Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeadGAN: Video-and-Audio-Driven Talking Head Synthesis
Paper and Code
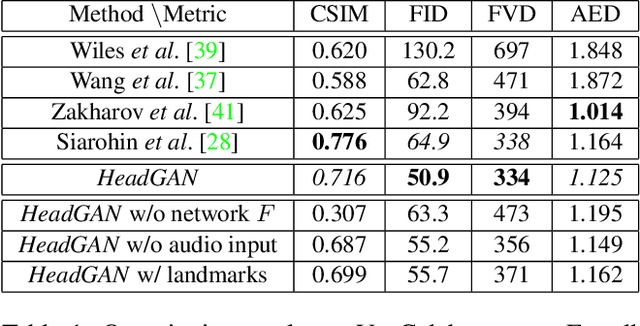
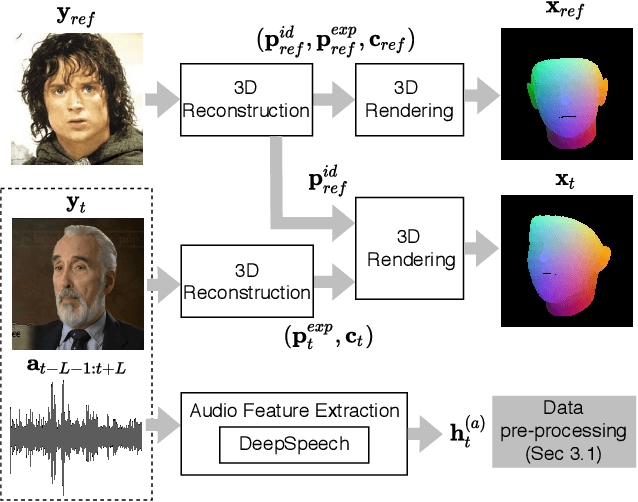
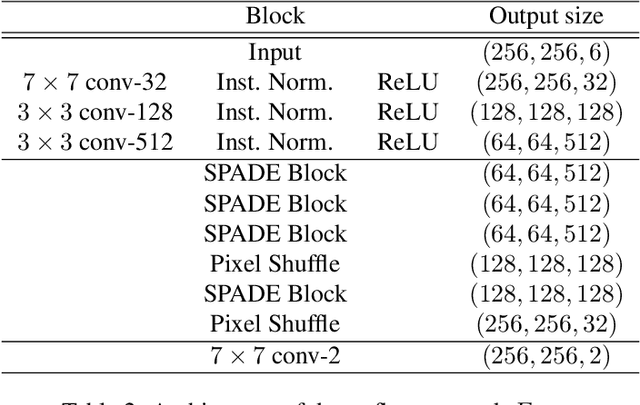
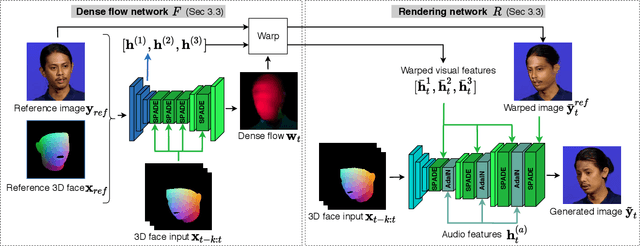
Recent attempts to solve the problem of talking head synthesis using a single reference image have shown promising results. However, most of them fail to meet the identity preservation problem, or perform poorly in terms of photo-realism, especially in extreme head poses. We propose HeadGAN, a novel reenactment approach that conditions synthesis on 3D face representations, which can be extracted from any driving video and adapted to the facial geometry of any source. We improve the plausibility of mouth movements, by utilising audio features as a complementary input to the Generator. Quantitative and qualitative experiments demonstrate the merits of our approach.
View paper on