 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Pose-invariant Lip-Reading
Paper and Code
Nov 14, 2019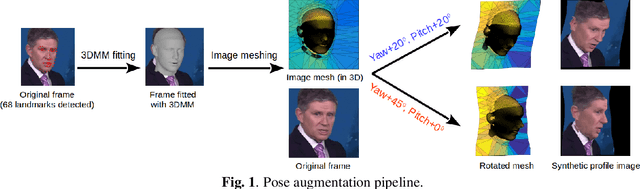
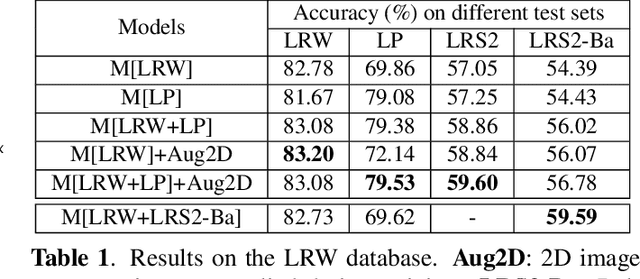
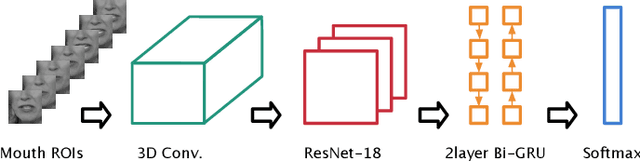
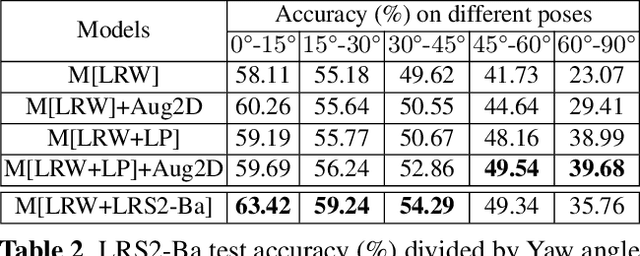
Lip-reading models have been significantly improved recently thanks to powerful deep learning architectures. However, most works focused on frontal or near frontal views of the mouth. As a consequence, lip-reading performance seriously deteriorates in non-frontal mouth views. In this work, we present a framework for training pose-invariant lip-reading models on synthetic data instead of collecting and annotating non-frontal data which is costly and tedious. The proposed model significantly outperforms previous approaches on non-frontal views while retaining the superior performance on frontal and near frontal mouth views. Specifically, we propose to use a 3D Morphable Model (3DMM) to augment LRW, an existing large-scale but mostly frontal dataset, by generating synthetic facial data in arbitrary poses. The newly derived dataset, is used to train a state-of-the-art neural network for lip-reading. We conducted a cross-database experiment for isolated word recognition on the LRS2 dataset, and reported an absolute improvement of 2.55%. The benefit of the proposed approach becomes clearer in extreme poses where an absolute improvement of up to 20.64% over the baseline is achieved.