 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Mechanism of Catastrophic Forgetting: A Perspective from Gradient Similarity
Jan 29, 2026Catastrophic forgetting during knowledge injection severely undermines the continual learning capability of large language models (LLMs). Although existing methods attempt to mitigate this issue, they often lack a foundational theoretical explanation. We establish a gradient-based theoretical framework to explain catastrophic forgetting. We first prove that strongly negative gradient similarity is a fundamental cause of forgetting. We then use gradient similarity to identify two types of neurons: conflicting neurons that induce forgetting and account for 50%-75% of neurons, and collaborative neurons that mitigate forgetting and account for 25%-50%. Based on this analysis, we propose a knowledge injection method, Collaborative Neural Learning (CNL). By freezing conflicting neurons and updating only collaborative neurons, CNL theoretically eliminates catastrophic forgetting under an infinitesimal learning rate eta and an exactly known mastered set. Experiments on five LLMs, four datasets, and four optimizers show that CNL achieves zero forgetting in in-set settings and reduces forgetting by 59.1%-81.7% in out-of-set settings.
CoScale-RL: Efficient Post-Training by Co-Scaling Data and Computation
Jan 21, 2026Training Large Reasoning Model (LRM) is usually unstable and unpredictable, especially on hard problems or weak foundation models. We found that the current post-training scaling strategy can still improve on these cases. We propose CoScale-RL, a novel scaling strategy with better data and computational efficiency. We first scale up solutions to make problems solvable. The core idea is to collect multiple solutions for each problem, rather than simply enlarging the dataset. Then, we scale up rollout computation to stabilize Reinforcement Learning. We further leverage a model merge technique called Re-distillation to sustain or even improve computational efficiency when scaling up. Our method significantly improves data and computational efficiency, with an average 3.76$\times$ accuracy improvement on four benchmarks. CoScale-RL is able to improve an LRM's ability boundary without an extensive SFT dataset. Our method provides a new scaling direction to further improve LRM's reasoning ability.
Rethinking the Value of Multi-Agent Workflow: A Strong Single Agent Baseline
Jan 18, 2026Recent advances in LLM-based multi-agent systems (MAS) show that workflows composed of multiple LLM agents with distinct roles, tools, and communication patterns can outperform single-LLM baselines on complex tasks. However, most frameworks are homogeneous, where all agents share the same base LLM and differ only in prompts, tools, and positions in the workflow. This raises the question of whether such workflows can be simulated by a single agent through multi-turn conversations. We investigate this across seven benchmarks spanning coding, mathematics, general question answering, domain-specific reasoning, and real-world planning and tool use. Our results show that a single agent can reach the performance of homogeneous workflows with an efficiency advantage from KV cache reuse, and can even match the performance of an automatically optimized heterogeneous workflow. Building on this finding, we propose \textbf{OneFlow}, an algorithm that automatically tailors workflows for single-agent execution, reducing inference costs compared to existing automatic multi-agent design frameworks without trading off accuracy. These results position the single-LLM implementation of multi-agent workflows as a strong baseline for MAS research. We also note that single-LLM methods cannot capture heterogeneous workflows due to the lack of KV cache sharing across different LLMs, highlighting future opportunities in developing \textit{truly} heterogeneous multi-agent systems.
ENTRA: Entropy-Based Redundancy Avoidance in Large Language Model Reasoning
Jan 12, 2026Large Reasoning Models (LRMs) often suffer from overthinking, generating unnecessarily long reasoning chains even for simple tasks. This leads to substantial computational overhead with limited performance gain, primarily due to redundant verification and repetitive generation. While prior work typically constrains output length or optimizes correctness, such coarse supervision fails to guide models toward concise yet accurate inference. In this paper, we propose ENTRA, an entropy-based training framework that suppresses redundant reasoning while preserving performance. ENTRA first estimates the token-level importance using a lightweight Bidirectional Importance Estimation (BIE) method, which accounts for both prediction confidence and forward influence. It then computes a redundancy reward based on the entropy of low-importance tokens, normalized by its theoretical upper bound, and optimizes this reward via reinforcement learning. Experiments on mathematical reasoning benchmarks demonstrate that ENTRA reduces output length by 37% to 53% with no loss-and in some cases, gains-in accuracy. Our approach offers a principled and efficient solution to reduce overthinking in LRMs, and provides a generalizable path toward redundancy-aware reasoning optimization.
Towards Effective Model Editing for LLM Personalization
Dec 15, 2025Personalization is becoming indispensable for LLMs to align with individual user preferences and needs. Yet current approaches are often computationally expensive, data-intensive, susceptible to catastrophic forgetting, and prone to performance degradation in multi-turn interactions or when handling implicit queries. To address these challenges, we conceptualize personalization as a model editing task and introduce Personalization Editing, a framework that applies localized edits guided by clustered preference representations. This design enables precise preference-aligned updates while preserving overall model capabilities. In addition, existing personalization benchmarks frequently rely on persona-based dialogs between LLMs rather than user-LLM interactions, or focus primarily on stylistic imitation while neglecting information-seeking tasks that require accurate recall of user-specific preferences. We introduce User Preference Question Answering (UPQA), a short-answer QA dataset constructed from in-situ user queries with varying levels of difficulty. Unlike prior benchmarks, UPQA directly evaluates a model's ability to recall and apply specific user preferences. Across experimental settings, Personalization Editing achieves higher editing accuracy and greater computational efficiency than fine-tuning, while outperforming prompting-based baselines in multi-turn conversations and implicit preference questions settings.
Joint Frequency-Space Sparse Reconstruction for DOA Estimation under Coherent Sources and Amplitude-Phase Errors
Sep 04, 2025
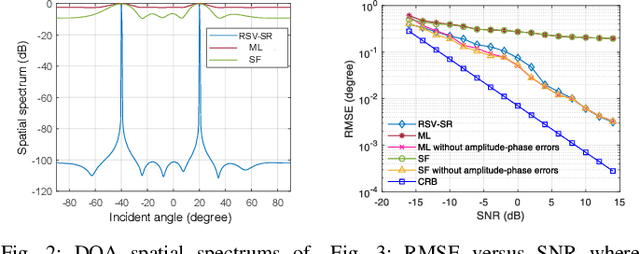
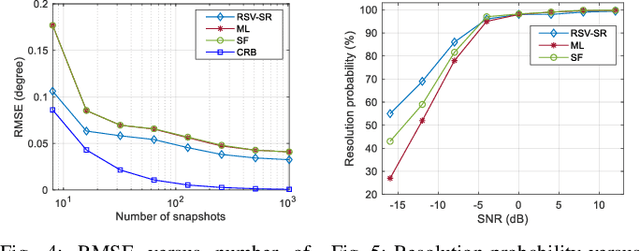
In this letter, we propose a joint frequency-space sparse reconstruction method for direction-of-arrival (DOA) estimation, which effectively addresses the issues arising from the existence of coherent sources and array amplitude-phase errors. Specifically, by using an auxiliary source with known angles, we first construct the real steering vectors (RSVs) based on the spectral peaks of received signals in the frequency domain, which serve as a complete basis matrix for compensation for amplitude-phase errors. Then, we leverage the spectral sparsity of snapshot data in the frequency domain and the spatial sparsity of incident directions to perform the DOA estimation according to the sparse reconstruction method. The proposed method does not require iterative optimization, hence exhibiting low computational complexity. Numerical results demonstrate that the proposed DOA estimation method achieves higher estimation accuracy for coherent sources as compared to various benchmark schemes.
EgoM2P: Egocentric Multimodal Multitask Pretraining
Jun 09, 2025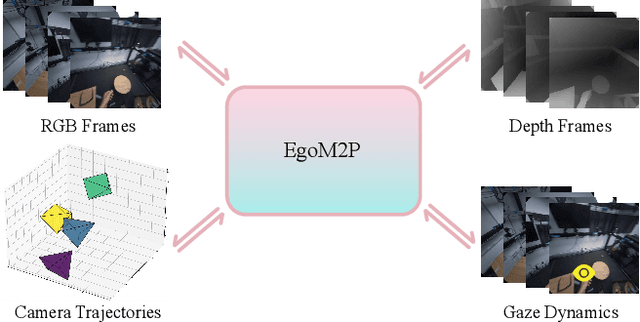

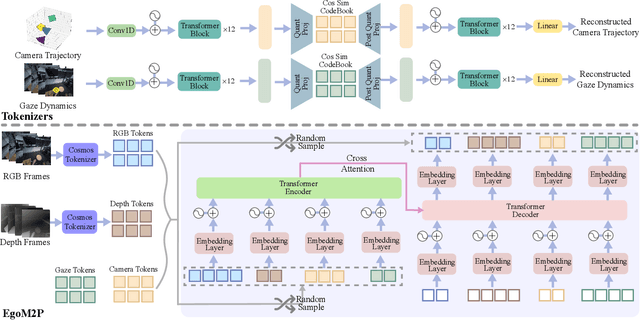
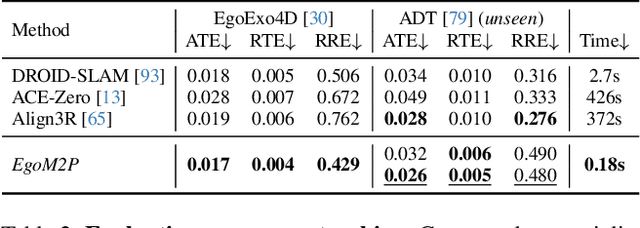
Understanding multimodal signals in egocentric vision, such as RGB video, depth, camera poses, and gaze, is essential for applications in augmented reality, robotics, and human-computer interaction. These capabilities enable systems to better interpret the camera wearer's actions, intentions, and surrounding environment. However, building large-scale egocentric multimodal and multitask models presents unique challenges. Egocentric data are inherently heterogeneous, with large variations in modality coverage across devices and settings. Generating pseudo-labels for missing modalities, such as gaze or head-mounted camera trajectories, is often infeasible, making standard supervised learning approaches difficult to scale. Furthermore, dynamic camera motion and the complex temporal and spatial structure of first-person video pose additional challenges for the direct application of existing multimodal foundation models. To address these challenges, we introduce a set of efficient temporal tokenizers and propose EgoM2P, a masked modeling framework that learns from temporally aware multimodal tokens to train a large, general-purpose model for egocentric 4D understanding. This unified design supports multitasking across diverse egocentric perception and synthesis tasks, including gaze prediction, egocentric camera tracking, and monocular depth estimation from egocentric video. EgoM2P also serves as a generative model for conditional egocentric video synthesis. Across these tasks, EgoM2P matches or outperforms specialist models while being an order of magnitude faster. We will fully open-source EgoM2P to support the community and advance egocentric vision research. Project page: https://egom2p.github.io/
Towards Revealing the Effectiveness of Small-Scale Fine-tuning in R1-style Reinforcement Learning
May 23, 2025



R1-style Reinforcement Learning (RL) significantly enhances Large Language Models' reasoning capabilities, yet the mechanism behind rule-based RL remains unclear. We found that small-scale SFT has significant influence on RL but shows poor efficiency. To explain our observations, we propose an analytical framework and compare the efficiency of SFT and RL by measuring sample effect. Hypothetical analysis show that SFT efficiency is limited by training data. Guided by our analysis, we propose Re-distillation, a technique that fine-tunes pretrain model through small-scale distillation from the RL-trained policy. Experiments on Knight & Knave and MATH datasets demonstrate re-distillation's surprising efficiency: re-distilled models match RL performance with far fewer samples and less computation. Empirical verification shows that sample effect is a good indicator of performance improvements. As a result, on K&K dataset, our re-distilled Qwen2.5-1.5B model surpasses DeepSeek-V3-0324 with only 1K SFT samples. On MATH, Qwen2.5-1.5B fine-tuned with re-distilled 500 samples matches its instruct-tuned variant without RL. Our work explains several interesting phenomena in R1-style RL, shedding light on the mechanisms behind its empirical success. Code is available at: https://github.com/on1262/deep-reasoning
Development of Low-Cost IoT Units for Thermal Comfort Measurement and AC Energy Consumption Prediction System
Nov 29, 2024



In response to the substantial energy consumption in buildings, the Japanese government initiated the BI-Tech (Behavioral Insights X Technology) project in 2019, aimed at promoting voluntary energy-saving behaviors through the utilization of AI and IoT technologies. Our study aimed at small and medium-sized office buildings introduces a cost-effective IoT-based BI-Tech system, utilizing the Raspberry Pi 4B+ platform for real-time monitoring of indoor thermal conditions and air conditioner (AC) set-point temperature. Employing machine learning and image recognition, the system analyzes data to calculate the PMV index and predict energy consumption changes due to temperature adjustments. The integration of mobile and desktop applications conveys this information to users, encouraging energy-efficient behavior modifications. The machine learning model achieved with an R2 value of 97%, demonstrating the system's efficiency in promoting energy-saving habits among users.
SplatFormer: Point Transformer for Robust 3D Gaussian Splatting
Nov 12, 2024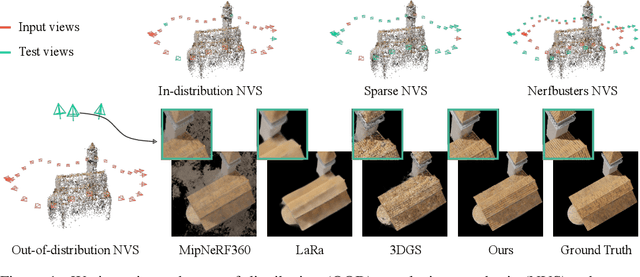
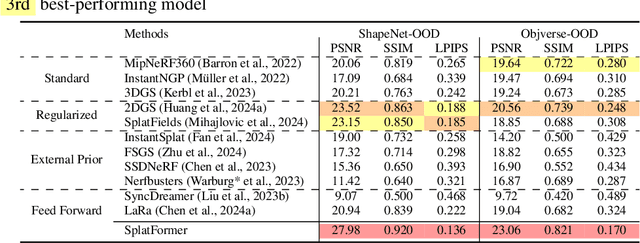
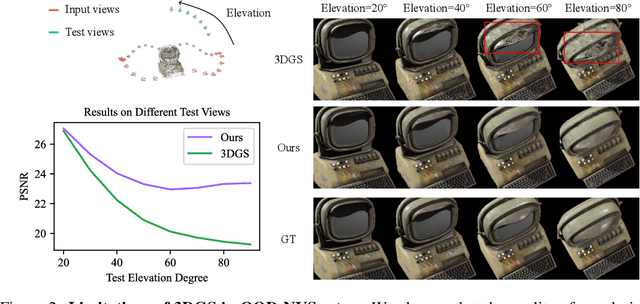
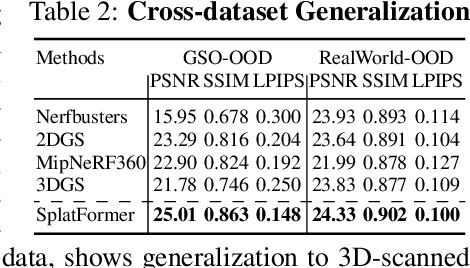
3D Gaussian Splatting (3DGS) has recently transformed photorealistic reconstruction, achieving high visual fidelity and real-time performance. However, rendering quality significantly deteriorates when test views deviate from the camera angles used during training, posing a major challenge for applications in immersive free-viewpoint rendering and navigation. In this work, we conduct a comprehensive evaluation of 3DGS and related novel view synthesis methods under out-of-distribution (OOD) test camera scenarios. By creating diverse test cases with synthetic and real-world datasets, we demonstrate that most existing methods, including those incorporating various regularization techniques and data-driven priors, struggle to generalize effectively to OOD views. To address this limitation, we introduce SplatFormer, the first point transformer model specifically designed to operate on Gaussian splats. SplatFormer takes as input an initial 3DGS set optimized under limited training views and refines it in a single forward pass, effectively removing potential artifacts in OOD test views. To our knowledge, this is the first successful application of point transformers directly on 3DGS sets, surpassing the limitations of previous multi-scene training methods, which could handle only a restricted number of input views during inference. Our model significantly improves rendering quality under extreme novel views, achieving state-of-the-art performance in these challenging scenarios and outperforming various 3DGS regularization techniques, multi-scene models tailored for sparse view synthesis, and diffusion-based frameworks.