 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Disentanglement in Mesh Variational Autoencoders Improves the Diagnosis of Craniofacial Syndromes and Aids Surgical Planning
Sep 05, 2023The use of deep learning to undertake shape analysis of the complexities of the human head holds great promise. However, there have traditionally been a number of barriers to accurate modelling, especially when operating on both a global and local level. In this work, we will discuss the application of the Swap Disentangled Variational Autoencoder (SD-VAE) with relevance to Crouzon, Apert and Muenke syndromes. Although syndrome classification is performed on the entire mesh, it is also possible, for the first time, to analyse the influence of each region of the head on the syndromic phenotype. By manipulating specific parameters of the generative model, and producing procedure-specific new shapes, it is also possible to simulate the outcome of a range of craniofacial surgical procedures. This opens new avenues to advance diagnosis, aids surgical planning and allows for the objective evaluation of surgical outcomes.
Reconstructing Heterogeneous Cryo-EM Molecular Structures by Decomposing Them into Polymer Chains
Jun 12, 2023



Cryogenic electron microscopy (cryo-EM) has transformed structural biology by allowing to reconstruct 3D biomolecular structures up to near-atomic resolution. However, the 3D reconstruction process remains challenging, as the 3D structures may exhibit substantial shape variations, while the 2D image acquisition suffers from a low signal-to-noise ratio, requiring to acquire very large datasets that are time-consuming to process. Current reconstruction methods are precise but computationally expensive, or faster but lack a physically-plausible model of large molecular shape variations. To fill this gap, we propose CryoChains that encodes large deformations of biomolecules via rigid body transformation of their polymer instances (chains), while representing their finer shape variations with the normal mode analysis framework of biophysics. Our synthetic data experiments on the human $\text{GABA}_{\text{B}}$ and heat shock protein show that CryoChains gives a biophysically-grounded quantification of the heterogeneous conformations of biomolecules, while reconstructing their 3D molecular structures at an improved resolution compared to the current fastest, interpretable deep learning method.
3D Generative Model Latent Disentanglement via Local Eigenprojection
Feb 24, 2023Designing realistic digital humans is extremely complex. Most data-driven generative models used to simplify the creation of their underlying geometric shape do not offer control over the generation of local shape attributes. In this paper, we overcome this limitation by introducing a novel loss function grounded in spectral geometry and applicable to different neural-network-based generative models of 3D head and body meshes. Encouraging the latent variables of mesh variational autoencoders (VAEs) or generative adversarial networks (GANs) to follow the local eigenprojections of identity attributes, we improve latent disentanglement and properly decouple the attribute creation. Experimental results show that our local eigenprojection disentangled (LED) models not only offer improved disentanglement with respect to the state-of-the-art, but also maintain good generation capabilities with training times comparable to the vanilla implementations of the models.
Heterogeneous reconstruction of deformable atomic models in Cryo-EM
Sep 29, 2022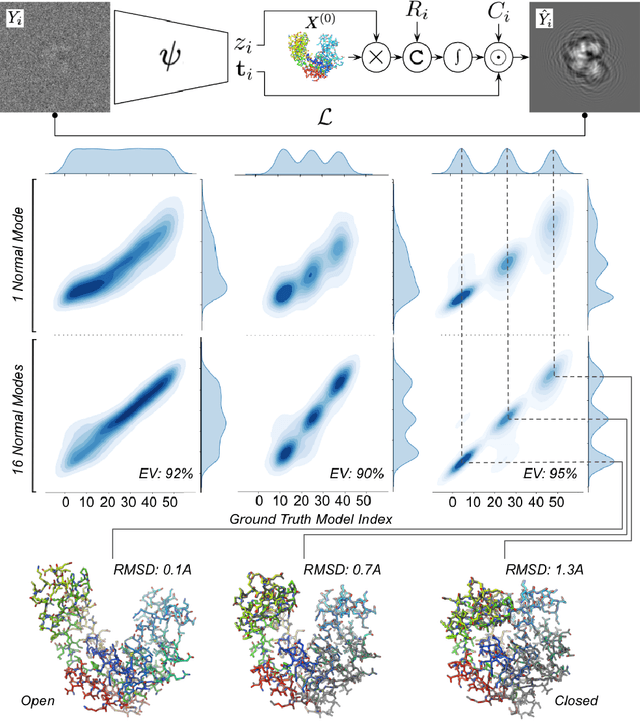
Cryogenic electron microscopy (cryo-EM) provides a unique opportunity to study the structural heterogeneity of biomolecules. Being able to explain this heterogeneity with atomic models would help our understanding of their functional mechanisms but the size and ruggedness of the structural space (the space of atomic 3D cartesian coordinates) presents an immense challenge. Here, we describe a heterogeneous reconstruction method based on an atomistic representation whose deformation is reduced to a handful of collective motions through normal mode analysis. Our implementation uses an autoencoder. The encoder jointly estimates the amplitude of motion along the normal modes and the 2D shift between the center of the image and the center of the molecule . The physics-based decoder aggregates a representation of the heterogeneity readily interpretable at the atomic level. We illustrate our method on 3 synthetic datasets corresponding to different distributions along a simulated trajectory of adenylate kinase transitioning from its open to its closed structures. We show for each distribution that our approach is able to recapitulate the intermediate atomic models with atomic-level accuracy.
3D Shape Variational Autoencoder Latent Disentanglement via Mini-Batch Feature Swapping for Bodies and Faces
Nov 25, 2021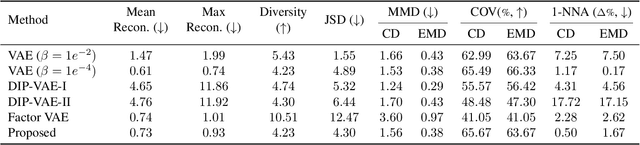
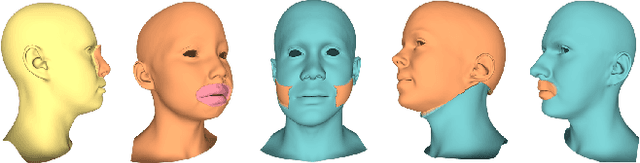

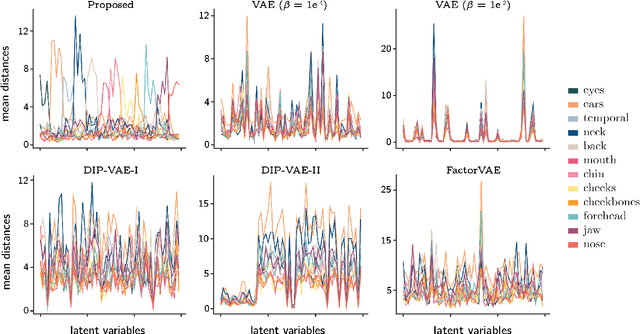
Learning a disentangled, interpretable, and structured latent representation in 3D generative models of faces and bodies is still an open problem. The problem is particularly acute when control over identity features is required. In this paper, we propose an intuitive yet effective self-supervised approach to train a 3D shape variational autoencoder (VAE) which encourages a disentangled latent representation of identity features. Curating the mini-batch generation by swapping arbitrary features across different shapes allows to define a loss function leveraging known differences and similarities in the latent representations. Experimental results conducted on 3D meshes show that state-of-the-art methods for latent disentanglement are not able to disentangle identity features of faces and bodies. Our proposed method properly decouples the generation of such features while maintaining good representation and reconstruction capabilities.
Intraoperative Liver Surface Completion with Graph Convolutional VAE
Sep 08, 2020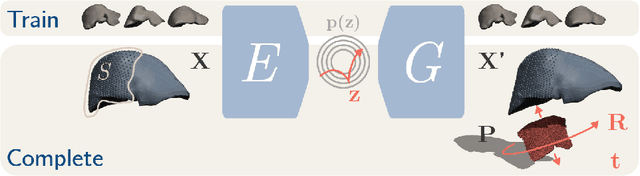

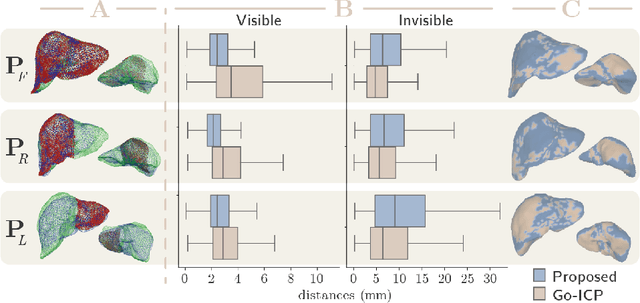
In this work we propose a method based on geometric deep learning to predict the complete surface of the liver, given a partial point cloud of the organ obtained during the surgical laparoscopic procedure. We introduce a new data augmentation technique that randomly perturbs shapes in their frequency domain to compensate the limited size of our dataset. The core of our method is a variational autoencoder (VAE) that is trained to learn a latent space for complete shapes of the liver. At inference time, the generative part of the model is embedded in an optimisation procedure where the latent representation is iteratively updated to generate a model that matches the intraoperative partial point cloud. The effect of this optimisation is a progressive non-rigid deformation of the initially generated shape. Our method is qualitatively evaluated on real data and quantitatively evaluated on synthetic data. We compared with a state-of-the-art rigid registration algorithm, that our method outperformed in visible areas.
More unlabelled data or label more data? A study on semi-supervised laparoscopic image segmentation
Aug 20, 2019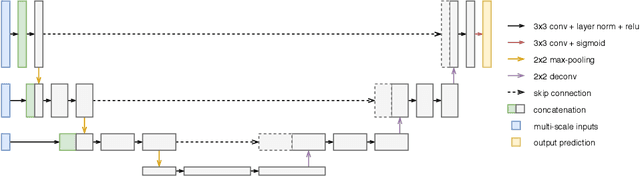
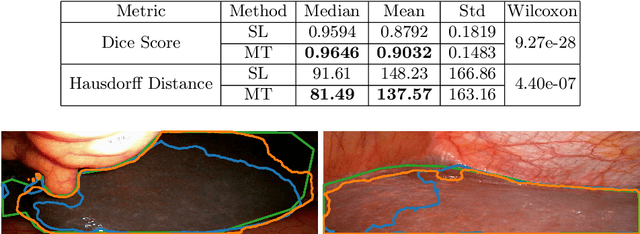
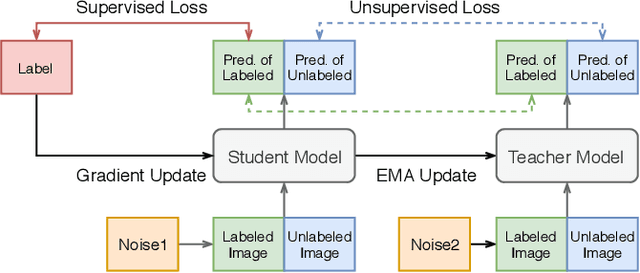
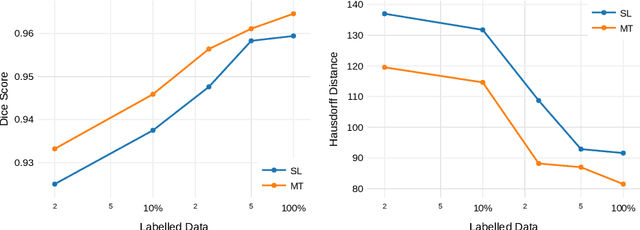
Improving a semi-supervised image segmentation task has the option of adding more unlabelled images, labelling the unlabelled images or combining both, as neither image acquisition nor expert labelling can be considered trivial in most clinical applications. With a laparoscopic liver image segmentation application, we investigate the performance impact by altering the quantities of labelled and unlabelled training data, using a semi-supervised segmentation algorithm based on the mean teacher learning paradigm. We first report a significantly higher segmentation accuracy, compared with supervised learning. Interestingly, this comparison reveals that the training strategy adopted in the semi-supervised algorithm is also responsible for this observed improvement, in addition to the added unlabelled data. We then compare different combinations of labelled and unlabelled data set sizes for training semi-supervised segmentation networks, to provide a quantitative example of the practically useful trade-off between the two data planning strategies in this surgical guidance application.