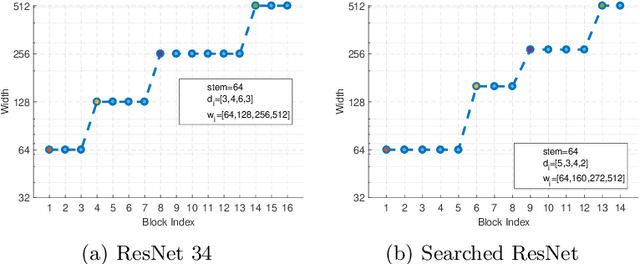

Even though 3D face reconstruction has achieved impressive progress, most orthogonal projection-based face reconstruction methods can not achieve accurate and consistent reconstruction results when the face is very close to the camera due to the distortion under the perspective projection. In this paper, we propose to simultaneously reconstruct 3D face mesh in the world space and predict 2D face landmarks on the image plane to address the problem of perspective 3D face reconstruction. Based on the predicted 3D vertices and 2D landmarks, the 6DoF (6 Degrees of Freedom) face pose can be easily estimated by the PnP solver to represent perspective projection. Our approach achieves 1st place on the leader-board of the ECCV 2022 WCPA challenge and our model is visually robust under different identities, expressions and poses. The training code and models are released to facilitate future research.
RetinaFace: Single-stage Dense Face Localisation in the Wild
May 04, 2019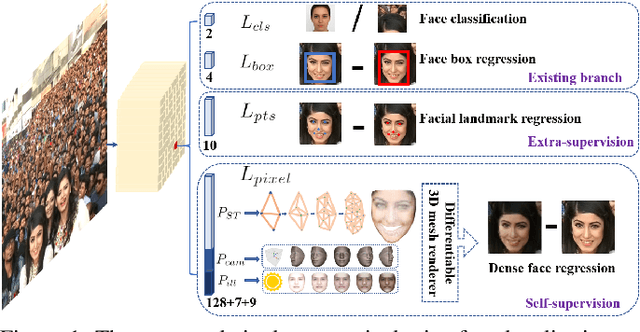

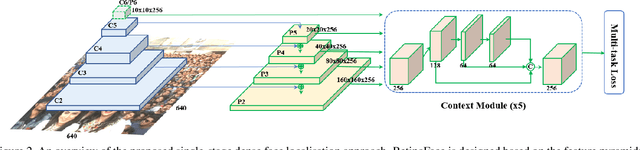

Though tremendous strides have been made in uncontrolled face detection, accurate and efficient face localisation in the wild remains an open challenge. This paper presents a robust single-stage face detector, named RetinaFace, which performs pixel-wise face localisation on various scales of faces by taking advantages of joint extra-supervised and self-supervised multi-task learning. Specifically, We make contributions in the following five aspects: (1) We manually annotate five facial landmarks on the WIDER FACE dataset and observe significant improvement in hard face detection with the assistance of this extra supervision signal. (2) We further add a self-supervised mesh decoder branch for predicting a pixel-wise 3D shape face information in parallel with the existing supervised branches. (3) On the WIDER FACE hard test set, RetinaFace outperforms the state of the art average precision (AP) by 1.1% (achieving AP equal to 91.4%). (4) On the IJB-C test set, RetinaFace enables state of the art methods (ArcFace) to improve their results in face verification (TAR=89.59% for FAR=1e-6). (5) By employing light-weight backbone networks, RetinaFace can run real-time on a single CPU core for a VGA-resolution image. Extra annotations and code have been made available at: https://github.com/deepinsight/insightface/tree/master/RetinaFace.
PFLD: A Practical Facial Landmark Detector
Mar 03, 2019
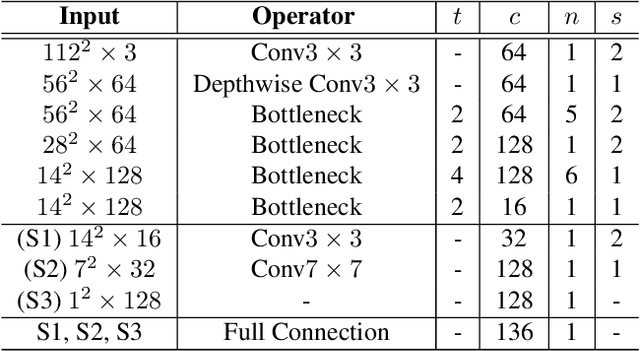
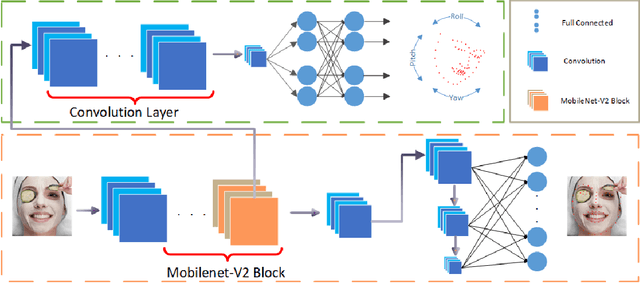

Being accurate, efficient, and compact is essential to a facial landmark detector for practical use. To simultaneously consider the three concerns, this paper investigates a neat model with promising detection accuracy under wild environments e.g., unconstrained pose, expression, lighting, and occlusion conditions) and super real-time speed on a mobile device. More concretely, we customize an end-to-end single stage network associated with acceleration techniques. During the training phase, for each sample, rotation information is estimated for geometrically regularizing landmark localization, which is then NOT involved in the testing phase. A novel loss is designed to, besides considering the geometrical regularization, mitigate the issue of data imbalance by adjusting weights of samples to different states, such as large pose, extreme lighting, and occlusion, in the training set. Extensive experiments are conducted to demonstrate the efficacy of our design and reveal its superior performance over state-of-the-art alternatives on widely-adopted challenging benchmarks, i.e., 300W (including iBUG, LFPW, AFW, HELEN, and XM2VTS) and AFLW. Our model can be merely 2.1Mb of size and reach over 140 fps per face on a mobile phone (Qualcomm ARM 845 processor) with high precision, making it attractive for large-scale or real-time applications. We have made our practical system based on PFLD 0.25X model publicly available at \url{http://sites.google.com/view/xjguo/fld} for encouraging comparisons and improvements from the community.
Fast Single Image Rain Removal via a Deep Decomposition-Composition Network
Apr 08, 2018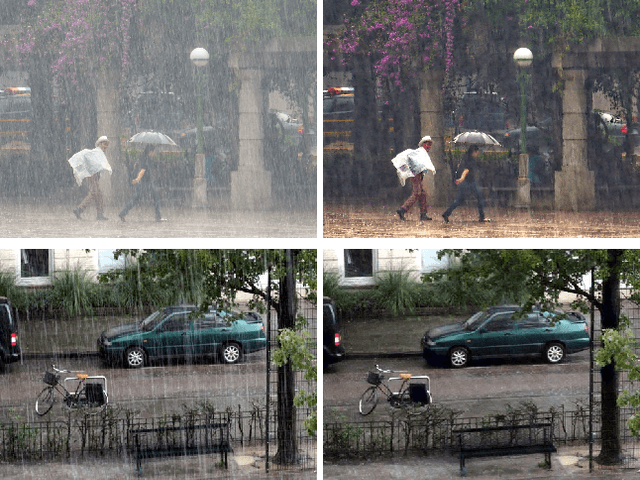
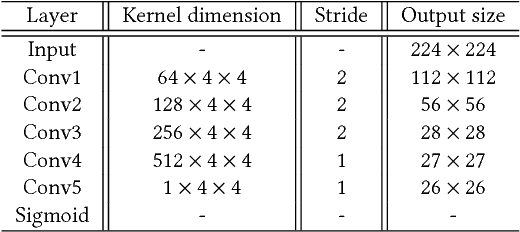
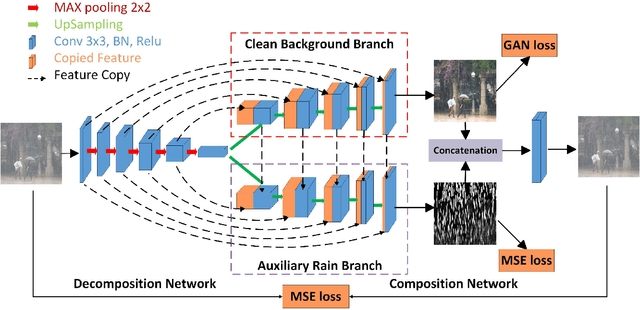
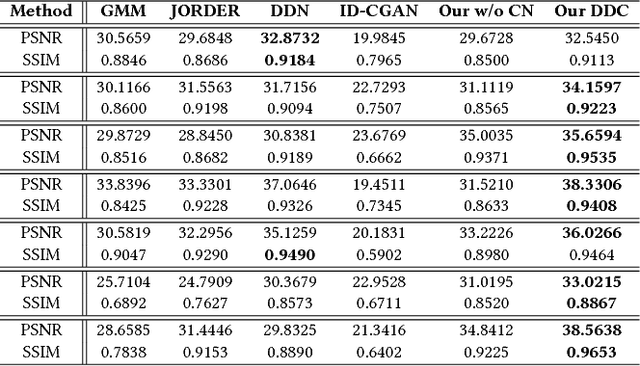
Rain effect in images typically is annoying for many multimedia and computer vision tasks. For removing rain effect from a single image, deep leaning techniques have been attracting considerable attentions. This paper designs a novel multi-task leaning architecture in an end-to-end manner to reduce the mapping range from input to output and boost the performance. Concretely, a decomposition net is built to split rain images into clean background and rain layers. Different from previous architectures, our model consists of, besides a component representing the desired clean image, an extra component for the rain layer. During the training phase, we further employ a composition structure to reproduce the input by the separated clean image and rain information for improving the quality of decomposition. Experimental results on both synthetic and real images are conducted to reveal the high-quality recovery by our design, and show its superiority over other state-of-the-art methods. Furthermore, our design is also applicable to other layer decomposition tasks like dust removal. More importantly, our method only requires about 50ms, significantly faster than the competitors, to process a testing image in VGA resolution on a GTX 1080 GPU, making it attractive for practical use.