 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal-to-Global Information Communication for Real-Time Semantic Segmentation Network Search
Feb 16, 2023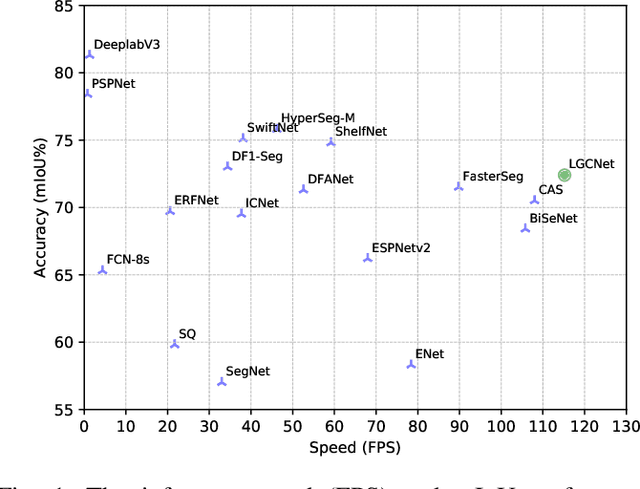
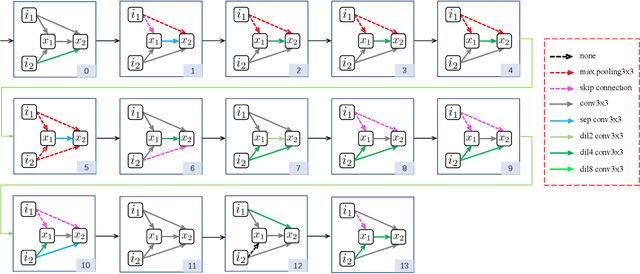
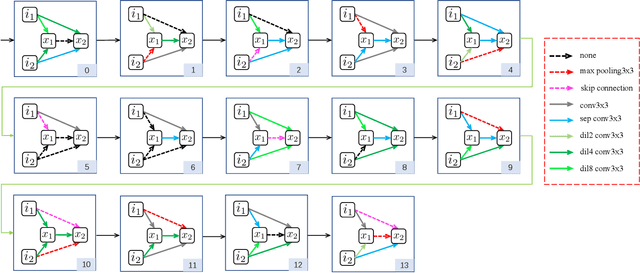
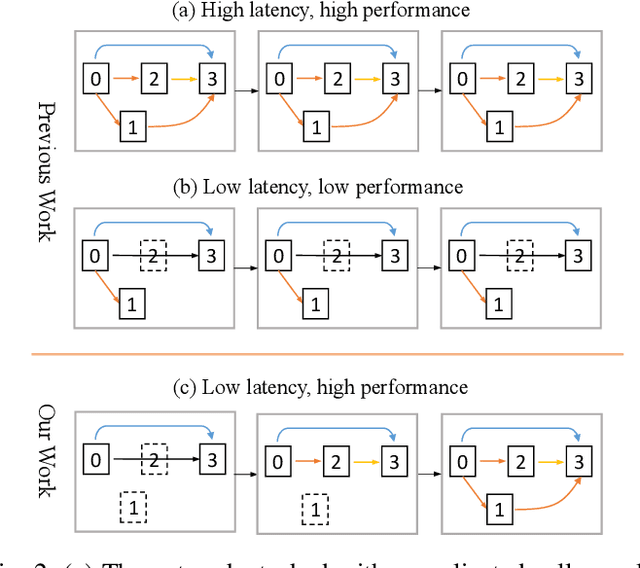
Neural Architecture Search (NAS) has shown great potentials in automatically designing neural network architectures for real-time semantic segmentation. Unlike previous works that utilize a simplified search space with cell-sharing way, we introduce a new search space where a lightweight model can be more effectively searched by replacing the cell-sharing manner with cell-independent one. Based on this, the communication of local to global information is achieved through two well-designed modules. For local information exchange, a graph convolutional network (GCN) guided module is seamlessly integrated as a communication deliver between cells. For global information aggregation, we propose a novel dense-connected fusion module (cell) which aggregates long-range multi-level features in the network automatically. In addition, a latency-oriented constraint is endowed into the search process to balance the accuracy and latency. We name the proposed framework as Local-to-Global Information Communication Network Search (LGCNet). Extensive experiments on Cityscapes and CamVid datasets demonstrate that LGCNet achieves the new state-of-the-art trade-off between accuracy and speed. In particular, on Cityscapes dataset, LGCNet achieves the new best performance of 74.0\% mIoU with the speed of 115.2 FPS on Titan Xp.
Embedded Knowledge Distillation in Depth-level Dynamic Neural Network
Mar 01, 2021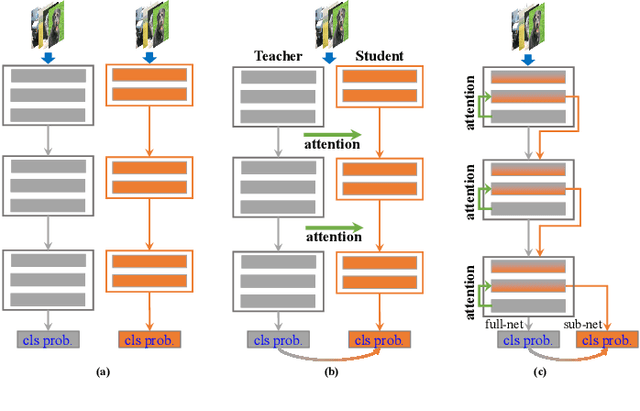
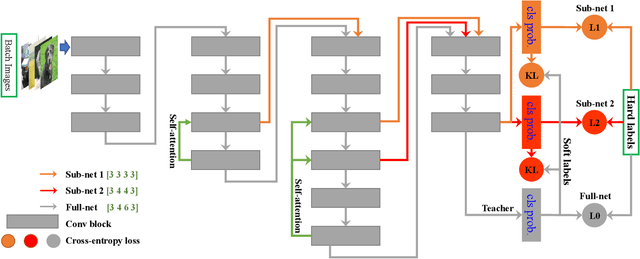

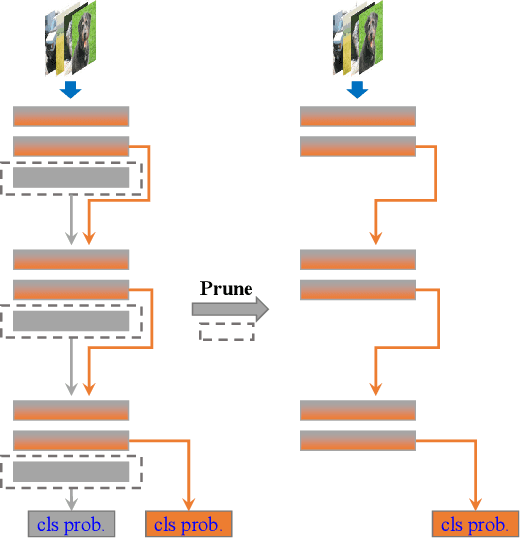
In real applications, different computation-resource devices need different-depth networks (e.g., ResNet-18/34/50) with high-accuracy. Usually, existing strategies either design multiple networks (nets) and train them independently, or utilize compression techniques (e.g., low-rank decomposition, pruning, and teacher-to-student) to evolve a trained large model into a small net. These methods are subject to the low-accuracy of small nets, or complicated training processes induced by the dependence of accompanying assistive large models. In this article, we propose an elegant Depth-level Dynamic Neural Network (DDNN) integrated different-depth sub-nets of similar architectures. Instead of training individual nets with different-depth configurations, we only train a DDNN to dynamically switch different-depth sub-nets at runtime using one set of shared weight parameters. To improve the generalization of sub-nets, we design the Embedded-Knowledge-Distillation (EKD) training mechanism for the DDNN to implement semantic knowledge transfer from the teacher (full) net to multiple sub-nets. Specifically, the Kullback-Leibler divergence is introduced to constrain the posterior class probability consistency between full-net and sub-net, and self-attention on the same resolution feature of different depth is addressed to drive more abundant feature representations of sub-nets. Thus, we can obtain multiple high accuracy sub-nets simultaneously in a DDNN via the online knowledge distillation in each training iteration without extra computation cost. Extensive experiments on CIFAR-10, CIFAR-100, and ImageNet datasets demonstrate that sub-nets in DDNN with EKD training achieves better performance than the depth-level pruning or individually training while preserving the original performance of full-net.
Multi-hierarchical Independent Correlation Filters for Visual Tracking
Nov 27, 2018
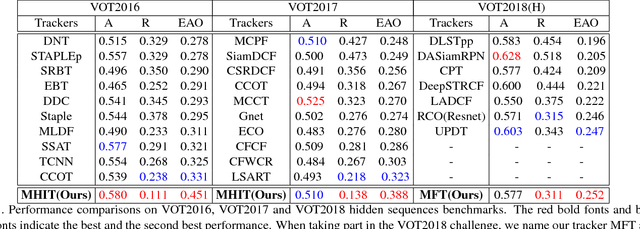
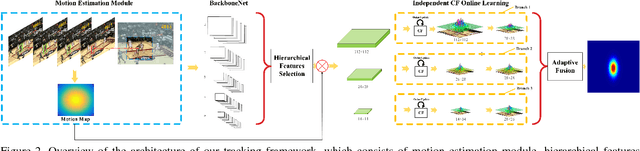

For visual tracking, most of the traditional correlation filters (CF) based methods suffer from the bottleneck of feature redundancy and lack of motion information. In this paper, we design a novel tracking framework, called multi-hierarchical independent correlation filters (MHIT). The framework consists of motion estimation module, hierarchical features selection, independent CF online learning, and adaptive multi-branch CF fusion. Specifically, the motion estimation module is introduced to capture motion information, which effectively alleviates the object partial occlusion in the temporal video. The multi-hierarchical deep features of CNN representing different semantic information can be fully excavated to track multi-scale objects. To better overcome the deep feature redundancy, each hierarchical features are independently fed into a single branch to implement the online learning of parameters. Finally, an adaptive weight scheme is integrated into the framework to fuse these independent multi-branch CFs for the better and more robust visual object tracking. Extensive experiments on OTB and VOT datasets show that the proposed MHIT tracker can significantly improve the tracking performance. Especially, it obtains a 20.1% relative performance gain compared to the top trackers on the VOT2017 challenge, and also achieves new state-of-the-art performance on the VOT2018 challenge.