 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIllumination Histogram Consistency Metric for Quantitative Assessment of Video Sequences
May 15, 2024The advances in deep generative models have greatly accelerate the process of video procession such as video enhancement and synthesis. Learning spatio-temporal video models requires to capture the temporal dynamics of a scene, in addition to the visual appearance of individual frames. Illumination consistency, which reflects the variations of illumination in the dynamic video sequences, play a vital role in video processing. Unfortunately, to date, no well-accepted quantitative metric has been proposed for video illumination consistency evaluation. In this paper, we propose a illumination histogram consistency (IHC) metric to quantitatively and automatically evaluate the illumination consistency of the video sequences. IHC measures the illumination variation of any video sequence based on the illumination histogram discrepancies across all the frames in the video sequence. Specifically, given a video sequence, we first estimate the illumination map of each individual frame using the Retinex model; Then, using the illumination maps, the mean illumination histogram of the video sequence is computed by the mean operation across all the frames; Next, we compute the illumination histogram discrepancy between each individual frame and the mean illumination histogram and sum up all the illumination histogram discrepancies to represent the illumination variations of the video sequence. Finally, we obtain the IHC score from the illumination histogram discrepancies via normalization and subtraction operations. Experiments are conducted to illustrate the performance of the proposed IHC metric and its capability to measure the illumination variations in video sequences. The source code is available on \url{https://github.com/LongChenCV/IHC-Metric}.
Long-term Dependency for 3D Reconstruction of Freehand Ultrasound Without External Tracker
Oct 16, 2023Objective: Reconstructing freehand ultrasound in 3D without any external tracker has been a long-standing challenge in ultrasound-assisted procedures. We aim to define new ways of parameterising long-term dependencies, and evaluate the performance. Methods: First, long-term dependency is encoded by transformation positions within a frame sequence. This is achieved by combining a sequence model with a multi-transformation prediction. Second, two dependency factors are proposed, anatomical image content and scanning protocol, for contributing towards accurate reconstruction. Each factor is quantified experimentally by reducing respective training variances. Results: 1) The added long-term dependency up to 400 frames at 20 frames per second (fps) indeed improved reconstruction, with an up to 82.4% lowered accumulated error, compared with the baseline performance. The improvement was found to be dependent on sequence length, transformation interval and scanning protocol and, unexpectedly, not on the use of recurrent networks with long-short term modules; 2) Decreasing either anatomical or protocol variance in training led to poorer reconstruction accuracy. Interestingly, greater performance was gained from representative protocol patterns, than from representative anatomical features. Conclusion: The proposed algorithm uses hyperparameter tuning to effectively utilise long-term dependency. The proposed dependency factors are of practical significance in collecting diverse training data, regulating scanning protocols and developing efficient networks. Significance: The proposed new methodology with publicly available volunteer data and code for parametersing the long-term dependency, experimentally shown to be valid sources of performance improvement, which could potentially lead to better model development and practical optimisation of the reconstruction application.
Privileged Anatomical and Protocol Discrimination in Trackerless 3D Ultrasound Reconstruction
Aug 20, 2023Three-dimensional (3D) freehand ultrasound (US) reconstruction without using any additional external tracking device has seen recent advances with deep neural networks (DNNs). In this paper, we first investigated two identified contributing factors of the learned inter-frame correlation that enable the DNN-based reconstruction: anatomy and protocol. We propose to incorporate the ability to represent these two factors - readily available during training - as the privileged information to improve existing DNN-based methods. This is implemented in a new multi-task method, where the anatomical and protocol discrimination are used as auxiliary tasks. We further develop a differentiable network architecture to optimise the branching location of these auxiliary tasks, which controls the ratio between shared and task-specific network parameters, for maximising the benefits from the two auxiliary tasks. Experimental results, on a dataset with 38 forearms of 19 volunteers acquired with 6 different scanning protocols, show that 1) both anatomical and protocol variances are enabling factors for DNN-based US reconstruction; 2) learning how to discriminate different subjects (anatomical variance) and predefined types of scanning paths (protocol variance) both significantly improve frame prediction accuracy, volume reconstruction overlap, accumulated tracking error and final drift, using the proposed algorithm.
Trackerless freehand ultrasound with sequence modelling and auxiliary transformation over past and future frames
Nov 09, 2022



Three-dimensional (3D) freehand ultrasound (US) reconstruction without a tracker can be advantageous over its two-dimensional or tracked counterparts in many clinical applications. In this paper, we propose to estimate 3D spatial transformation between US frames from both past and future 2D images, using feed-forward and recurrent neural networks (RNNs). With the temporally available frames, a further multi-task learning algorithm is proposed to utilise a large number of auxiliary transformation-predicting tasks between them. Using more than 40,000 US frames acquired from 228 scans on 38 forearms of 19 volunteers in a volunteer study, the hold-out test performance is quantified by frame prediction accuracy, volume reconstruction overlap, accumulated tracking error and final drift, based on ground-truth from an optical tracker. The results show the importance of modelling the temporal-spatially correlated input frames as well as output transformations, with further improvement owing to additional past and/or future frames. The best performing model was associated with predicting transformation between moderately-spaced frames, with an interval of less than ten frames at 20 frames per second (fps). Little benefit was observed by adding frames more than one second away from the predicted transformation, with or without LSTM-based RNNs. Interestingly, with the proposed approach, explicit within-sequence loss that encourages consistency in composing transformations or minimises accumulated error may no longer be required. The implementation code and volunteer data will be made publicly available ensuring reproducibility and further research.
Intraoperative Liver Surface Completion with Graph Convolutional VAE
Sep 08, 2020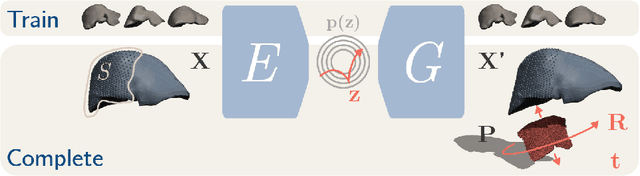

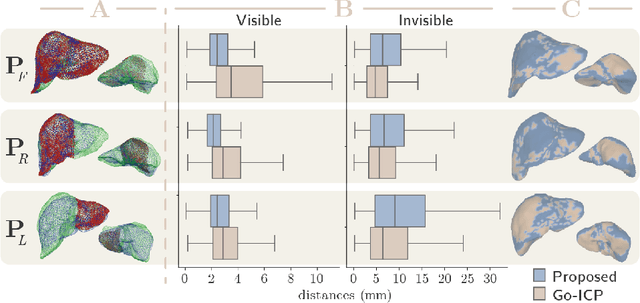
In this work we propose a method based on geometric deep learning to predict the complete surface of the liver, given a partial point cloud of the organ obtained during the surgical laparoscopic procedure. We introduce a new data augmentation technique that randomly perturbs shapes in their frequency domain to compensate the limited size of our dataset. The core of our method is a variational autoencoder (VAE) that is trained to learn a latent space for complete shapes of the liver. At inference time, the generative part of the model is embedded in an optimisation procedure where the latent representation is iteratively updated to generate a model that matches the intraoperative partial point cloud. The effect of this optimisation is a progressive non-rigid deformation of the initially generated shape. Our method is qualitatively evaluated on real data and quantitatively evaluated on synthetic data. We compared with a state-of-the-art rigid registration algorithm, that our method outperformed in visible areas.