 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiDiverse: A Multimodal Entity Linking Dataset with Diversified Contextual Topics and Entity Types
Apr 13, 2022
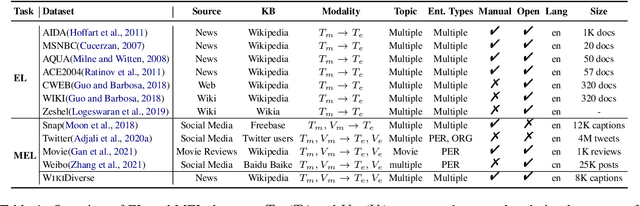
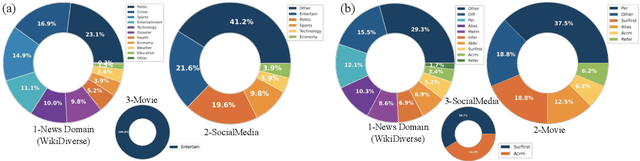

Multimodal Entity Linking (MEL) which aims at linking mentions with multimodal contexts to the referent entities from a knowledge base (e.g., Wikipedia), is an essential task for many multimodal applications. Although much attention has been paid to MEL, the shortcomings of existing MEL datasets including limited contextual topics and entity types, simplified mention ambiguity, and restricted availability, have caused great obstacles to the research and application of MEL. In this paper, we present WikiDiverse, a high-quality human-annotated MEL dataset with diversified contextual topics and entity types from Wikinews, which uses Wikipedia as the corresponding knowledge base. A well-tailored annotation procedure is adopted to ensure the quality of the dataset. Based on WikiDiverse, a sequence of well-designed MEL models with intra-modality and inter-modality attentions are implemented, which utilize the visual information of images more adequately than existing MEL models do. Extensive experimental analyses are conducted to investigate the contributions of different modalities in terms of MEL, facilitating the future research on this task. The dataset and baseline models are available at https://github.com/wangxw5/wikiDiverse.
ITA: Image-Text Alignments for Multi-Modal Named Entity Recognition
Dec 13, 2021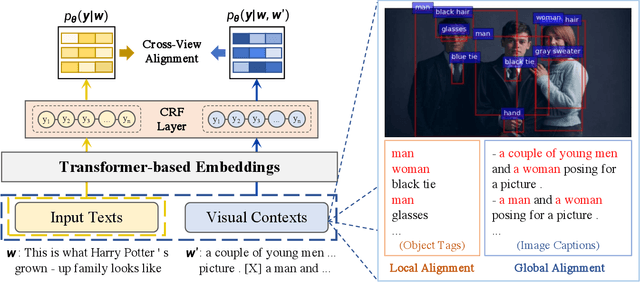
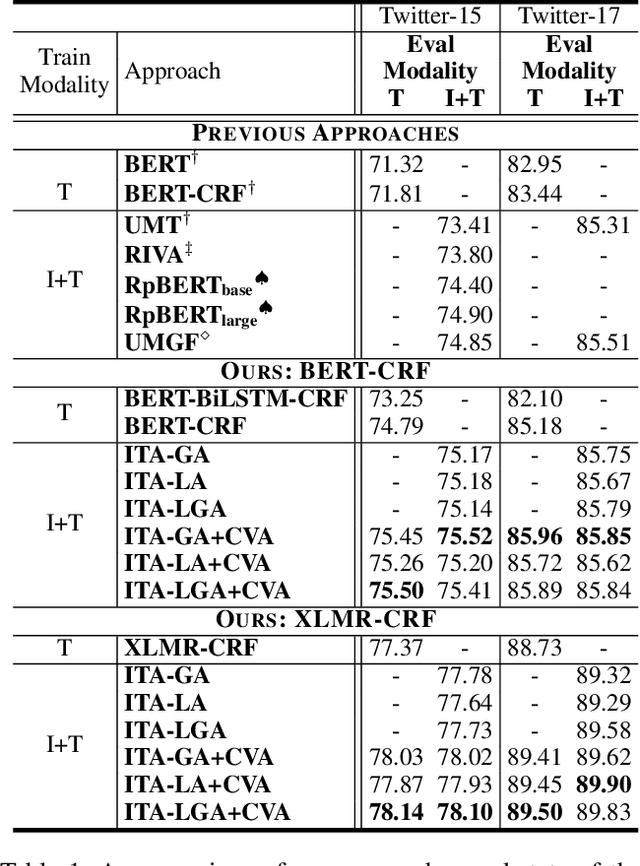
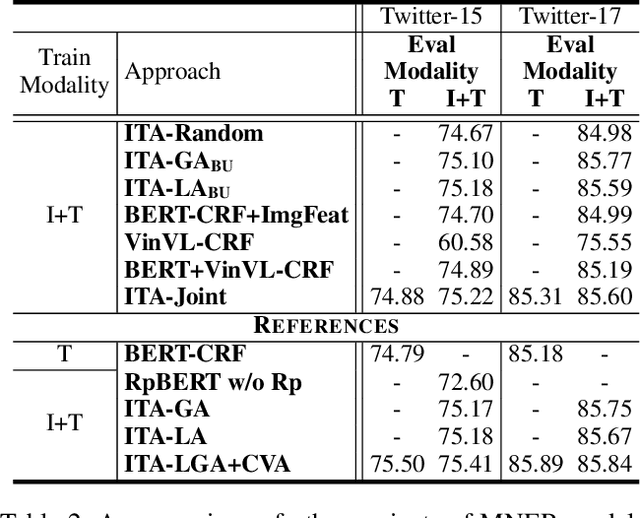
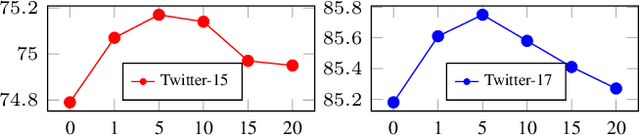
Recently, Multi-modal Named Entity Recognition (MNER) has attracted a lot of attention. Most of the work utilizes image information through region-level visual representations obtained from a pretrained object detector and relies on an attention mechanism to model the interactions between image and text representations. However, it is difficult to model such interactions as image and text representations are trained separately on the data of their respective modality and are not aligned in the same space. As text representations take the most important role in MNER, in this paper, we propose {\bf I}mage-{\bf t}ext {\bf A}lignments (ITA) to align image features into the textual space, so that the attention mechanism in transformer-based pretrained textual embeddings can be better utilized. ITA first locally and globally aligns regional object tags and image-level captions as visual contexts, concatenates them with the input texts as a new cross-modal input, and then feeds it into a pretrained textual embedding model. This makes it easier for the attention module of a pretrained textual embedding model to model the interaction between the two modalities since they are both represented in the textual space. ITA further aligns the output distributions predicted from the cross-modal input and textual input views so that the MNER model can be more practical and robust to noises from images. In our experiments, we show that ITA models can achieve state-of-the-art accuracy on multi-modal Named Entity Recognition datasets, even without image information.
Grid-VLP: Revisiting Grid Features for Vision-Language Pre-training
Aug 21, 2021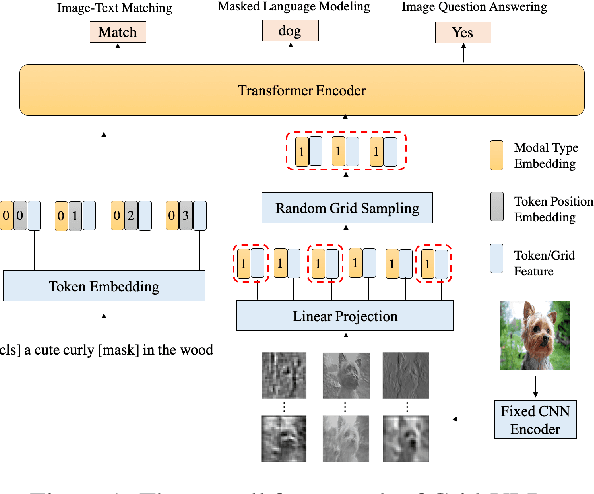
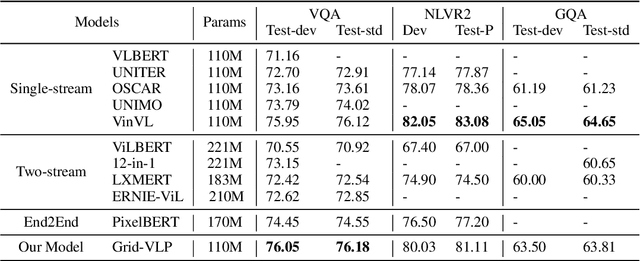
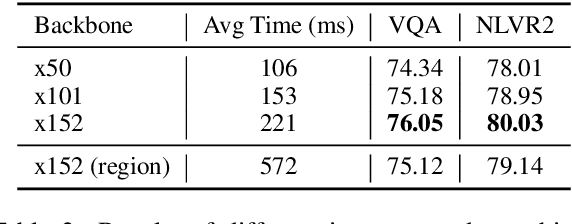
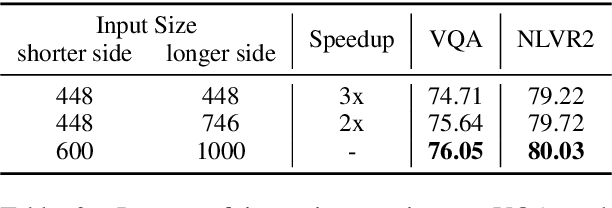
Existing approaches to vision-language pre-training (VLP) heavily rely on an object detector based on bounding boxes (regions), where salient objects are first detected from images and then a Transformer-based model is used for cross-modal fusion. Despite their superior performance, these approaches are bounded by the capability of the object detector in terms of both effectiveness and efficiency. Besides, the presence of object detection imposes unnecessary constraints on model designs and makes it difficult to support end-to-end training. In this paper, we revisit grid-based convolutional features for vision-language pre-training, skipping the expensive region-related steps. We propose a simple yet effective grid-based VLP method that works surprisingly well with the grid features. By pre-training only with in-domain datasets, the proposed Grid-VLP method can outperform most competitive region-based VLP methods on three examined vision-language understanding tasks. We hope that our findings help to further advance the state of the art of vision-language pre-training, and provide a new direction towards effective and efficient VLP.
Attention Optimization for Abstractive Document Summarization
Oct 25, 2019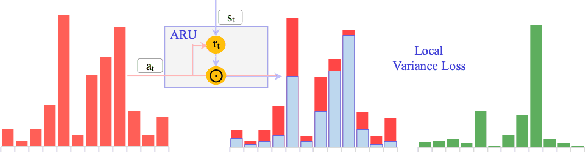
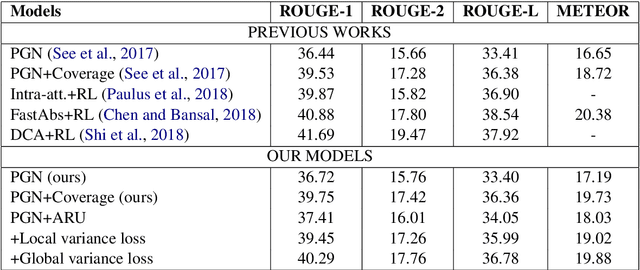
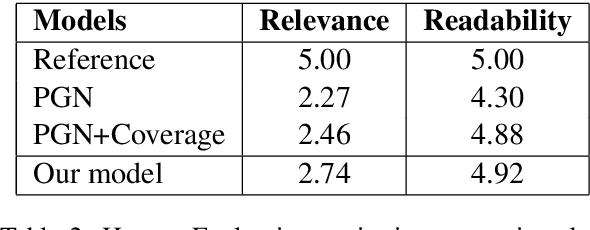
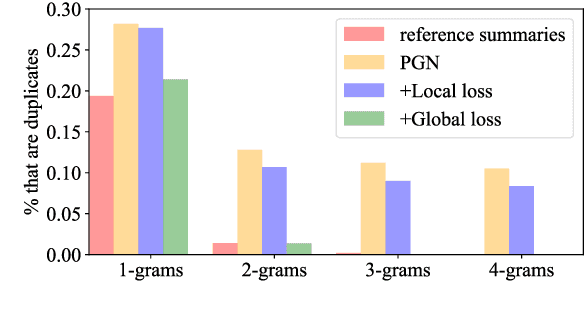
Attention plays a key role in the improvement of sequence-to-sequence-based document summarization models. To obtain a powerful attention helping with reproducing the most salient information and avoiding repetitions, we augment the vanilla attention model from both local and global aspects. We propose an attention refinement unit paired with local variance loss to impose supervision on the attention model at each decoding step, and a global variance loss to optimize the attention distributions of all decoding steps from the global perspective. The performances on the CNN/Daily Mail dataset verify the effectiveness of our methods.