 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead2HeadFS: Video-based Head Reenactment with Few-shot Learning
Paper and Code
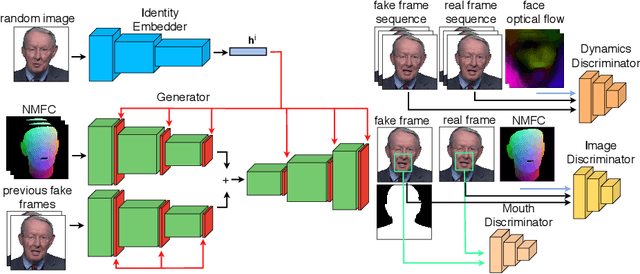
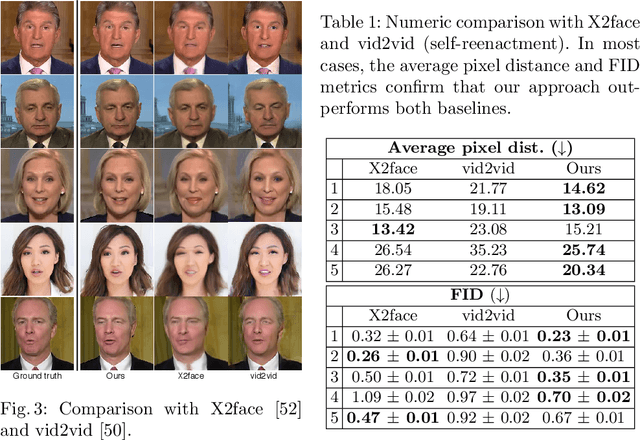


Over the past years, a substantial amount of work has been done on the problem of facial reenactment, with the solutions coming mainly from the graphics community. Head reenactment is an even more challenging task, which aims at transferring not only the facial expression, but also the entire head pose from a source person to a target. Current approaches either train person-specific systems, or use facial landmarks to model human heads, a representation that might transfer unwanted identity attributes from the source to the target. We propose head2headFS, a novel easily adaptable pipeline for head reenactment. We condition synthesis of the target person on dense 3D face shape information from the source, which enables high quality expression and pose transfer. Our video-based rendering network is fine-tuned under a few-shot learning strategy, using only a few samples. This allows for fast adaptation of a generic generator trained on a multiple-person dataset, into a person-specific one.