 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead2Head++: Deep Facial Attributes Re-Targeting
Paper and Code
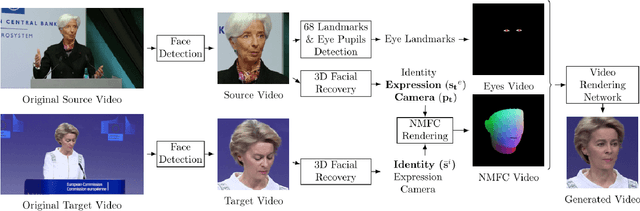
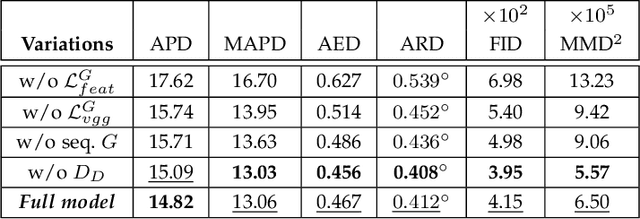

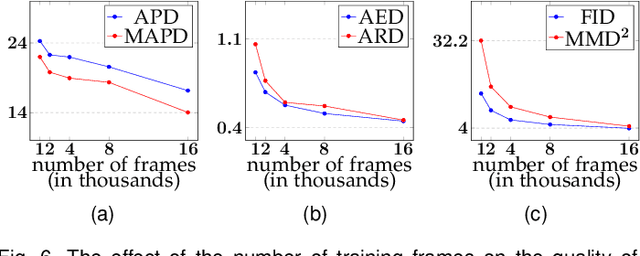
Facial video re-targeting is a challenging problem aiming to modify the facial attributes of a target subject in a seamless manner by a driving monocular sequence. We leverage the 3D geometry of faces and Generative Adversarial Networks (GANs) to design a novel deep learning architecture for the task of facial and head reenactment. Our method is different to purely 3D model-based approaches, or recent image-based methods that use Deep Convolutional Neural Networks (DCNNs) to generate individual frames. We manage to capture the complex non-rigid facial motion from the driving monocular performances and synthesise temporally consistent videos, with the aid of a sequential Generator and an ad-hoc Dynamics Discriminator network. We conduct a comprehensive set of quantitative and qualitative tests and demonstrate experimentally that our proposed method can successfully transfer facial expressions, head pose and eye gaze from a source video to a target subject, in a photo-realistic and faithful fashion, better than other state-of-the-art methods. Most importantly, our system performs end-to-end reenactment in nearly real-time speed (18 fps).