 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeqGPT: An Out-of-the-box Large Language Model for Open Domain Sequence Understanding
Aug 21, 2023
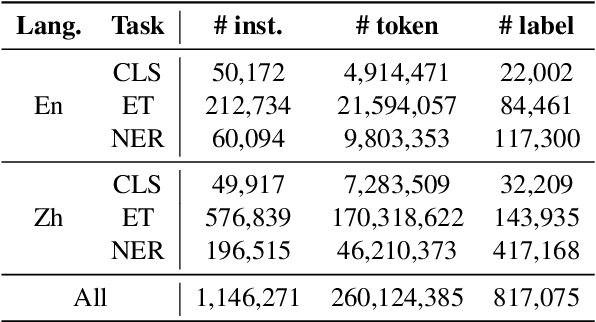
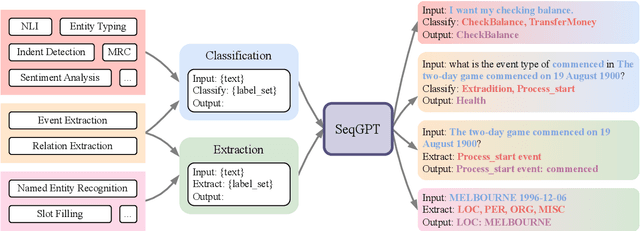

Large language models (LLMs) have shown impressive ability for open-domain NLP tasks. However, LLMs are sometimes too footloose for natural language understanding (NLU) tasks which always have restricted output and input format. Their performances on NLU tasks are highly related to prompts or demonstrations and are shown to be poor at performing several representative NLU tasks, such as event extraction and entity typing. To this end, we present SeqGPT, a bilingual (i.e., English and Chinese) open-source autoregressive model specially enhanced for open-domain natural language understanding. We express all NLU tasks with two atomic tasks, which define fixed instructions to restrict the input and output format but still ``open'' for arbitrarily varied label sets. The model is first instruction-tuned with extremely fine-grained labeled data synthesized by ChatGPT and then further fine-tuned by 233 different atomic tasks from 152 datasets across various domains. The experimental results show that SeqGPT has decent classification and extraction ability, and is capable of performing language understanding tasks on unseen domains. We also conduct empirical studies on the scaling of data and model size as well as on the transfer across tasks. Our model is accessible at https://github.com/Alibaba-NLP/SeqGPT.
Improving Text Matching in E-Commerce Search with A Rationalizable, Intervenable and Fast Entity-Based Relevance Model
Jul 01, 2023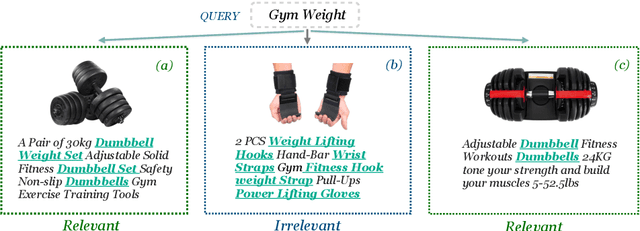

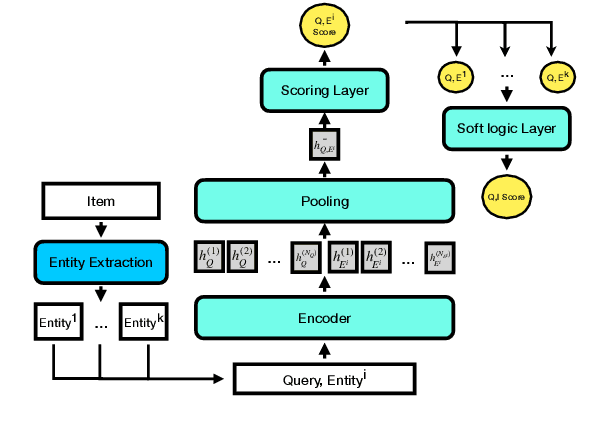
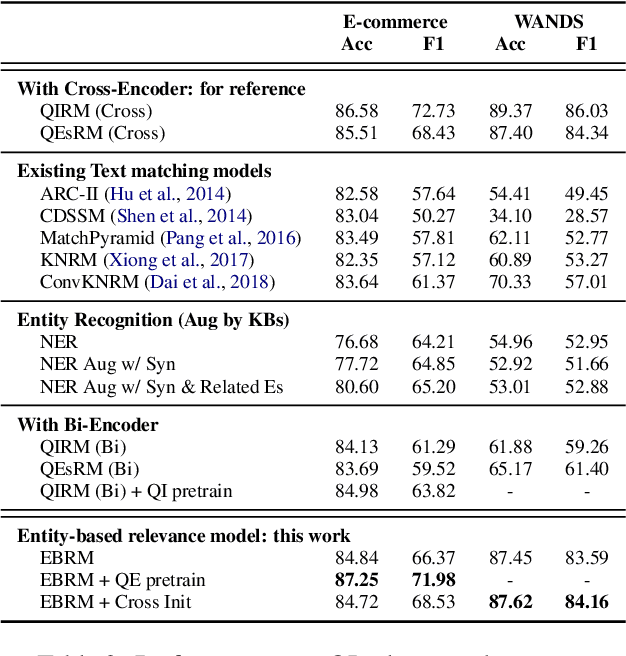
Discovering the intended items of user queries from a massive repository of items is one of the main goals of an e-commerce search system. Relevance prediction is essential to the search system since it helps improve performance. When online serving a relevance model, the model is required to perform fast and accurate inference. Currently, the widely used models such as Bi-encoder and Cross-encoder have their limitations in accuracy or inference speed respectively. In this work, we propose a novel model called the Entity-Based Relevance Model (EBRM). We identify the entities contained in an item and decompose the QI (query-item) relevance problem into multiple QE (query-entity) relevance problems; we then aggregate their results to form the QI prediction using a soft logic formulation. The decomposition allows us to use a Cross-encoder QE relevance module for high accuracy as well as cache QE predictions for fast online inference. Utilizing soft logic makes the prediction procedure interpretable and intervenable. We also show that pretraining the QE module with auto-generated QE data from user logs can further improve the overall performance. The proposed method is evaluated on labeled data from e-commerce websites. Empirical results show that it achieves promising improvements with computation efficiency.
DAMO-NLP at SemEval-2023 Task 2: A Unified Retrieval-augmented System for Multilingual Named Entity Recognition
May 09, 2023
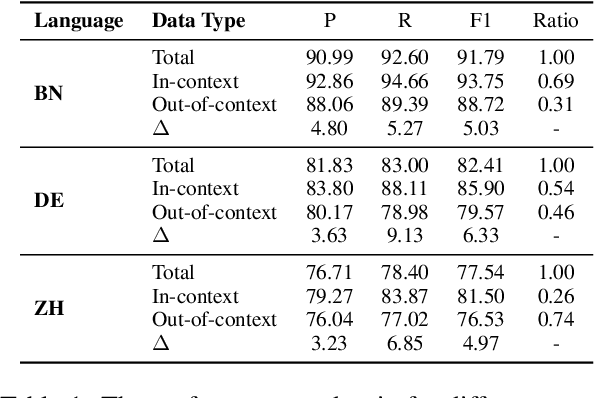
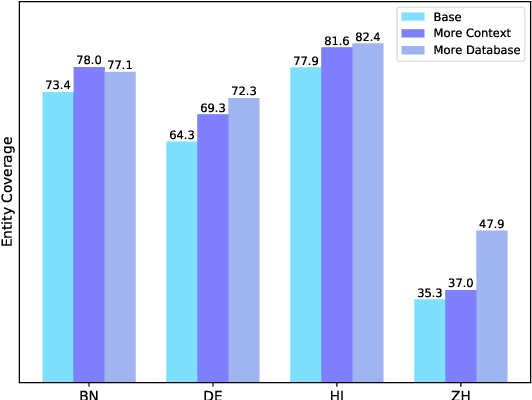
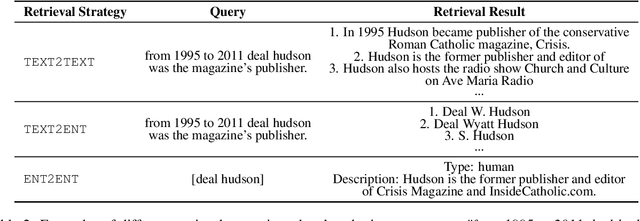
The MultiCoNER \RNum{2} shared task aims to tackle multilingual named entity recognition (NER) in fine-grained and noisy scenarios, and it inherits the semantic ambiguity and low-context setting of the MultiCoNER \RNum{1} task. To cope with these problems, the previous top systems in the MultiCoNER \RNum{1} either incorporate the knowledge bases or gazetteers. However, they still suffer from insufficient knowledge, limited context length, single retrieval strategy. In this paper, our team \textbf{DAMO-NLP} proposes a unified retrieval-augmented system (U-RaNER) for fine-grained multilingual NER. We perform error analysis on the previous top systems and reveal that their performance bottleneck lies in insufficient knowledge. Also, we discover that the limited context length causes the retrieval knowledge to be invisible to the model. To enhance the retrieval context, we incorporate the entity-centric Wikidata knowledge base, while utilizing the infusion approach to broaden the contextual scope of the model. Also, we explore various search strategies and refine the quality of retrieval knowledge. Our system\footnote{We will release the dataset, code, and scripts of our system at {\small \url{https://github.com/modelscope/AdaSeq/tree/master/examples/U-RaNER}}.} wins 9 out of 13 tracks in the MultiCoNER \RNum{2} shared task. Additionally, we compared our system with ChatGPT, one of the large language models which have unlocked strong capabilities on many tasks. The results show that there is still much room for improvement for ChatGPT on the extraction task.
Named Entity and Relation Extraction with Multi-Modal Retrieval
Dec 03, 2022Multi-modal named entity recognition (NER) and relation extraction (RE) aim to leverage relevant image information to improve the performance of NER and RE. Most existing efforts largely focused on directly extracting potentially useful information from images (such as pixel-level features, identified objects, and associated captions). However, such extraction processes may not be knowledge aware, resulting in information that may not be highly relevant. In this paper, we propose a novel Multi-modal Retrieval based framework (MoRe). MoRe contains a text retrieval module and an image-based retrieval module, which retrieve related knowledge of the input text and image in the knowledge corpus respectively. Next, the retrieval results are sent to the textual and visual models respectively for predictions. Finally, a Mixture of Experts (MoE) module combines the predictions from the two models to make the final decision. Our experiments show that both our textual model and visual model can achieve state-of-the-art performance on four multi-modal NER datasets and one multi-modal RE dataset. With MoE, the model performance can be further improved and our analysis demonstrates the benefits of integrating both textual and visual cues for such tasks.
DAMO-NLP at SemEval-2022 Task 11: A Knowledge-based System for Multilingual Named Entity Recognition
Mar 01, 2022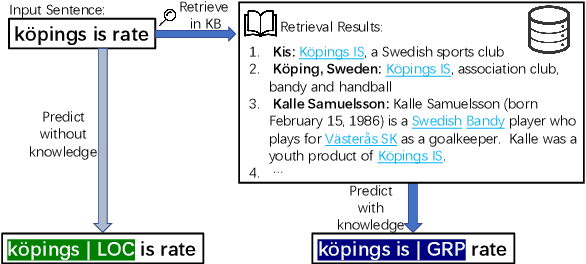


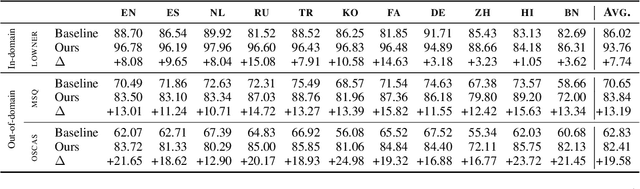
The MultiCoNER shared task aims at detecting semantically ambiguous and complex named entities in short and low-context settings for multiple languages. The lack of contexts makes the recognition of ambiguous named entities challenging. To alleviate this issue, our team DAMO-NLP proposes a knowledge-based system, where we build a multilingual knowledge base based on Wikipedia to provide related context information to the named entity recognition (NER) model. Given an input sentence, our system effectively retrieves related contexts from the knowledge base. The original input sentences are then augmented with such context information, allowing significantly better contextualized token representations to be captured. Our system wins 10 out of 13 tracks in the MultiCoNER shared task.
CRF Autoencoder for Unsupervised Dependency Parsing
Aug 03, 2017


Unsupervised dependency parsing, which tries to discover linguistic dependency structures from unannotated data, is a very challenging task. Almost all previous work on this task focuses on learning generative models. In this paper, we develop an unsupervised dependency parsing model based on the CRF autoencoder. The encoder part of our model is discriminative and globally normalized which allows us to use rich features as well as universal linguistic priors. We propose an exact algorithm for parsing as well as a tractable learning algorithm. We evaluated the performance of our model on eight multilingual treebanks and found that our model achieved comparable performance with state-of-the-art approaches.