 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Normal Estimation from Rags to Riches
Jan 05, 2026Although recent approaches to face normal estimation have achieved promising results, their effectiveness heavily depends on large-scale paired data for training. This paper concentrates on relieving this requirement via developing a coarse-to-fine normal estimator. Concretely, our method first trains a neat model from a small dataset to produce coarse face normals that perform as guidance (called exemplars) for the following refinement. A self-attention mechanism is employed to capture long-range dependencies, thus remedying severe local artifacts left in estimated coarse facial normals. Then, a refinement network is customized for the sake of mapping input face images together with corresponding exemplars to fine-grained high-quality facial normals. Such a logical function split can significantly cut the requirement of massive paired data and computational resource. Extensive experiments and ablation studies are conducted to demonstrate the efficacy of our design and reveal its superiority over state-of-the-art methods in terms of both training expense as well as estimation quality. Our code and models are open-sourced at: https://github.com/AutoHDR/FNR2R.git.
Adaptive Frequency Domain Alignment Network for Medical image segmentation
Dec 20, 2025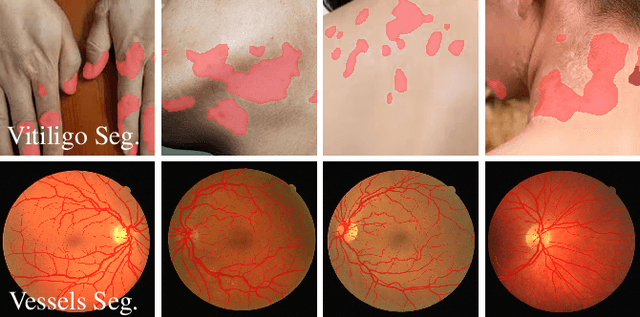
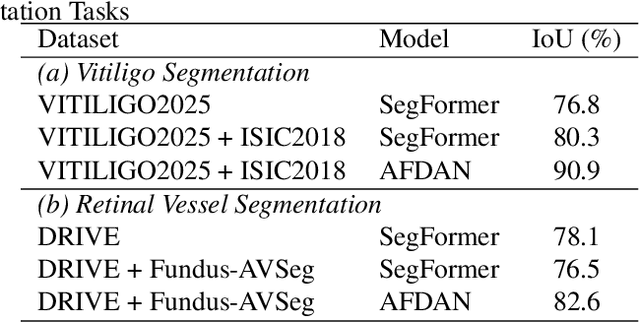
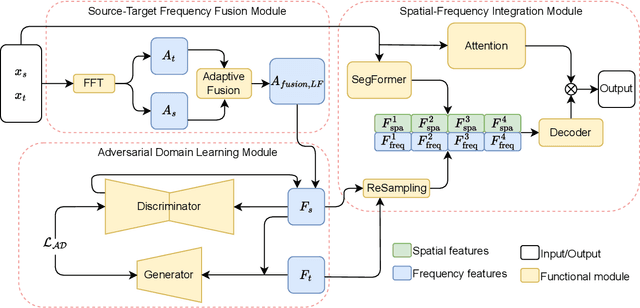
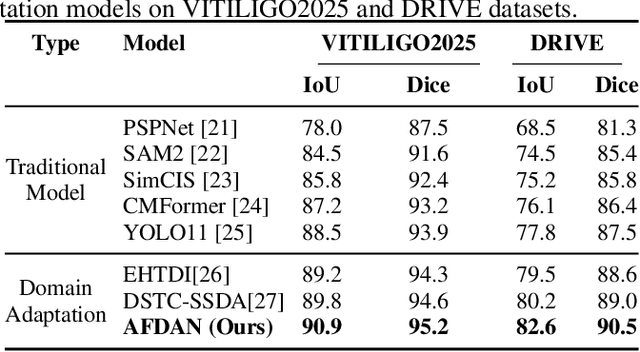
High-quality annotated data plays a crucial role in achieving accurate segmentation. However, such data for medical image segmentation are often scarce due to the time-consuming and labor-intensive nature of manual annotation. To address this challenge, we propose the Adaptive Frequency Domain Alignment Network (AFDAN)--a novel domain adaptation framework designed to align features in the frequency domain and alleviate data scarcity. AFDAN integrates three core components to enable robust cross-domain knowledge transfer: an Adversarial Domain Learning Module that transfers features from the source to the target domain; a Source-Target Frequency Fusion Module that blends frequency representations across domains; and a Spatial-Frequency Integration Module that combines both frequency and spatial features to further enhance segmentation accuracy across domains. Extensive experiments demonstrate the effectiveness of AFDAN: it achieves an Intersection over Union (IoU) of 90.9% for vitiligo segmentation in the newly constructed VITILIGO2025 dataset and a competitive IoU of 82.6% on the retinal vessel segmentation benchmark DRIVE, surpassing existing state-of-the-art approaches.
Face Inverse Rendering via Hierarchical Decoupling
Jan 17, 2023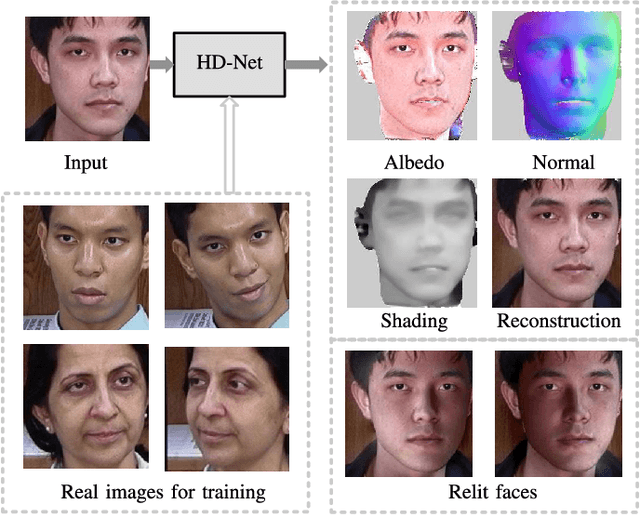

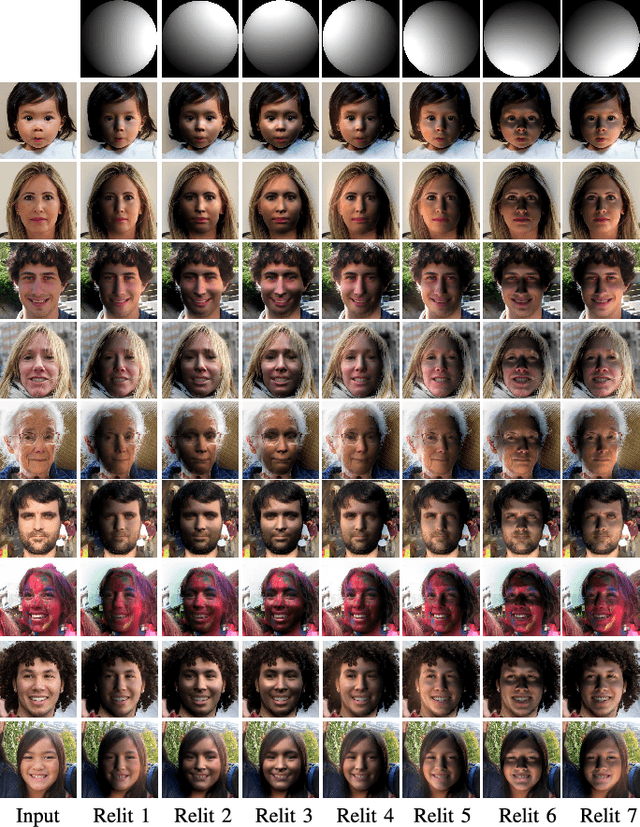

Previous face inverse rendering methods often require synthetic data with ground truth and/or professional equipment like a lighting stage. However, a model trained on synthetic data or using pre-defined lighting priors is typically unable to generalize well for real-world situations, due to the gap between synthetic data/lighting priors and real data. Furthermore, for common users, the professional equipment and skill make the task expensive and complex. In this paper, we propose a deep learning framework to disentangle face images in the wild into their corresponding albedo, normal, and lighting components. Specifically, a decomposition network is built with a hierarchical subdivision strategy, which takes image pairs captured from arbitrary viewpoints as input. In this way, our approach can greatly mitigate the pressure from data preparation, and significantly broaden the applicability of face inverse rendering. Extensive experiments are conducted to demonstrate the efficacy of our design, and show its superior performance in face relighting over other state-of-the-art alternatives. {Our code is available at \url{https://github.com/AutoHDR/HD-Net.git}}
Deep Uncalibrated Photometric Stereo via Inter-Intra Image Feature Fusion
Aug 06, 2022



Uncalibrated photometric stereo is proposed to estimate the detailed surface normal from images under varying and unknown lightings. Recently, deep learning brings powerful data priors to this underdetermined problem. This paper presents a new method for deep uncalibrated photometric stereo, which efficiently utilizes the inter-image representation to guide the normal estimation. Previous methods use optimization-based neural inverse rendering or a single size-independent pooling layer to deal with multiple inputs, which are inefficient for utilizing information among input images. Given multi-images under different lighting, we consider the intra-image and inter-image variations highly correlated. Motivated by the correlated variations, we designed an inter-intra image feature fusion module to introduce the inter-image representation into the per-image feature extraction. The extra representation is used to guide the per-image feature extraction and eliminate the ambiguity in normal estimation. We demonstrate the effect of our design on a wide range of samples, especially on dark materials. Our method produces significantly better results than the state-of-the-art methods on both synthetic and real data.
Towards Visual Explainable Active Learning for Zero-Shot Classification
Aug 15, 2021



Zero-shot classification is a promising paradigm to solve an applicable problem when the training classes and test classes are disjoint. Achieving this usually needs experts to externalize their domain knowledge by manually specifying a class-attribute matrix to define which classes have which attributes. Designing a suitable class-attribute matrix is the key to the subsequent procedure, but this design process is tedious and trial-and-error with no guidance. This paper proposes a visual explainable active learning approach with its design and implementation called semantic navigator to solve the above problems. This approach promotes human-AI teaming with four actions (ask, explain, recommend, respond) in each interaction loop. The machine asks contrastive questions to guide humans in the thinking process of attributes. A novel visualization called semantic map explains the current status of the machine. Therefore analysts can better understand why the machine misclassifies objects. Moreover, the machine recommends the labels of classes for each attribute to ease the labeling burden. Finally, humans can steer the model by modifying the labels interactively, and the machine adjusts its recommendations. The visual explainable active learning approach improves humans' efficiency of building zero-shot classification models interactively, compared with the method without guidance. We justify our results with user studies using the standard benchmarks for zero-shot classification.
Dunhuang Grottoes Painting Dataset and Benchmark
Jul 11, 2019



This document introduces the background and the usage of the Dunhuang Grottoes Dataset and the benchmark. The documentation first starts with the background of the Dunhuang Grotto, which is widely recognised as an priceless heritage. Given that digital method is the modern trend for heritage protection and restoration. Follow the trend, we release the first public dataset for Dunhuang Grotto Painting restoration. The rest of the documentation details the painting data generation. To enable a data driven fashion, this dataset provided a large number of training and testing example which is sufficient for a deep learning approach. The detailed usage of the dataset as well as the benchmark is described.
OVSNet : Towards One-Pass Real-Time Video Object Segmentation
May 24, 2019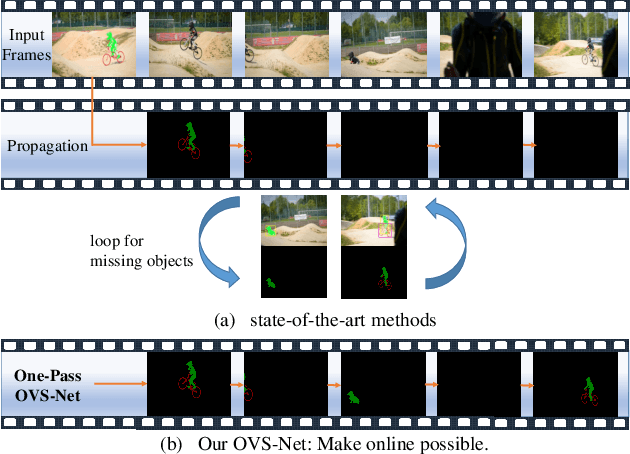
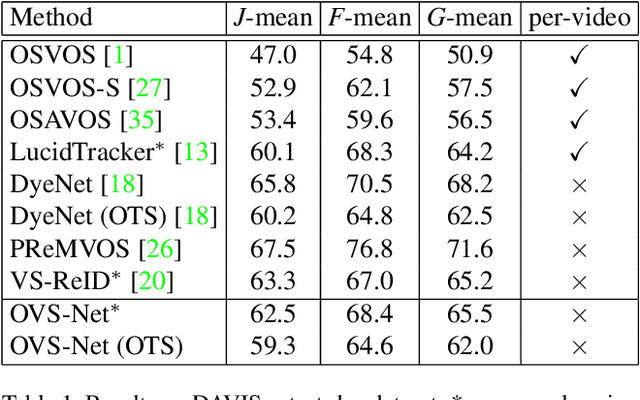
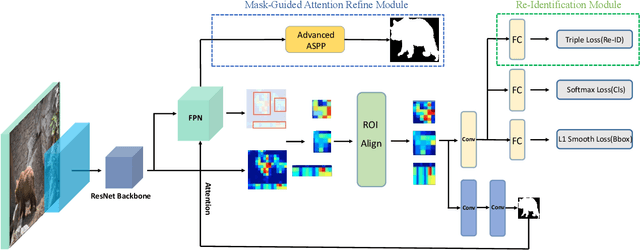
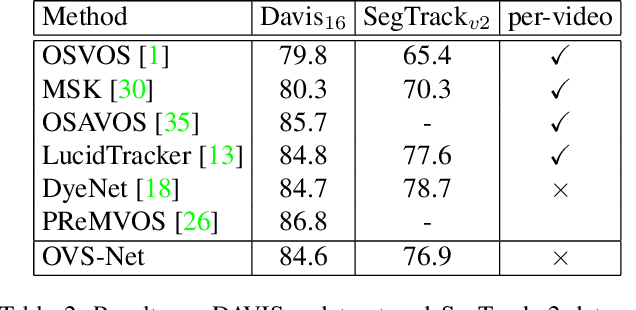
Video object segmentation aims at accurately segmenting the target object regions across consecutive frames. It is technically challenging for coping with complicated factors (e.g., shape deformations, occlusion and out of the lens). Recent approaches have largely solved them by using backforth re-identification and bi-directional mask propagation. However, their methods are extremely slow and only support offline inference, which in principle cannot be applied in real time. Motivated by this observation, we propose a new detection-based paradigm for video object segmentation. We propose an unified One-Pass Video Segmentation framework (OVS-Net) for modeling spatial-temporal representation in an end-to-end pipeline, which seamlessly integrates object detection, object segmentation, and object re-identification. The proposed framework lends itself to one-pass inference that effectively and efficiently performs video object segmentation. Moreover, we propose a mask guided attention module for modeling the multi-scale object boundary and multi-level feature fusion. Experiments on the challenging DAVIS 2017 demonstrate the effectiveness of the proposed framework with comparable performance to the state-of-the-art, and the great efficiency about 11.5 fps towards pioneering real-time work to our knowledge, more than 5 times faster than other state-of-the-art methods.
Kindling the Darkness: A Practical Low-light Image Enhancer
May 04, 2019
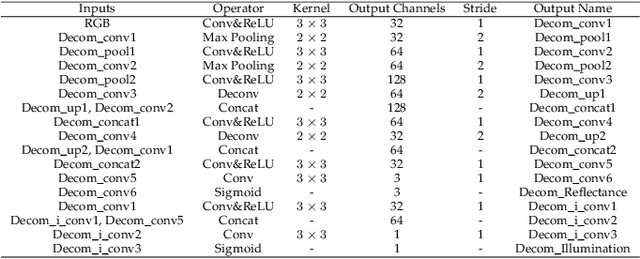
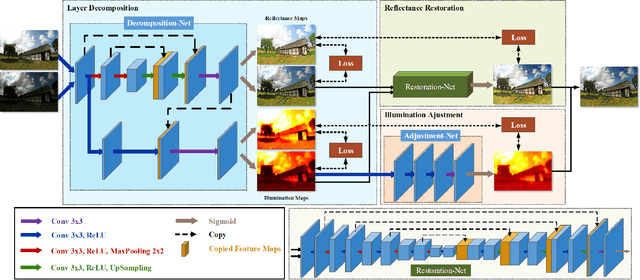

Images captured under low-light conditions often suffer from (partially) poor visibility. Besides unsatisfactory lightings, multiple types of degradations, such as noise and color distortion due to the limited quality of cameras, hide in the dark. In other words, solely turning up the brightness of dark regions will inevitably amplify hidden artifacts. This work builds a simple yet effective network for \textbf{Kin}dling the \textbf{D}arkness (denoted as KinD), which, inspired by Retinex theory, decomposes images into two components. One component (illumination) is responsible for light adjustment, while the other (reflectance) for degradation removal. In such a way, the original space is decoupled into two smaller subspaces, expecting to be better regularized/learned. It is worth to note that our network is trained with paired images shot under different exposure conditions, instead of using any ground-truth reflectance and illumination information. Extensive experiments are conducted to demonstrate the efficacy of our design and its superiority over state-of-the-art alternatives. Our KinD is robust against severe visual defects, and user-friendly to arbitrarily adjust light levels. In addition, our model spends less than 50ms to process an image in VGA resolution on a 2080Ti GPU. All the above merits make our KinD attractive for practical use.
Single Image Deraining: A Comprehensive Benchmark Analysis
Mar 20, 2019
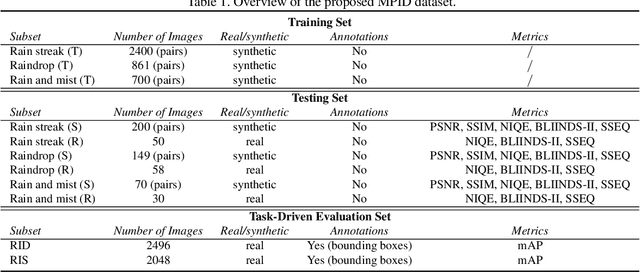
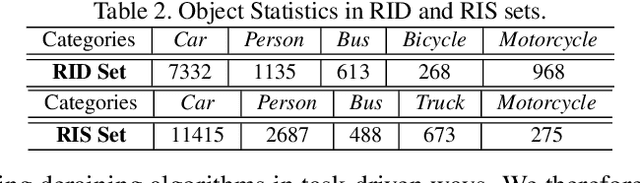

We present a comprehensive study and evaluation of existing single image deraining algorithms, using a new large-scale benchmark consisting of both synthetic and real-world rainy images.This dataset highlights diverse data sources and image contents, and is divided into three subsets (rain streak, rain drop, rain and mist), each serving different training or evaluation purposes. We further provide a rich variety of criteria for dehazing algorithm evaluation, ranging from full-reference metrics, to no-reference metrics, to subjective evaluation and the novel task-driven evaluation. Experiments on the dataset shed light on the comparisons and limitations of state-of-the-art deraining algorithms, and suggest promising future directions.
PFLD: A Practical Facial Landmark Detector
Mar 03, 2019
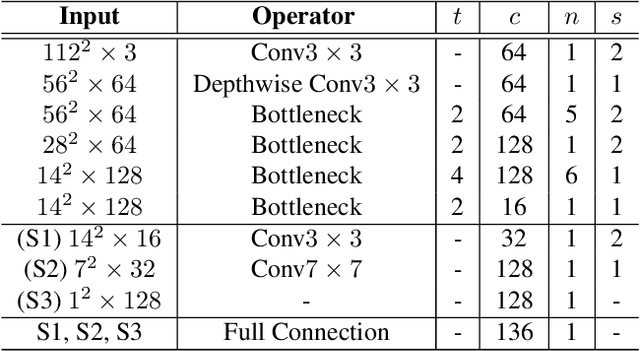
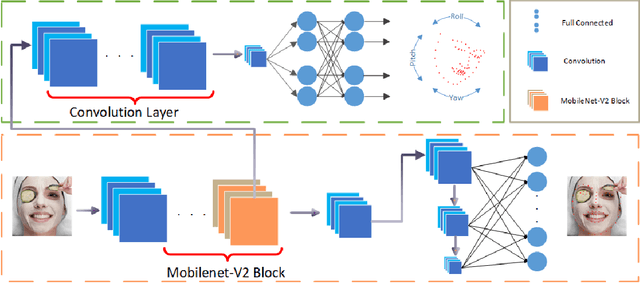

Being accurate, efficient, and compact is essential to a facial landmark detector for practical use. To simultaneously consider the three concerns, this paper investigates a neat model with promising detection accuracy under wild environments e.g., unconstrained pose, expression, lighting, and occlusion conditions) and super real-time speed on a mobile device. More concretely, we customize an end-to-end single stage network associated with acceleration techniques. During the training phase, for each sample, rotation information is estimated for geometrically regularizing landmark localization, which is then NOT involved in the testing phase. A novel loss is designed to, besides considering the geometrical regularization, mitigate the issue of data imbalance by adjusting weights of samples to different states, such as large pose, extreme lighting, and occlusion, in the training set. Extensive experiments are conducted to demonstrate the efficacy of our design and reveal its superior performance over state-of-the-art alternatives on widely-adopted challenging benchmarks, i.e., 300W (including iBUG, LFPW, AFW, HELEN, and XM2VTS) and AFLW. Our model can be merely 2.1Mb of size and reach over 140 fps per face on a mobile phone (Qualcomm ARM 845 processor) with high precision, making it attractive for large-scale or real-time applications. We have made our practical system based on PFLD 0.25X model publicly available at \url{http://sites.google.com/view/xjguo/fld} for encouraging comparisons and improvements from the community.