 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal-to-Global Information Communication for Real-Time Semantic Segmentation Network Search
Feb 16, 2023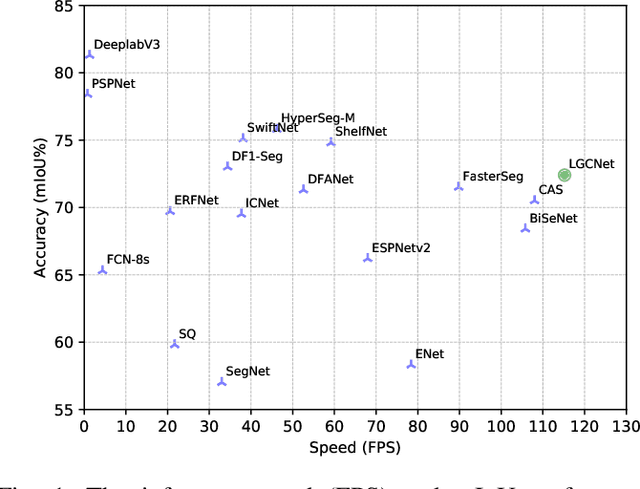
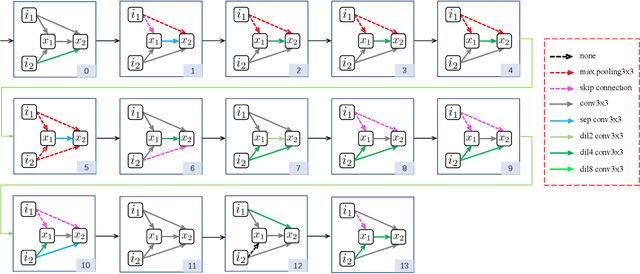
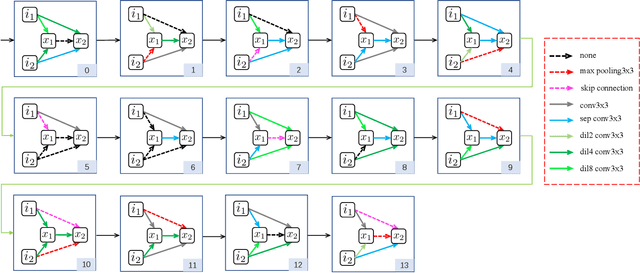
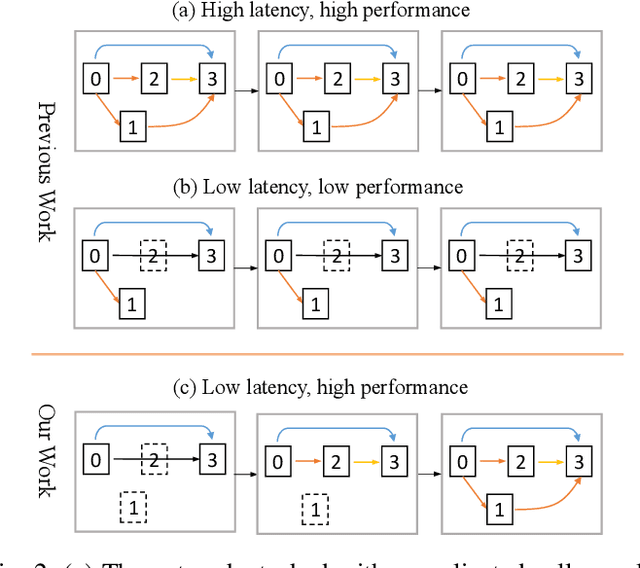
Neural Architecture Search (NAS) has shown great potentials in automatically designing neural network architectures for real-time semantic segmentation. Unlike previous works that utilize a simplified search space with cell-sharing way, we introduce a new search space where a lightweight model can be more effectively searched by replacing the cell-sharing manner with cell-independent one. Based on this, the communication of local to global information is achieved through two well-designed modules. For local information exchange, a graph convolutional network (GCN) guided module is seamlessly integrated as a communication deliver between cells. For global information aggregation, we propose a novel dense-connected fusion module (cell) which aggregates long-range multi-level features in the network automatically. In addition, a latency-oriented constraint is endowed into the search process to balance the accuracy and latency. We name the proposed framework as Local-to-Global Information Communication Network Search (LGCNet). Extensive experiments on Cityscapes and CamVid datasets demonstrate that LGCNet achieves the new state-of-the-art trade-off between accuracy and speed. In particular, on Cityscapes dataset, LGCNet achieves the new best performance of 74.0\% mIoU with the speed of 115.2 FPS on Titan Xp.
Real-Time Semantic Segmentation via Auto Depth, Downsampling Joint Decision and Feature Aggregation
Mar 31, 2020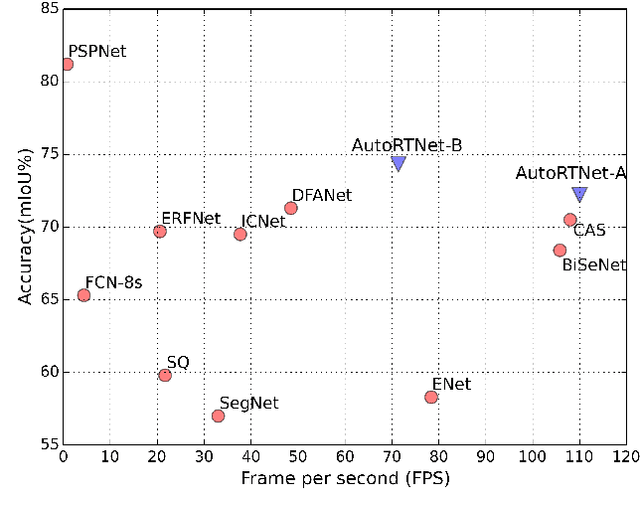
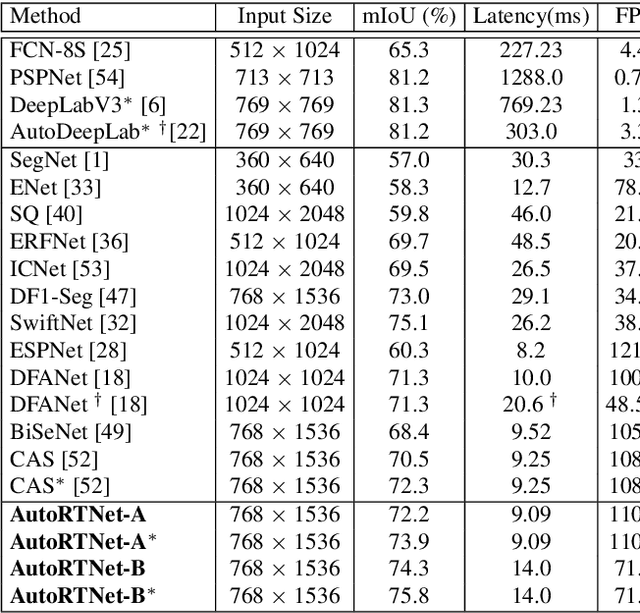
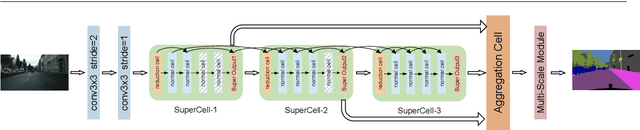
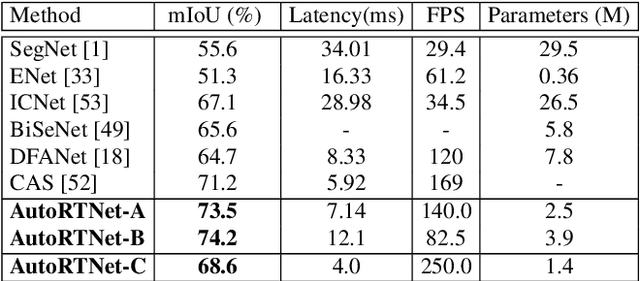
To satisfy the stringent requirements on computational resources in the field of real-time semantic segmentation, most approaches focus on the hand-crafted design of light-weight segmentation networks. Recently, Neural Architecture Search (NAS) has been used to search for the optimal building blocks of networks automatically, but the network depth, downsampling strategy, and feature aggregation way are still set in advance by trial and error. In this paper, we propose a joint search framework, called AutoRTNet, to automate the design of these strategies. Specifically, we propose hyper-cells to jointly decide the network depth and downsampling strategy, and an aggregation cell to achieve automatic multi-scale feature aggregation. Experimental results show that AutoRTNet achieves 73.9% mIoU on the Cityscapes test set and 110.0 FPS on an NVIDIA TitanXP GPU card with 768x1536 input images.
Graph-guided Architecture Search for Real-time Semantic Segmentation
Sep 15, 2019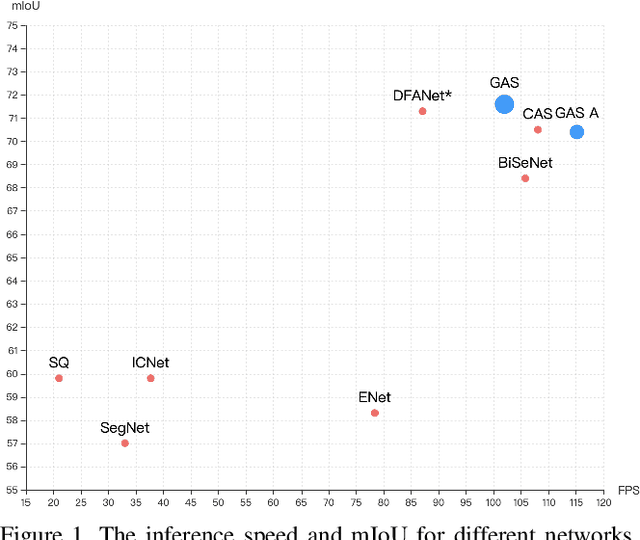
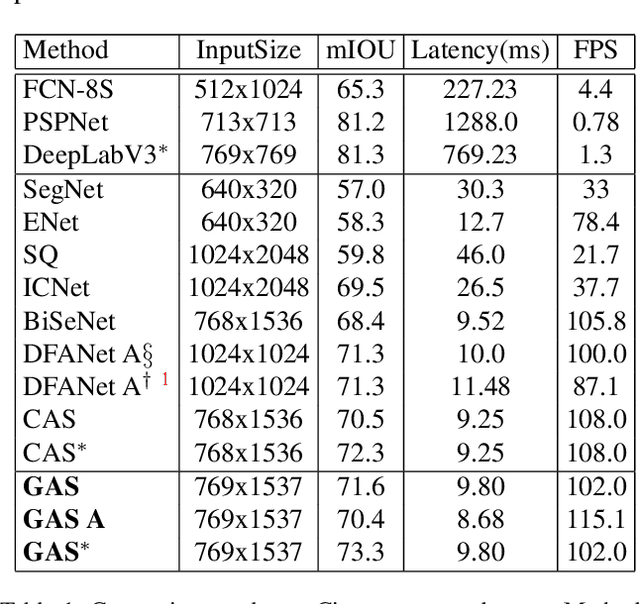

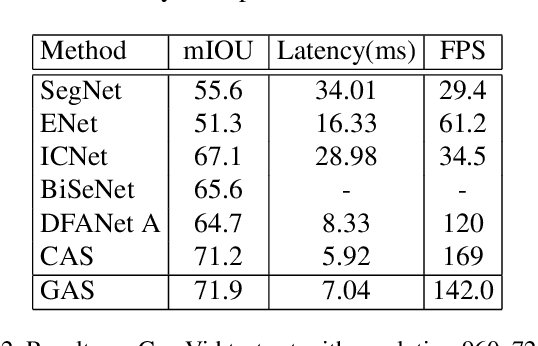
Designing a lightweight semantic segmentation network often requires researchers to find a trade-off between performance and speed, which is always empirical due to the limited interpretability of neural networks. In order to release researchers from these tedious mechanical trials, we propose a Graph-guided Architecture Search (GAS) pipeline to automatically search real-time semantic segmentation networks. Unlike previous works that use a simplified search space and stack a repeatable cell to form a network, we introduce a novel search mechanism with new search space where a lightweight model can be effectively explored through the cell-level diversity and latencyoriented constraint. Specifically, to produce the cell-level diversity, the cell-sharing constraint is eliminated through the cell-independent manner. Then a graph convolution network (GCN) is seamlessly integrated as a communication mechanism between cells. Finally, a latency-oriented constraint is endowed into the search process to balance the speed and performance. Extensive experiments on Cityscapes and CamVid datasets demonstrate that GAS achieves new state-of-the-art trade-off between accuracy and speed. In particular, on Cityscapes dataset, GAS achieves the new best performance of 73.3% mIoU with speed of 102 FPS on Titan Xp.
OVSNet : Towards One-Pass Real-Time Video Object Segmentation
May 24, 2019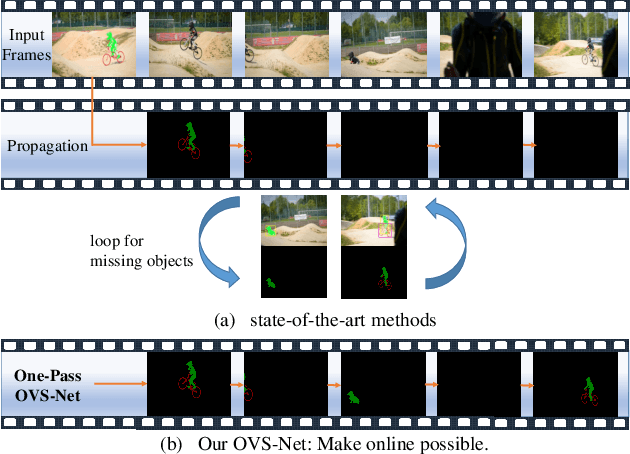
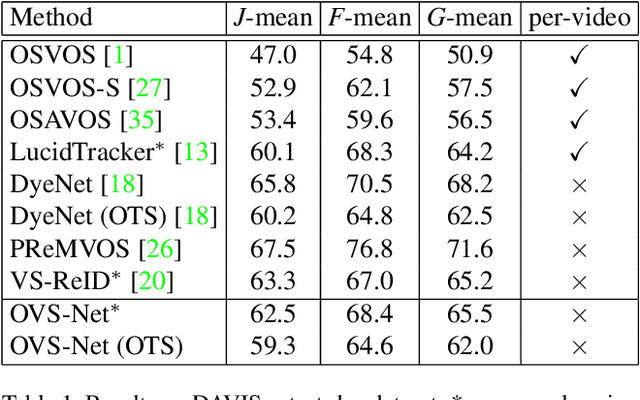
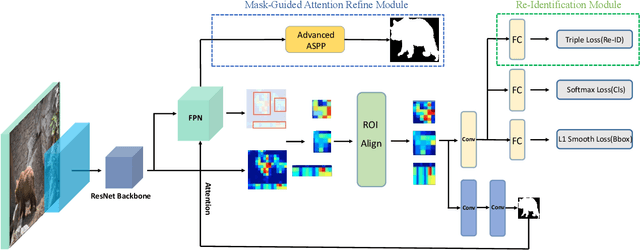
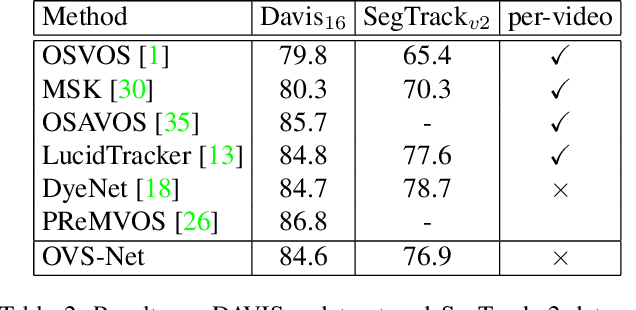
Video object segmentation aims at accurately segmenting the target object regions across consecutive frames. It is technically challenging for coping with complicated factors (e.g., shape deformations, occlusion and out of the lens). Recent approaches have largely solved them by using backforth re-identification and bi-directional mask propagation. However, their methods are extremely slow and only support offline inference, which in principle cannot be applied in real time. Motivated by this observation, we propose a new detection-based paradigm for video object segmentation. We propose an unified One-Pass Video Segmentation framework (OVS-Net) for modeling spatial-temporal representation in an end-to-end pipeline, which seamlessly integrates object detection, object segmentation, and object re-identification. The proposed framework lends itself to one-pass inference that effectively and efficiently performs video object segmentation. Moreover, we propose a mask guided attention module for modeling the multi-scale object boundary and multi-level feature fusion. Experiments on the challenging DAVIS 2017 demonstrate the effectiveness of the proposed framework with comparable performance to the state-of-the-art, and the great efficiency about 11.5 fps towards pioneering real-time work to our knowledge, more than 5 times faster than other state-of-the-art methods.