 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesising 3D Facial Motion from "In-the-Wild" Speech
Paper and Code
Apr 15, 2019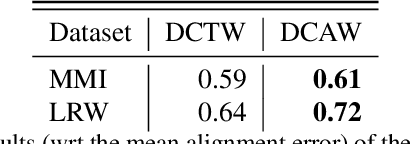
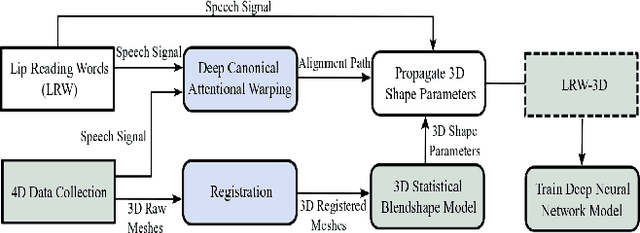

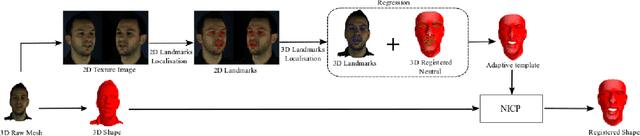
Synthesising 3D facial motion from speech is a crucial problem manifesting in a multitude of applications such as computer games and movies. Recently proposed methods tackle this problem in controlled conditions of speech. In this paper, we introduce the first methodology for 3D facial motion synthesis from speech captured in arbitrary recording conditions ("in-the-wild") and independent of the speaker. For our purposes, we captured 4D sequences of people uttering 500 words, contained in the Lip Reading Words (LRW) a publicly available large-scale in-the-wild dataset, and built a set of 3D blendshapes appropriate for speech. We correlate the 3D shape parameters of the speech blendshapes to the LRW audio samples by means of a novel time-warping technique, named Deep Canonical Attentional Warping (DCAW), that can simultaneously learn hierarchical non-linear representations and a warping path in an end-to-end manner. We thoroughly evaluate our proposed methods, and show the ability of a deep learning model to synthesise 3D facial motion in handling different speakers and continuous speech signals in uncontrolled conditions.