 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Recall, and Tell: Image Captioning with Recall Mechanism
Jan 15, 2020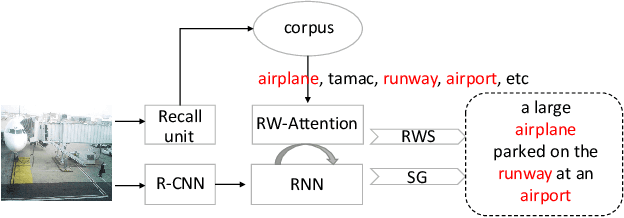

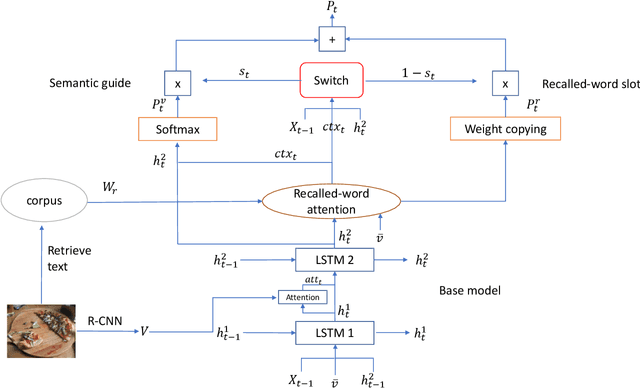

Generating natural and accurate descriptions in image cap-tioning has always been a challenge. In this paper, we pro-pose a novel recall mechanism to imitate the way human con-duct captioning. There are three parts in our recall mecha-nism : recall unit, semantic guide (SG) and recalled-wordslot (RWS). Recall unit is a text-retrieval module designedto retrieve recalled words for images. SG and RWS are de-signed for the best use of recalled words. SG branch cangenerate a recalled context, which can guide the process ofgenerating caption. RWS branch is responsible for copyingrecalled words to the caption. Inspired by pointing mecha-nism in text summarization, we adopt a soft switch to balancethe generated-word probabilities between SG and RWS. Inthe CIDEr optimization step, we also introduce an individualrecalled-word reward (WR) to boost training. Our proposedmethods (SG+RWS+WR) achieve BLEU-4 / CIDEr / SPICEscores of 36.6 / 116.9 / 21.3 with cross-entropy loss and 38.7 /129.1 / 22.4 with CIDEr optimization on MSCOCO Karpathytest split, which surpass the results of other state-of-the-artmethods.
Kindling the Darkness: A Practical Low-light Image Enhancer
May 04, 2019
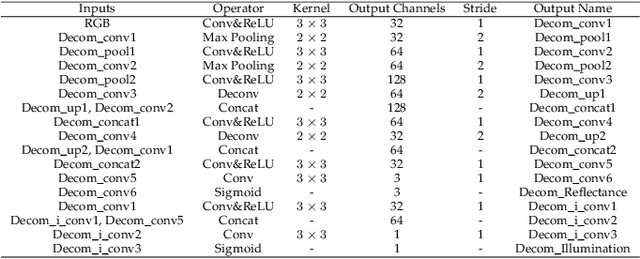
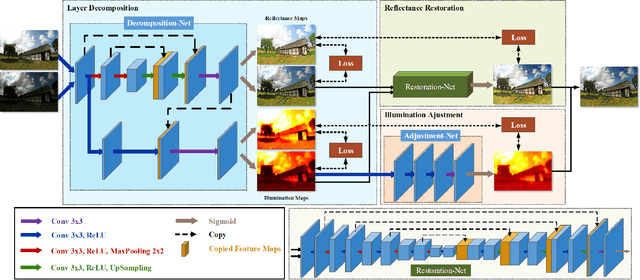

Images captured under low-light conditions often suffer from (partially) poor visibility. Besides unsatisfactory lightings, multiple types of degradations, such as noise and color distortion due to the limited quality of cameras, hide in the dark. In other words, solely turning up the brightness of dark regions will inevitably amplify hidden artifacts. This work builds a simple yet effective network for \textbf{Kin}dling the \textbf{D}arkness (denoted as KinD), which, inspired by Retinex theory, decomposes images into two components. One component (illumination) is responsible for light adjustment, while the other (reflectance) for degradation removal. In such a way, the original space is decoupled into two smaller subspaces, expecting to be better regularized/learned. It is worth to note that our network is trained with paired images shot under different exposure conditions, instead of using any ground-truth reflectance and illumination information. Extensive experiments are conducted to demonstrate the efficacy of our design and its superiority over state-of-the-art alternatives. Our KinD is robust against severe visual defects, and user-friendly to arbitrarily adjust light levels. In addition, our model spends less than 50ms to process an image in VGA resolution on a 2080Ti GPU. All the above merits make our KinD attractive for practical use.
Attend More Times for Image Captioning
Dec 08, 2018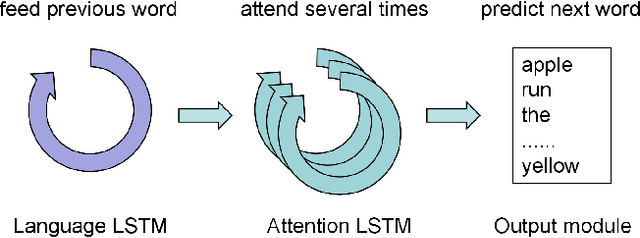
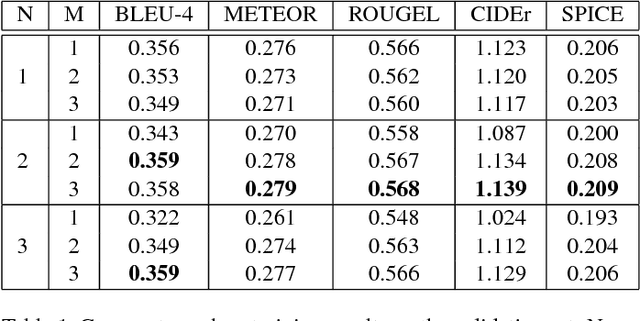
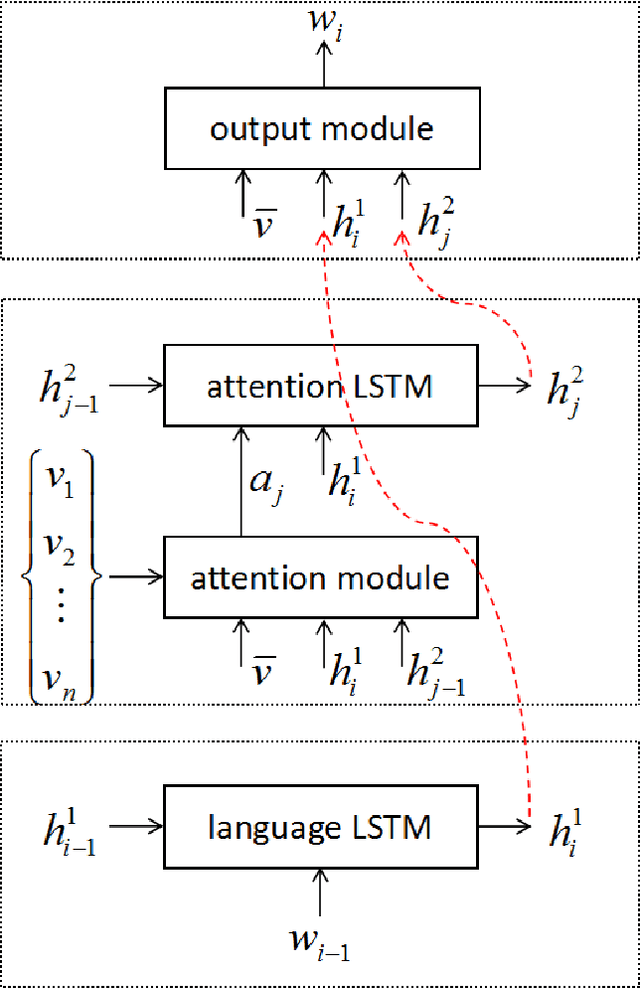

Most attention-based image captioning models attend to the image once per word. However, attending once per word is rigid and is easy to miss some information. Attending more times can adjust the attention position, find the missing information back and avoid generating the wrong word. In this paper, we show that attending more times per word can gain improvements in the image captioning task. We propose a flexible two-LSTM merge model to make it convenient to encode more attentions than words. Our captioning model uses two LSTMs to encode the word sequence and the attention sequence respectively. The information of the two LSTMs and the image feature are combined to predict the next word. Experiments on the MSCOCO caption dataset show that our method outperforms the state-of-the-art. Using bottom up features and self-critical training method, our method gets BLEU-4, METEOR, ROUGE-L and CIDEr scores of 0.381, 0.283, 0.580 and 1.261 on the Karpathy test split.