 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Coupled 3D Face Modalities by Trunk-Branch Generative Adversarial Networks
Sep 05, 2019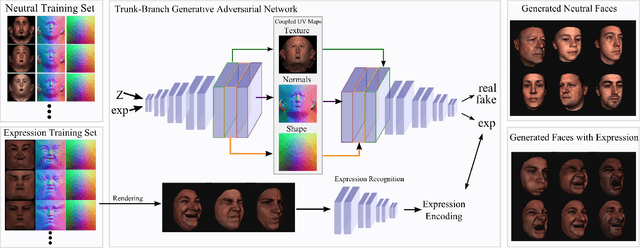
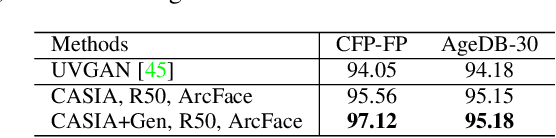


Generating realistic 3D faces is of high importance for computer graphics and computer vision applications. Generally, research on 3D face generation revolves around linear statistical models of the facial surface. Nevertheless, these models cannot represent faithfully either the facial texture or the normals of the face, which are very crucial for photo-realistic face synthesis. Recently, it was demonstrated that Generative Adversarial Networks (GANs) can be used for generating high-quality textures of faces. Nevertheless, the generation process either omits the geometry and normals, or independent processes are used to produce 3D shape information. In this paper, we present the first methodology that generates high-quality texture, shape, and normals jointly, which can be used for photo-realistic synthesis. To do so, we propose a novel GAN that can generate data from different modalities while exploiting their correlations. Furthermore, we demonstrate how we can condition the generation on the expression and create faces with various facial expressions. The qualitative results shown in this pre-print is compressed due to size limitations, full resolution results and the accompanying video can be found at the project page: https://github.com/barisgecer/TBGAN.
Synthesising 3D Facial Motion from "In-the-Wild" Speech
Apr 15, 2019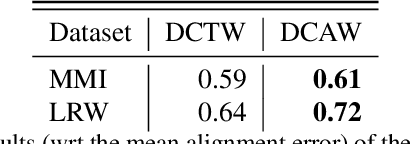
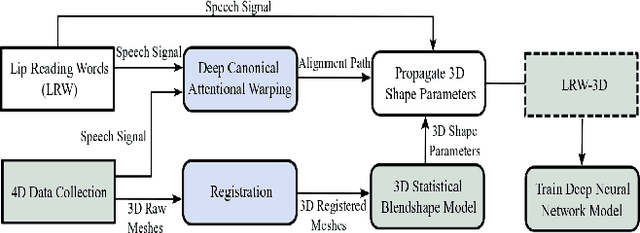

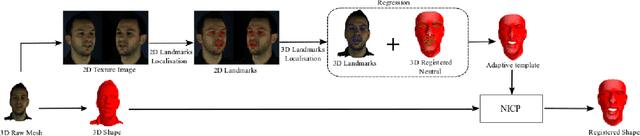
Synthesising 3D facial motion from speech is a crucial problem manifesting in a multitude of applications such as computer games and movies. Recently proposed methods tackle this problem in controlled conditions of speech. In this paper, we introduce the first methodology for 3D facial motion synthesis from speech captured in arbitrary recording conditions ("in-the-wild") and independent of the speaker. For our purposes, we captured 4D sequences of people uttering 500 words, contained in the Lip Reading Words (LRW) a publicly available large-scale in-the-wild dataset, and built a set of 3D blendshapes appropriate for speech. We correlate the 3D shape parameters of the speech blendshapes to the LRW audio samples by means of a novel time-warping technique, named Deep Canonical Attentional Warping (DCAW), that can simultaneously learn hierarchical non-linear representations and a warping path in an end-to-end manner. We thoroughly evaluate our proposed methods, and show the ability of a deep learning model to synthesise 3D facial motion in handling different speakers and continuous speech signals in uncontrolled conditions.