 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVLM: An Efficient Vision-Language Model for Visual Understanding
Paper and Code
Jul 19, 2024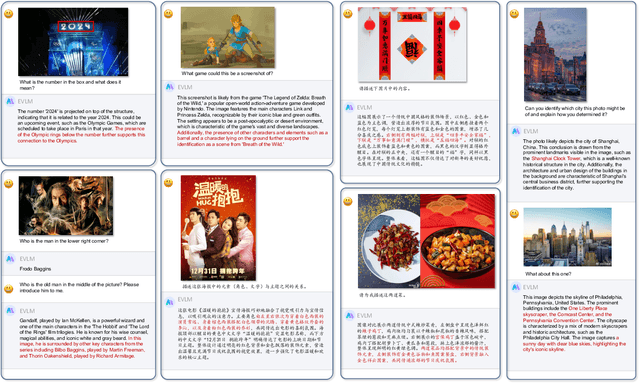
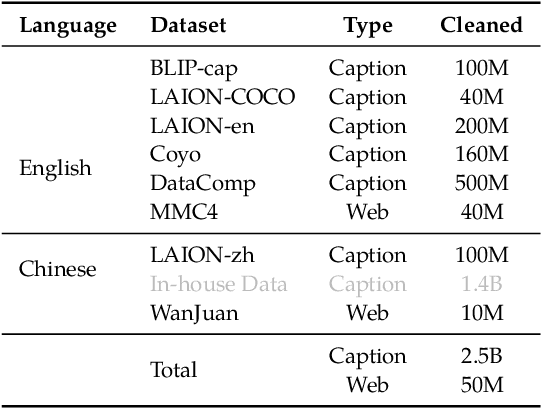
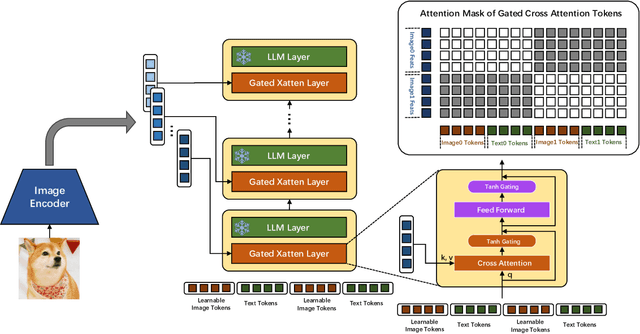

In the field of multi-modal language models, the majority of methods are built on an architecture similar to LLaVA. These models use a single-layer ViT feature as a visual prompt, directly feeding it into the language models alongside textual tokens. However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features makes it challenging for large language models to perceive visual signals fully. This paper proposes an efficient multi-modal language model to minimize computational costs while enabling the model to perceive visual signals as comprehensively as possible. Our method primarily includes: (1) employing cross-attention to image-text interaction similar to Flamingo. (2) utilize hierarchical ViT features. (3) introduce the Mixture of Experts (MoE) mechanism to enhance model effectiveness. Our model achieves competitive scores on public multi-modal benchmarks and performs well in tasks such as image captioning and video captioning.