 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICo3D: An Interactive Conversational 3D Virtual Human
Jan 19, 2026This work presents Interactive Conversational 3D Virtual Human (ICo3D), a method for generating an interactive, conversational, and photorealistic 3D human avatar. Based on multi-view captures of a subject, we create an animatable 3D face model and a dynamic 3D body model, both rendered by splatting Gaussian primitives. Once merged together, they represent a lifelike virtual human avatar suitable for real-time user interactions. We equip our avatar with an LLM for conversational ability. During conversation, the audio speech of the avatar is used as a driving signal to animate the face model, enabling precise synchronization. We describe improvements to our dynamic Gaussian models that enhance photorealism: SWinGS++ for body reconstruction and HeadGaS++ for face reconstruction, and provide as well a solution to merge the separate face and body models without artifacts. We also present a demo of the complete system, showcasing several use cases of real-time conversation with the 3D avatar. Our approach offers a fully integrated virtual avatar experience, supporting both oral and written form interactions in immersive environments. ICo3D is applicable to a wide range of fields, including gaming, virtual assistance, and personalized education, among others. Project page: https://ico3d.github.io/
Better Together: Unified Motion Capture and 3D Avatar Reconstruction
Mar 12, 2025We present Better Together, a method that simultaneously solves the human pose estimation problem while reconstructing a photorealistic 3D human avatar from multi-view videos. While prior art usually solves these problems separately, we argue that joint optimization of skeletal motion with a 3D renderable body model brings synergistic effects, i.e. yields more precise motion capture and improved visual quality of real-time rendering of avatars. To achieve this, we introduce a novel animatable avatar with 3D Gaussians rigged on a personalized mesh and propose to optimize the motion sequence with time-dependent MLPs that provide accurate and temporally consistent pose estimates. We first evaluate our method on highly challenging yoga poses and demonstrate state-of-the-art accuracy on multi-view human pose estimation, reducing error by 35% on body joints and 45% on hand joints compared to keypoint-based methods. At the same time, our method significantly boosts the visual quality of animatable avatars (+2dB PSNR on novel view synthesis) on diverse challenging subjects.
ILSH: The Imperial Light-Stage Head Dataset for Human Head View Synthesis
Oct 06, 2023



This paper introduces the Imperial Light-Stage Head (ILSH) dataset, a novel light-stage-captured human head dataset designed to support view synthesis academic challenges for human heads. The ILSH dataset is intended to facilitate diverse approaches, such as scene-specific or generic neural rendering, multiple-view geometry, 3D vision, and computer graphics, to further advance the development of photo-realistic human avatars. This paper details the setup of a light-stage specifically designed to capture high-resolution (4K) human head images and describes the process of addressing challenges (preprocessing, ethical issues) in collecting high-quality data. In addition to the data collection, we address the split of the dataset into train, validation, and test sets. Our goal is to design and support a fair view synthesis challenge task for this novel dataset, such that a similar level of performance can be maintained and expected when using the test set, as when using the validation set. The ILSH dataset consists of 52 subjects captured using 24 cameras with all 82 lighting sources turned on, resulting in a total of 1,248 close-up head images, border masks, and camera pose pairs.
Latent Disentanglement in Mesh Variational Autoencoders Improves the Diagnosis of Craniofacial Syndromes and Aids Surgical Planning
Sep 05, 2023



The use of deep learning to undertake shape analysis of the complexities of the human head holds great promise. However, there have traditionally been a number of barriers to accurate modelling, especially when operating on both a global and local level. In this work, we will discuss the application of the Swap Disentangled Variational Autoencoder (SD-VAE) with relevance to Crouzon, Apert and Muenke syndromes. Although syndrome classification is performed on the entire mesh, it is also possible, for the first time, to analyse the influence of each region of the head on the syndromic phenotype. By manipulating specific parameters of the generative model, and producing procedure-specific new shapes, it is also possible to simulate the outcome of a range of craniofacial surgical procedures. This opens new avenues to advance diagnosis, aids surgical planning and allows for the objective evaluation of surgical outcomes.
Synthesizing Coupled 3D Face Modalities by Trunk-Branch Generative Adversarial Networks
Sep 05, 2019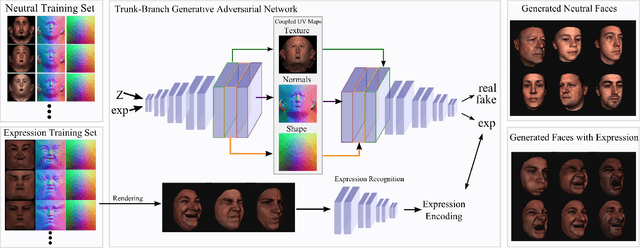
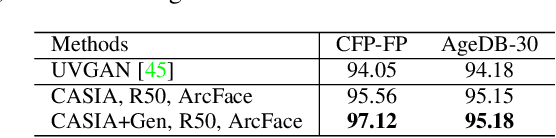


Generating realistic 3D faces is of high importance for computer graphics and computer vision applications. Generally, research on 3D face generation revolves around linear statistical models of the facial surface. Nevertheless, these models cannot represent faithfully either the facial texture or the normals of the face, which are very crucial for photo-realistic face synthesis. Recently, it was demonstrated that Generative Adversarial Networks (GANs) can be used for generating high-quality textures of faces. Nevertheless, the generation process either omits the geometry and normals, or independent processes are used to produce 3D shape information. In this paper, we present the first methodology that generates high-quality texture, shape, and normals jointly, which can be used for photo-realistic synthesis. To do so, we propose a novel GAN that can generate data from different modalities while exploiting their correlations. Furthermore, we demonstrate how we can condition the generation on the expression and create faces with various facial expressions. The qualitative results shown in this pre-print is compressed due to size limitations, full resolution results and the accompanying video can be found at the project page: https://github.com/barisgecer/TBGAN.
3DFaceGAN: Adversarial Nets for 3D Face Representation, Generation, and Translation
May 09, 2019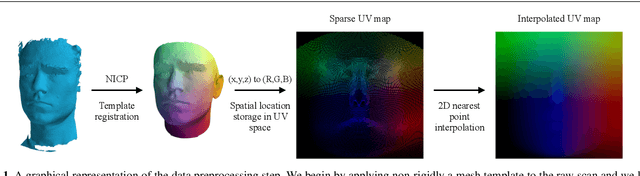
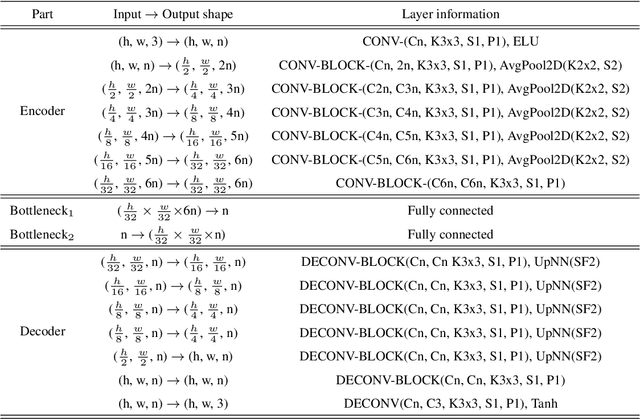


Over the past few years, Generative Adversarial Networks (GANs) have garnered increased interest among researchers in Computer Vision, with applications including, but not limited to, image generation, translation, imputation, and super-resolution. Nevertheless, no GAN-based method has been proposed in the literature that can successfully represent, generate or translate 3D facial shapes (meshes). This can be primarily attributed to two facts, namely that (a) publicly available 3D face databases are scarce as well as limited in terms of sample size and variability (e.g., few subjects, little diversity in race and gender), and (b) mesh convolutions for deep networks present several challenges that are not entirely tackled in the literature, leading to operator approximations and model instability, often failing to preserve high-frequency components of the distribution. As a result, linear methods such as Principal Component Analysis (PCA) have been mainly utilized towards 3D shape analysis, despite being unable to capture non-linearities and high frequency details of the 3D face - such as eyelid and lip variations. In this work, we present 3DFaceGAN, the first GAN tailored towards modeling the distribution of 3D facial surfaces, while retaining the high frequency details of 3D face shapes. We conduct an extensive series of both qualitative and quantitative experiments, where the merits of 3DFaceGAN are clearly demonstrated against other, state-of-the-art methods in tasks such as 3D shape representation, generation, and translation.
Synthesising 3D Facial Motion from "In-the-Wild" Speech
Apr 15, 2019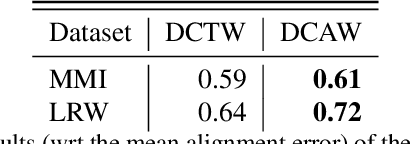
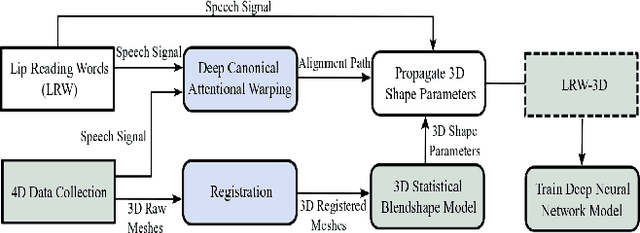

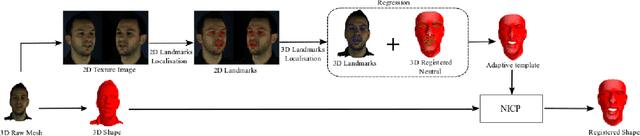
Synthesising 3D facial motion from speech is a crucial problem manifesting in a multitude of applications such as computer games and movies. Recently proposed methods tackle this problem in controlled conditions of speech. In this paper, we introduce the first methodology for 3D facial motion synthesis from speech captured in arbitrary recording conditions ("in-the-wild") and independent of the speaker. For our purposes, we captured 4D sequences of people uttering 500 words, contained in the Lip Reading Words (LRW) a publicly available large-scale in-the-wild dataset, and built a set of 3D blendshapes appropriate for speech. We correlate the 3D shape parameters of the speech blendshapes to the LRW audio samples by means of a novel time-warping technique, named Deep Canonical Attentional Warping (DCAW), that can simultaneously learn hierarchical non-linear representations and a warping path in an end-to-end manner. We thoroughly evaluate our proposed methods, and show the ability of a deep learning model to synthesise 3D facial motion in handling different speakers and continuous speech signals in uncontrolled conditions.
Deep Affect Prediction in-the-wild: Aff-Wild Database and Challenge, Deep Architectures, and Beyond
Sep 01, 2018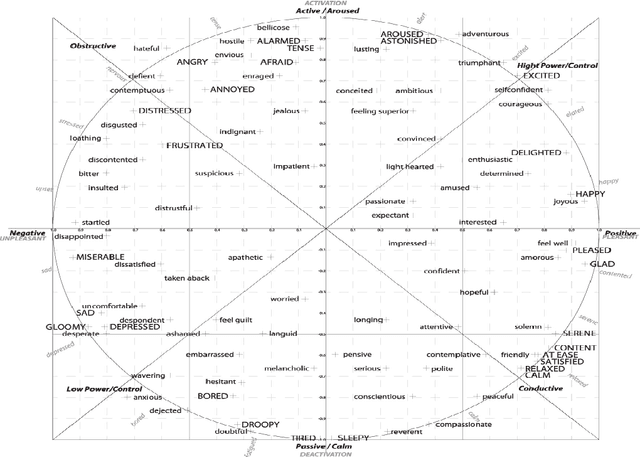
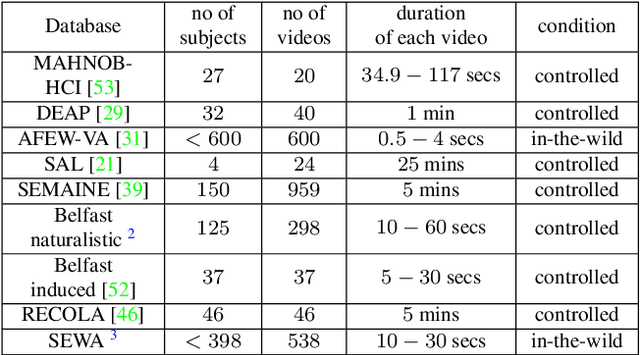
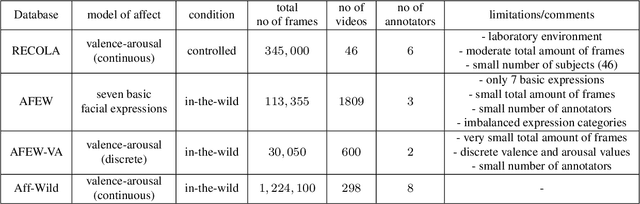

Automatic understanding of human affect using visual signals is of great importance in everyday human-machine interactions. Appraising human emotional states, behaviors and reactions displayed in real-world settings, can be accomplished using latent continuous dimensions (e.g., the circumplex model of affect). Valence (i.e., how positive or negative is an emotion) and arousal (i.e., power of the activation of the emotion) constitute the most popular and effective affect representations. Nevertheless, the majority of collected datasets this far, although containing naturalistic emotional states, have been captured in highly controlled recording conditions. In this paper, we introduce the Aff-Wild benchmark for training and evaluating affect recognition algorithms. We also report on the results of the First Affect-in-the-wild Challenge (Aff-Wild Challenge) that was recently organized on the Aff-Wild database, and was the first ever challenge on the estimation of valence and arousal in-the-wild. Furthermore, we design and extensively train an end-to-end deep neural architecture which performs prediction of continuous emotion dimensions based on visual cues. The proposed deep learning architecture, AffWildNet, includes convolutional and recurrent neural network (CNN-RNN) layers, exploiting the invariant properties of convolutional features, while also modeling temporal dynamics that arise in human behavior via the recurrent layers. The AffWildNet produced state-of-the-art results on the Aff-Wild Challenge. We then exploit the AffWild database for learning features, which can be used as priors for achieving best performances both for dimensional, as well as categorical emotion recognition, using the RECOLA, AFEW-VA and EmotiW 2017 datasets, compared to all other methods designed for the same goal.