 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXetrieval: Mechanistically Explaining Dense Retrieval
May 28, 2026Explaining why dense retrievers assign high relevance scores remains challenging because retrieval decisions are made through opaque high-dimensional embeddings. Existing explanations often focus on surface signals, such as lexical matches, token alignments, or post-hoc textual rationales, and thus provide limited insight into the latent factors that shape dense retrieval behavior at the embedding level. We propose \textit{Xetrieval}, an embedding-level mechanistic framework for explaining dense retrieval. \textit{Xetrieval} first introduces a lightweight reasoning internalizer that approximates Chain-of-Thought reasoning directly in the embedding space with a single forward pass, enriching sentence embeddings with reasoning-oriented information while avoiding expensive autoregressive generation. It then decomposes these reasoning-enhanced embeddings into sparse, human-interpretable features, each associated with a coherent natural language description. By aggregating sparse feature overlaps across multiple document-side views, \textit{Xetrieval} provides feature-level explanations of individual retrieval decisions. Experiments on diverse retrievers and benchmarks show that \textit{Xetrieval} uncovers coherent interpretable features, yields stronger pair-level intervention effects, and supports task-level feature steering. The project page and source code are available at https://hihiczx.github.io/Xetrieval .
\$OneMillion-Bench: How Far are Language Agents from Human Experts?
Mar 09, 2026As language models (LMs) evolve from chat assistants to long-horizon agents capable of multi-step reasoning and tool use, existing benchmarks remain largely confined to structured or exam-style tasks that fall short of real-world professional demands. To this end, we introduce \$OneMillion-Bench \$OneMillion-Bench, a benchmark of 400 expert-curated tasks spanning Law, Finance, Industry, Healthcare, and Natural Science, built to evaluate agents across economically consequential scenarios. Unlike prior work, the benchmark requires retrieving authoritative sources, resolving conflicting evidence, applying domain-specific rules, and making constraint decisions, where correctness depends as much on the reasoning process as the final answer. We adopt a rubric-based evaluation protocol scoring factual accuracy, logical coherence, practical feasibility, and professional compliance, focused on expert-level problems to ensure meaningful differentiation across agents. Together, \$OneMillion-Bench provides a unified testbed for assessing agentic reliability, professional depth, and practical readiness in domain-intensive scenarios.
The AI Hippocampus: How Far are We From Human Memory?
Jan 14, 2026Memory plays a foundational role in augmenting the reasoning, adaptability, and contextual fidelity of modern Large Language Models and Multi-Modal LLMs. As these models transition from static predictors to interactive systems capable of continual learning and personalized inference, the incorporation of memory mechanisms has emerged as a central theme in their architectural and functional evolution. This survey presents a comprehensive and structured synthesis of memory in LLMs and MLLMs, organizing the literature into a cohesive taxonomy comprising implicit, explicit, and agentic memory paradigms. Specifically, the survey delineates three primary memory frameworks. Implicit memory refers to the knowledge embedded within the internal parameters of pre-trained transformers, encompassing their capacity for memorization, associative retrieval, and contextual reasoning. Recent work has explored methods to interpret, manipulate, and reconfigure this latent memory. Explicit memory involves external storage and retrieval components designed to augment model outputs with dynamic, queryable knowledge representations, such as textual corpora, dense vectors, and graph-based structures, thereby enabling scalable and updatable interaction with information sources. Agentic memory introduces persistent, temporally extended memory structures within autonomous agents, facilitating long-term planning, self-consistency, and collaborative behavior in multi-agent systems, with relevance to embodied and interactive AI. Extending beyond text, the survey examines the integration of memory within multi-modal settings, where coherence across vision, language, audio, and action modalities is essential. Key architectural advances, benchmark tasks, and open challenges are discussed, including issues related to memory capacity, alignment, factual consistency, and cross-system interoperability.
BEDA: Belief Estimation as Probabilistic Constraints for Performing Strategic Dialogue Acts
Dec 31, 2025Strategic dialogue requires agents to execute distinct dialogue acts, for which belief estimation is essential. While prior work often estimates beliefs accurately, it lacks a principled mechanism to use those beliefs during generation. We bridge this gap by first formalizing two core acts Adversarial and Alignment, and by operationalizing them via probabilistic constraints on what an agent may generate. We instantiate this idea in BEDA, a framework that consists of the world set, the belief estimator for belief estimation, and the conditional generator that selects acts and realizes utterances consistent with the inferred beliefs. Across three settings, Conditional Keeper Burglar (CKBG, adversarial), Mutual Friends (MF, cooperative), and CaSiNo (negotiation), BEDA consistently outperforms strong baselines: on CKBG it improves success rate by at least 5.0 points across backbones and by 20.6 points with GPT-4.1-nano; on Mutual Friends it achieves an average improvement of 9.3 points; and on CaSiNo it achieves the optimal deal relative to all baselines. These results indicate that casting belief estimation as constraints provides a simple, general mechanism for reliable strategic dialogue.
Native Parallel Reasoner: Reasoning in Parallelism via Self-Distilled Reinforcement Learning
Dec 19, 2025We introduce Native Parallel Reasoner (NPR), a teacher-free framework that enables Large Language Models (LLMs) to self-evolve genuine parallel reasoning capabilities. NPR transforms the model from sequential emulation to native parallel cognition through three key innovations: 1) a self-distilled progressive training paradigm that transitions from ``cold-start'' format discovery to strict topological constraints without external supervision; 2) a novel Parallel-Aware Policy Optimization (PAPO) algorithm that optimizes branching policies directly within the execution graph, allowing the model to learn adaptive decomposition via trial and error; and 3) a robust NPR Engine that refactors memory management and flow control of SGLang to enable stable, large-scale parallel RL training. Across eight reasoning benchmarks, NPR trained on Qwen3-4B achieves performance gains of up to 24.5% and inference speedups up to 4.6x. Unlike prior baselines that often fall back to autoregressive decoding, NPR demonstrates 100% genuine parallel execution, establishing a new standard for self-evolving, efficient, and scalable agentic reasoning.
Understanding and Leveraging the Expert Specialization of Context Faithfulness in Mixture-of-Experts LLMs
Aug 27, 2025
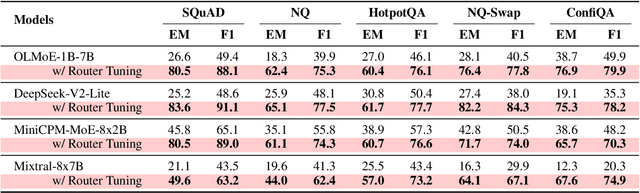
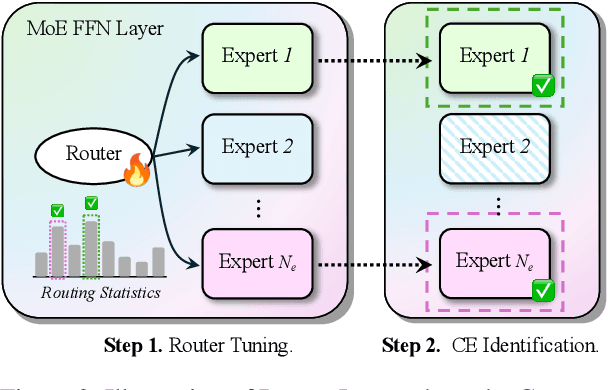
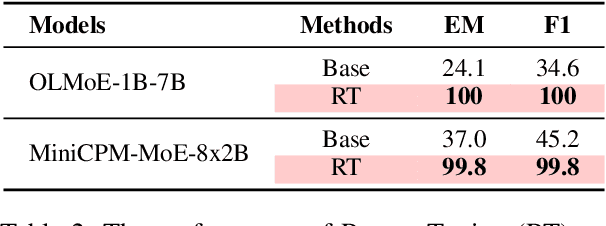
Context faithfulness is essential for reliable reasoning in context-dependent scenarios. However, large language models often struggle to ground their outputs in the provided context, resulting in irrelevant responses. Inspired by the emergent expert specialization observed in mixture-of-experts architectures, this work investigates whether certain experts exhibit specialization in context utilization, offering a potential pathway toward targeted optimization for improved context faithfulness. To explore this, we propose Router Lens, a method that accurately identifies context-faithful experts. Our analysis reveals that these experts progressively amplify attention to relevant contextual information, thereby enhancing context grounding. Building on this insight, we introduce Context-faithful Expert Fine-Tuning (CEFT), a lightweight optimization approach that selectively fine-tunes context-faithful experts. Experiments across a wide range of benchmarks and models demonstrate that CEFT matches or surpasses the performance of full fine-tuning while being significantly more efficient.
TongSearch-QR: Reinforced Query Reasoning for Retrieval
Jun 16, 2025



Traditional information retrieval (IR) methods excel at textual and semantic matching but struggle in reasoning-intensive retrieval tasks that require multi-hop inference or complex semantic understanding between queries and documents. One promising solution is to explicitly rewrite or augment queries using large language models (LLMs) to elicit reasoning-relevant content prior to retrieval. However, the widespread use of large-scale language models like GPT-4 or LLaMA3-70B remains impractical due to their high inference cost and limited deployability in real-world systems. In this work, we introduce TongSearch QR (Previously Known as "TongSearch Reasoner"), a family of small-scale language models for query reasoning and rewriting in reasoning-intensive retrieval. With a novel semi-rule-based reward function, we employ reinforcement learning approaches enabling smaller language models, e,g, Qwen2.5-7B-Instruct and Qwen2.5-1.5B-Instruct, to achieve query reasoning performance rivaling large-scale language models without their prohibitive inference costs. Experiment results on BRIGHT benchmark show that with BM25 as retrievers, both TongSearch QR-7B and TongSearch QR-1.5B models significantly outperform existing baselines, including prompt-based query reasoners and some latest dense retrievers trained for reasoning-intensive retrieval tasks, offering superior adaptability for real-world deployment.
ReflectEvo: Improving Meta Introspection of Small LLMs by Learning Self-Reflection
May 22, 2025We present a novel pipeline, ReflectEvo, to demonstrate that small language models (SLMs) can enhance meta introspection through reflection learning. This process iteratively generates self-reflection for self-training, fostering a continuous and self-evolving process. Leveraging this pipeline, we construct ReflectEvo-460k, a large-scale, comprehensive, self-generated reflection dataset with broadened instructions and diverse multi-domain tasks. Building upon this dataset, we demonstrate the effectiveness of reflection learning to improve SLMs' reasoning abilities using SFT and DPO with remarkable performance, substantially boosting Llama-3 from 52.4% to 71.2% and Mistral from 44.4% to 71.1%. It validates that ReflectEvo can rival or even surpass the reasoning capability of the three prominent open-sourced models on BIG-bench without distillation from superior models or fine-grained human annotation. We further conduct a deeper analysis of the high quality of self-generated reflections and their impact on error localization and correction. Our work highlights the potential of continuously enhancing the reasoning performance of SLMs through iterative reflection learning in the long run.
Seek in the Dark: Reasoning via Test-Time Instance-Level Policy Gradient in Latent Space
May 19, 2025Reasoning ability, a core component of human intelligence, continues to pose a significant challenge for Large Language Models (LLMs) in the pursuit of AGI. Although model performance has improved under the training scaling law, significant challenges remain, particularly with respect to training algorithms, such as catastrophic forgetting, and the limited availability of novel training data. As an alternative, test-time scaling enhances reasoning performance by increasing test-time computation without parameter updating. Unlike prior methods in this paradigm focused on token space, we propose leveraging latent space for more effective reasoning and better adherence to the test-time scaling law. We introduce LatentSeek, a novel framework that enhances LLM reasoning through Test-Time Instance-level Adaptation (TTIA) within the model's latent space. Specifically, LatentSeek leverages policy gradient to iteratively update latent representations, guided by self-generated reward signals. LatentSeek is evaluated on a range of reasoning benchmarks, including GSM8K, MATH-500, and AIME2024, across multiple LLM architectures. Results show that LatentSeek consistently outperforms strong baselines, such as Chain-of-Thought prompting and fine-tuning-based methods. Furthermore, our analysis demonstrates that LatentSeek is highly efficient, typically converging within a few iterations for problems of average complexity, while also benefiting from additional iterations, thereby highlighting the potential of test-time scaling in the latent space. These findings position LatentSeek as a lightweight, scalable, and effective solution for enhancing the reasoning capabilities of LLMs.
From Hours to Minutes: Lossless Acceleration of Ultra Long Sequence Generation up to 100K Tokens
Feb 26, 2025Generating ultra-long sequences with large language models (LLMs) has become increasingly crucial but remains a highly time-intensive task, particularly for sequences up to 100K tokens. While traditional speculative decoding methods exist, simply extending their generation limits fails to accelerate the process and can be detrimental. Through an in-depth analysis, we identify three major challenges hindering efficient generation: frequent model reloading, dynamic key-value (KV) management and repetitive generation. To address these issues, we introduce TOKENSWIFT, a novel framework designed to substantially accelerate the generation process of ultra-long sequences while maintaining the target model's inherent quality. Experimental results demonstrate that TOKENSWIFT achieves over 3 times speedup across models of varying scales (1.5B, 7B, 8B, 14B) and architectures (MHA, GQA). This acceleration translates to hours of time savings for ultra-long sequence generation, establishing TOKENSWIFT as a scalable and effective solution at unprecedented lengths. Code can be found at https://github.com/bigai-nlco/TokenSwift.