 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Gaze Estimation from Synthetic Views
Dec 06, 20223D gaze estimation is most often tackled as learning a direct mapping between input images and the gaze vector or its spherical coordinates. Recently, it has been shown that pose estimation of the face, body and hands benefits from revising the learning target from few pose parameters to dense 3D coordinates. In this work, we leverage this observation and propose to tackle 3D gaze estimation as regression of 3D eye meshes. We overcome the absence of compatible ground truth by fitting a rigid 3D eyeball template on existing gaze datasets and propose to improve generalization by making use of widely available in-the-wild face images. To this end, we propose an automatic pipeline to retrieve robust gaze pseudo-labels from arbitrary face images and design a multi-view supervision framework to balance their effect during training. In our experiments, our method achieves improvement of 30% compared to state-of-the-art in cross-dataset gaze estimation, when no ground truth data are available for training, and 7% when they are. We make our project publicly available at https://github.com/Vagver/dense3Deyes.
Dynamic Neural Portraits
Nov 25, 2022



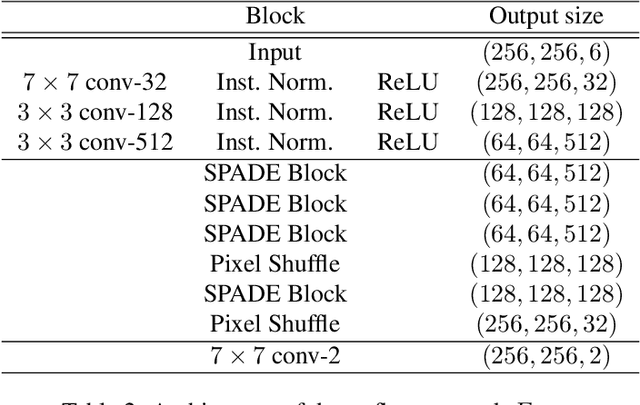
We present Dynamic Neural Portraits, a novel approach to the problem of full-head reenactment. Our method generates photo-realistic video portraits by explicitly controlling head pose, facial expressions and eye gaze. Our proposed architecture is different from existing methods that rely on GAN-based image-to-image translation networks for transforming renderings of 3D faces into photo-realistic images. Instead, we build our system upon a 2D coordinate-based MLP with controllable dynamics. Our intuition to adopt a 2D-based representation, as opposed to recent 3D NeRF-like systems, stems from the fact that video portraits are captured by monocular stationary cameras, therefore, only a single viewpoint of the scene is available. Primarily, we condition our generative model on expression blendshapes, nonetheless, we show that our system can be successfully driven by audio features as well. Our experiments demonstrate that the proposed method is 270 times faster than recent NeRF-based reenactment methods, with our networks achieving speeds of 24 fps for resolutions up to 1024 x 1024, while outperforming prior works in terms of visual quality.
Free-HeadGAN: Neural Talking Head Synthesis with Explicit Gaze Control
Aug 03, 2022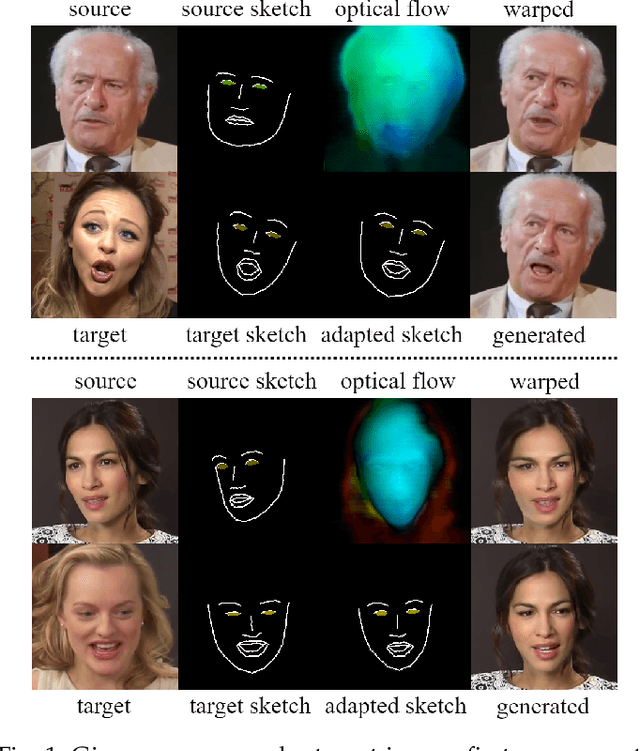
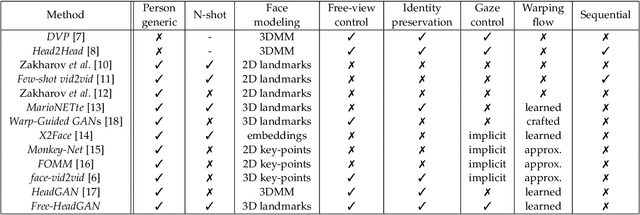
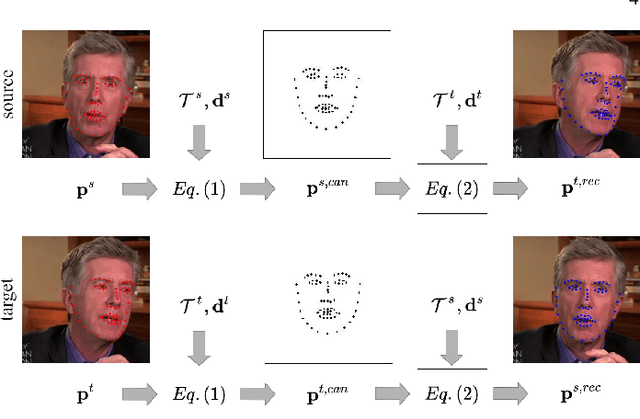
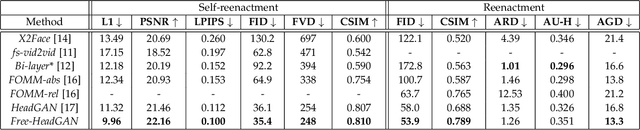
We present Free-HeadGAN, a person-generic neural talking head synthesis system. We show that modeling faces with sparse 3D facial landmarks are sufficient for achieving state-of-the-art generative performance, without relying on strong statistical priors of the face, such as 3D Morphable Models. Apart from 3D pose and facial expressions, our method is capable of fully transferring the eye gaze, from a driving actor to a source identity. Our complete pipeline consists of three components: a canonical 3D key-point estimator that regresses 3D pose and expression-related deformations, a gaze estimation network and a generator that is built upon the architecture of HeadGAN. We further experiment with an extension of our generator to accommodate few-shot learning using an attention mechanism, in case more than one source images are available. Compared to the latest models for reenactment and motion transfer, our system achieves higher photo-realism combined with superior identity preservation, while offering explicit gaze control.
Head2HeadFS: Video-based Head Reenactment with Few-shot Learning
Mar 30, 2021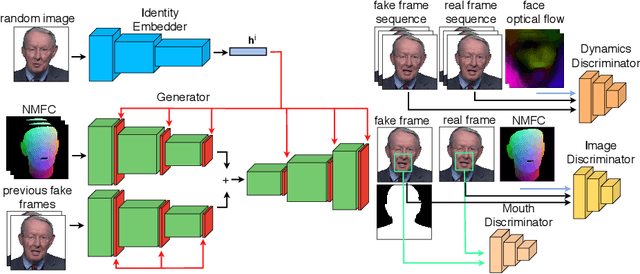


Over the past years, a substantial amount of work has been done on the problem of facial reenactment, with the solutions coming mainly from the graphics community. Head reenactment is an even more challenging task, which aims at transferring not only the facial expression, but also the entire head pose from a source person to a target. Current approaches either train person-specific systems, or use facial landmarks to model human heads, a representation that might transfer unwanted identity attributes from the source to the target. We propose head2headFS, a novel easily adaptable pipeline for head reenactment. We condition synthesis of the target person on dense 3D face shape information from the source, which enables high quality expression and pose transfer. Our video-based rendering network is fine-tuned under a few-shot learning strategy, using only a few samples. This allows for fast adaptation of a generic generator trained on a multiple-person dataset, into a person-specific one.
HeadGAN: Video-and-Audio-Driven Talking Head Synthesis
Dec 15, 2020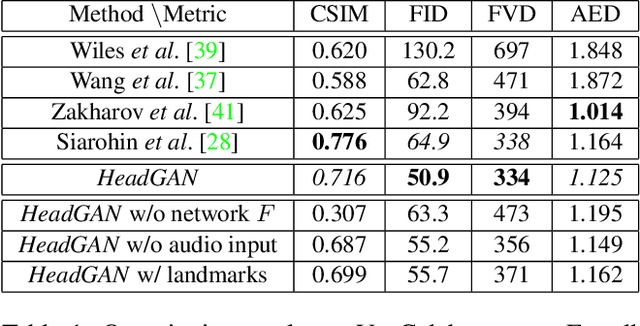
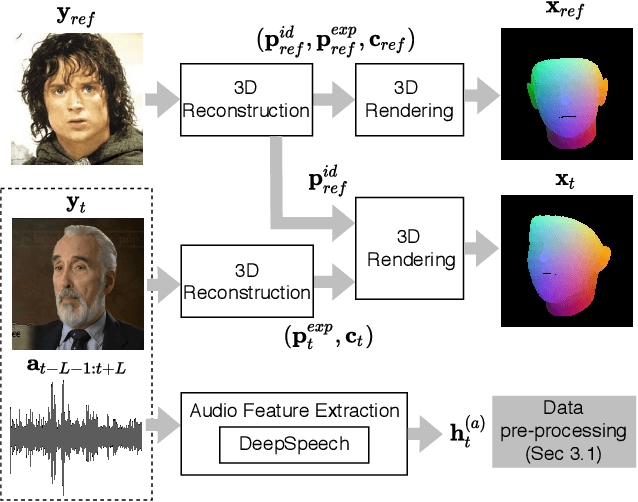
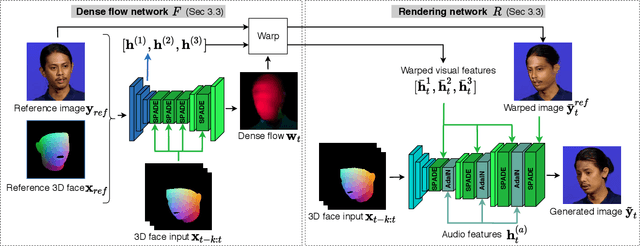
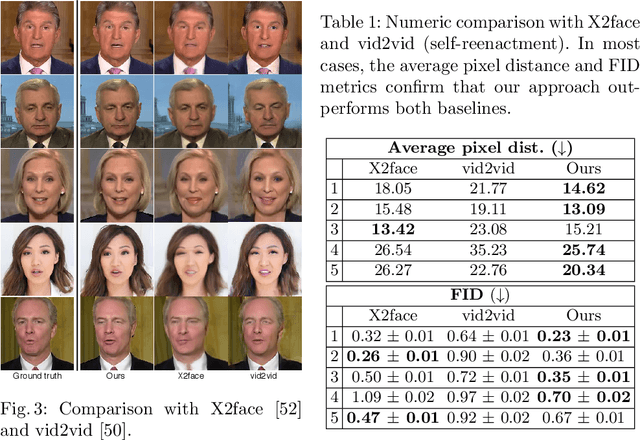
Recent attempts to solve the problem of talking head synthesis using a single reference image have shown promising results. However, most of them fail to meet the identity preservation problem, or perform poorly in terms of photo-realism, especially in extreme head poses. We propose HeadGAN, a novel reenactment approach that conditions synthesis on 3D face representations, which can be extracted from any driving video and adapted to the facial geometry of any source. We improve the plausibility of mouth movements, by utilising audio features as a complementary input to the Generator. Quantitative and qualitative experiments demonstrate the merits of our approach.
Head2Head++: Deep Facial Attributes Re-Targeting
Jun 17, 2020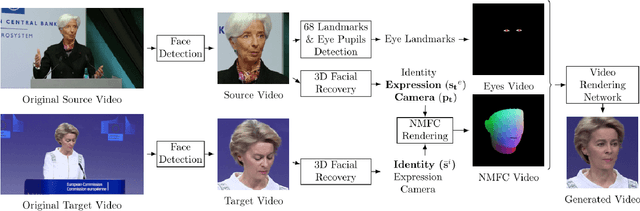
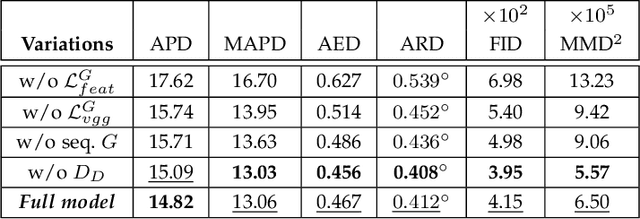

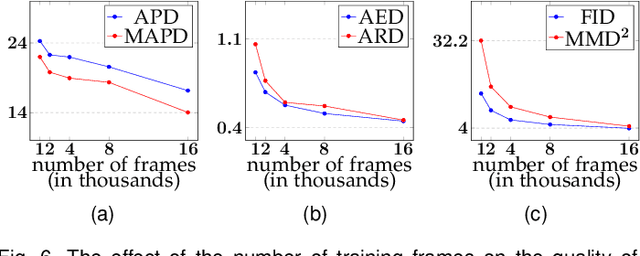
Facial video re-targeting is a challenging problem aiming to modify the facial attributes of a target subject in a seamless manner by a driving monocular sequence. We leverage the 3D geometry of faces and Generative Adversarial Networks (GANs) to design a novel deep learning architecture for the task of facial and head reenactment. Our method is different to purely 3D model-based approaches, or recent image-based methods that use Deep Convolutional Neural Networks (DCNNs) to generate individual frames. We manage to capture the complex non-rigid facial motion from the driving monocular performances and synthesise temporally consistent videos, with the aid of a sequential Generator and an ad-hoc Dynamics Discriminator network. We conduct a comprehensive set of quantitative and qualitative tests and demonstrate experimentally that our proposed method can successfully transfer facial expressions, head pose and eye gaze from a source video to a target subject, in a photo-realistic and faithful fashion, better than other state-of-the-art methods. Most importantly, our system performs end-to-end reenactment in nearly real-time speed (18 fps).
ReenactNet: Real-time Full Head Reenactment
May 22, 2020Video-to-video synthesis is a challenging problem aiming at learning a translation function between a sequence of semantic maps and a photo-realistic video depicting the characteristics of a driving video. We propose a head-to-head system of our own implementation capable of fully transferring the human head 3D pose, facial expressions and eye gaze from a source to a target actor, while preserving the identity of the target actor. Our system produces high-fidelity, temporally-smooth and photo-realistic synthetic videos faithfully transferring the human time-varying head attributes from the source to the target actor. Our proposed implementation: 1) works in real time ($\sim 20$ fps), 2) runs on a commodity laptop with a webcam as the only input, 3) is interactive, allowing the participant to drive a target person, e.g. a celebrity, politician, etc, instantly by varying their expressions, head pose, and eye gaze, and visualising the synthesised video concurrently.
Head2Head: Video-based Neural Head Synthesis
May 22, 2020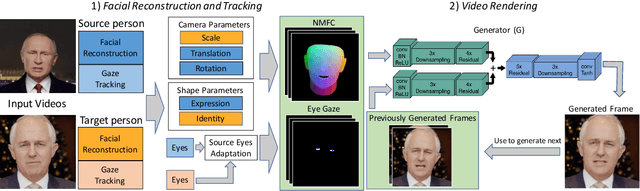

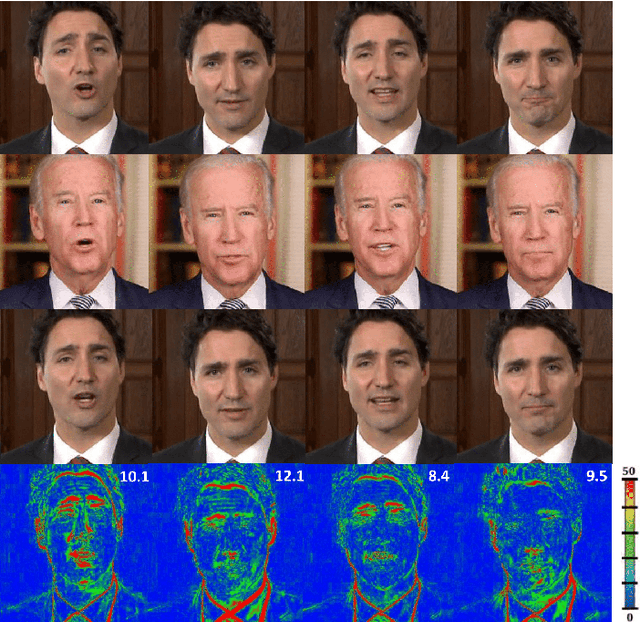

In this paper, we propose a novel machine learning architecture for facial reenactment. In particular, contrary to the model-based approaches or recent frame-based methods that use Deep Convolutional Neural Networks (DCNNs) to generate individual frames, we propose a novel method that (a) exploits the special structure of facial motion (paying particular attention to mouth motion) and (b) enforces temporal consistency. We demonstrate that the proposed method can transfer facial expressions, pose and gaze of a source actor to a target video in a photo-realistic fashion more accurately than state-of-the-art methods.