 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolution of Tool Use in LLM Agents: From Single-Tool Call to Multi-Tool Orchestration
Mar 24, 2026Tool use enables large language models (LLMs) to access external information, invoke software systems, and act in digital environments beyond what can be solved from model parameters alone. Early research mainly studied whether a model could select and execute a correct single tool call. As agent systems evolve, however, the central problem has shifted from isolated invocation to multi-tool orchestration over long trajectories with intermediate state, execution feedback, changing environments, and practical constraints such as safety, cost, and verifiability. We comprehensively review recent progress in multi-tool LLM agents and analyzes the state of the art in this rapidly developing area. First, we unify task formulations and distinguish single-call tool use from long-horizon orchestration. Then, we organize the literature around six core dimensions: inference-time planning and execution, training and trajectory construction, safety and control, efficiency under resource constraints, capability completeness in open environments, and benchmark design and evaluation. We further summarize representative applications in software engineering, enterprise workflows, graphical user interfaces, and mobile systems. Finally, we discuss major challenges and outline future directions for building reliable, scalable, and verifiable multi-tool agents.
Graph Reasoning Paradigm: Structured and Symbolic Reasoning with Topology-Aware Reinforcement Learning for Large Language Models
Jan 19, 2026Long Chain-of-Thought (LCoT), achieved by Reinforcement Learning with Verifiable Rewards (RLVR), has proven effective in enhancing the reasoning capabilities of Large Language Models (LLMs). However, reasoning in current LLMs is primarily generated as plain text, where performing semantic evaluation on such unstructured data creates a computational bottleneck during training. Despite RLVR-based optimization, existing methods still suffer from coarse-grained supervision, reward hacking, high training costs, and poor generalization. To address these issues, we propose the Graph Reasoning Paradigm (GRP), which realizes structured and symbolic reasoning, implemented via graph-structured representations with step-level cognitive labels. Building upon GRP, we further design Process-Aware Stratified Clipping Group Relative Policy Optimization (PASC-GRPO), which leverages structured evaluation to replace semantic evaluation, achieves process-aware verification through graph-structured outcome rewards, and mitigates reward hacking via stratified clipping advantage estimation. Experiments demonstrate significant improvements across mathematical reasoning and code generation tasks. Data, models, and code will be released later.
Analyzing Reasoning Consistency in Large Multimodal Models under Cross-Modal Conflicts
Jan 07, 2026Large Multimodal Models (LMMs) have demonstrated impressive capabilities in video reasoning via Chain-of-Thought (CoT). However, the robustness of their reasoning chains remains questionable. In this paper, we identify a critical failure mode termed textual inertia, where once a textual hallucination occurs in the thinking process, models tend to blindly adhere to the erroneous text while neglecting conflicting visual evidence. To systematically investigate this, we propose the LogicGraph Perturbation Protocol that structurally injects perturbations into the reasoning chains of diverse LMMs spanning both native reasoning architectures and prompt-driven paradigms to evaluate their self-reflection capabilities. The results reveal that models successfully self-correct in less than 10% of cases and predominantly succumb to blind textual error propagation. To mitigate this, we introduce Active Visual-Context Refinement, a training-free inference paradigm which orchestrates an active visual re-grounding mechanism to enforce fine-grained verification coupled with an adaptive context refinement strategy to summarize and denoise the reasoning history. Experiments demonstrate that our approach significantly stifles hallucination propagation and enhances reasoning robustness.
AI Meets Brain: Memory Systems from Cognitive Neuroscience to Autonomous Agents
Dec 29, 2025Memory serves as the pivotal nexus bridging past and future, providing both humans and AI systems with invaluable concepts and experience to navigate complex tasks. Recent research on autonomous agents has increasingly focused on designing efficient memory workflows by drawing on cognitive neuroscience. However, constrained by interdisciplinary barriers, existing works struggle to assimilate the essence of human memory mechanisms. To bridge this gap, we systematically synthesizes interdisciplinary knowledge of memory, connecting insights from cognitive neuroscience with LLM-driven agents. Specifically, we first elucidate the definition and function of memory along a progressive trajectory from cognitive neuroscience through LLMs to agents. We then provide a comparative analysis of memory taxonomy, storage mechanisms, and the complete management lifecycle from both biological and artificial perspectives. Subsequently, we review the mainstream benchmarks for evaluating agent memory. Additionally, we explore memory security from dual perspectives of attack and defense. Finally, we envision future research directions, with a focus on multimodal memory systems and skill acquisition.
Self-Critique Guided Iterative Reasoning for Multi-hop Question Answering
May 25, 2025Although large language models (LLMs) have demonstrated remarkable reasoning capabilities, they still face challenges in knowledge-intensive multi-hop reasoning. Recent work explores iterative retrieval to address complex problems. However, the lack of intermediate guidance often results in inaccurate retrieval and flawed intermediate reasoning, leading to incorrect reasoning. To address these, we propose Self-Critique Guided Iterative Reasoning (SiGIR), which uses self-critique feedback to guide the iterative reasoning process. Specifically, through end-to-end training, we enable the model to iteratively address complex problems via question decomposition. Additionally, the model is able to self-evaluate its intermediate reasoning steps. During iterative reasoning, the model engages in branching exploration and employs self-evaluation to guide the selection of promising reasoning trajectories. Extensive experiments on three multi-hop reasoning datasets demonstrate the effectiveness of our proposed method, surpassing the previous SOTA by $8.6\%$. Furthermore, our thorough analysis offers insights for future research. Our code, data, and models are available at Github: https://github.com/zchuz/SiGIR-MHQA.
Investigating and Enhancing the Robustness of Large Multimodal Models Against Temporal Inconsistency
May 20, 2025Large Multimodal Models (LMMs) have recently demonstrated impressive performance on general video comprehension benchmarks. Nevertheless, for broader applications, the robustness of their temporal analysis capability needs to be thoroughly investigated yet predominantly ignored. Motivated by this, we propose a novel temporal robustness benchmark (TemRobBench), which introduces temporal inconsistency perturbations separately at the visual and textual modalities to assess the robustness of models. We evaluate 16 mainstream LMMs and find that they exhibit over-reliance on prior knowledge and textual context in adversarial environments, while ignoring the actual temporal dynamics in the video. To mitigate this issue, we design panoramic direct preference optimization (PanoDPO), which encourages LMMs to incorporate both visual and linguistic feature preferences simultaneously. Experimental results show that PanoDPO can effectively enhance the model's robustness and reliability in temporal analysis.
From Specific-MLLM to Omni-MLLM: A Survey about the MLLMs alligned with Multi-Modality
Dec 16, 2024



From the Specific-MLLM, which excels in single-modal tasks, to the Omni-MLLM, which extends the range of general modalities, this evolution aims to achieve understanding and generation of multimodal information. Omni-MLLM treats the features of different modalities as different "foreign languages," enabling cross-modal interaction and understanding within a unified space. To promote the advancement of related research, we have compiled 47 relevant papers to provide the community with a comprehensive introduction to Omni-MLLM. We first explain the four core components of Omni-MLLM for unified modeling and interaction of multiple modalities. Next, we introduce the effective integration achieved through "alignment pretraining" and "instruction fine-tuning," and discuss open-source datasets and testing of interaction capabilities. Finally, we summarize the main challenges facing current Omni-MLLM and outline future directions.
GUIDE: A Guideline-Guided Dataset for Instructional Video Comprehension
Jun 26, 2024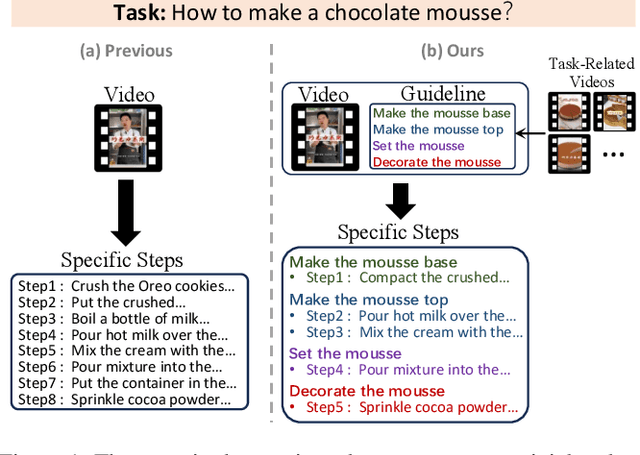

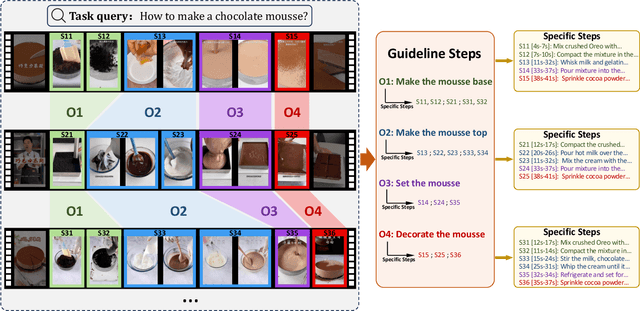

There are substantial instructional videos on the Internet, which provide us tutorials for completing various tasks. Existing instructional video datasets only focus on specific steps at the video level, lacking experiential guidelines at the task level, which can lead to beginners struggling to learn new tasks due to the lack of relevant experience. Moreover, the specific steps without guidelines are trivial and unsystematic, making it difficult to provide a clear tutorial. To address these problems, we present the GUIDE (Guideline-Guided) dataset, which contains 3.5K videos of 560 instructional tasks in 8 domains related to our daily life. Specifically, we annotate each instructional task with a guideline, representing a common pattern shared by all task-related videos. On this basis, we annotate systematic specific steps, including their associated guideline steps, specific step descriptions and timestamps. Our proposed benchmark consists of three sub-tasks to evaluate comprehension ability of models: (1) Step Captioning: models have to generate captions for specific steps from videos. (2) Guideline Summarization: models have to mine the common pattern in task-related videos and summarize a guideline from them. (3) Guideline-Guided Captioning: models have to generate captions for specific steps under the guide of guideline. We evaluate plenty of foundation models with GUIDE and perform in-depth analysis. Given the diversity and practicality of GUIDE, we believe that it can be used as a better benchmark for instructional video comprehension.
MTGER: Multi-view Temporal Graph Enhanced Temporal Reasoning over Time-Involved Document
Nov 08, 2023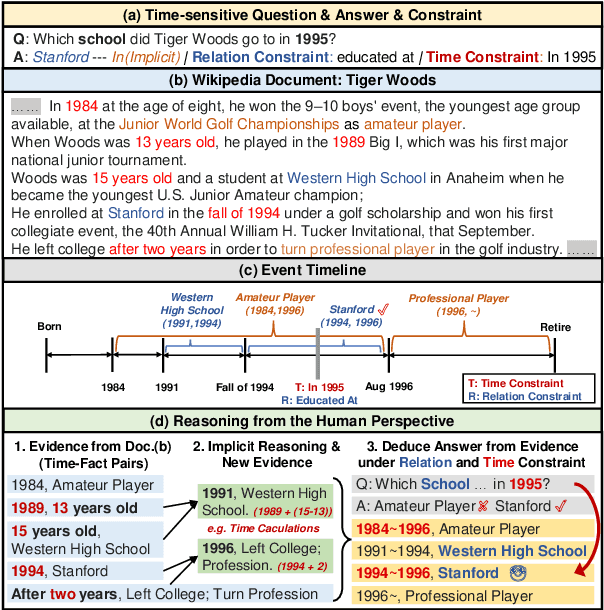
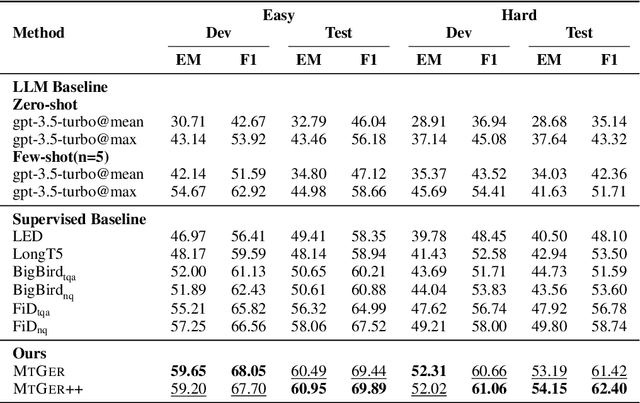
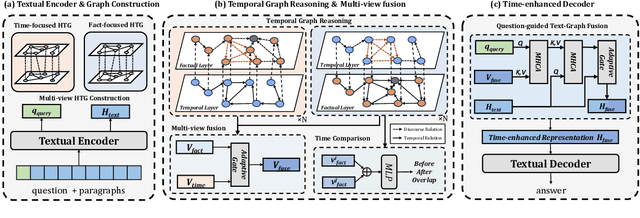

The facts and time in the document are intricately intertwined, making temporal reasoning over documents challenging. Previous work models time implicitly, making it difficult to handle such complex relationships. To address this issue, we propose MTGER, a novel Multi-view Temporal Graph Enhanced Temporal Reasoning framework for temporal reasoning over time-involved documents. Concretely, MTGER explicitly models the temporal relationships among facts by multi-view temporal graphs. On the one hand, the heterogeneous temporal graphs explicitly model the temporal and discourse relationships among facts; on the other hand, the multi-view mechanism captures both time-focused and fact-focused information, allowing the two views to complement each other through adaptive fusion. To further improve the implicit reasoning capability of the model, we design a self-supervised time-comparing objective. Extensive experimental results demonstrate the effectiveness of our method on the TimeQA and SituatedQA datasets. Furthermore, MTGER gives more consistent answers under question perturbations.