 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoT: Enhancing Large Language Models with Reflection on Search Trees
Apr 11, 2024Large language models (LLMs) have demonstrated impressive capability in reasoning and planning when integrated with tree-search-based prompting methods. However, since these methods ignore the previous search experiences, they often make the same mistakes in the search process. To address this issue, we introduce Reflection on search Trees (RoT), an LLM reflection framework designed to improve the performance of tree-search-based prompting methods. It uses a strong LLM to summarize guidelines from previous tree search experiences to enhance the ability of a weak LLM. The guidelines are instructions about solving this task through tree search which can prevent the weak LLMs from making similar mistakes in the past search process. In addition, we proposed a novel state selection method, which identifies the critical information from historical search processes to help RoT generate more specific and meaningful guidelines. In our extensive experiments, we find that RoT significantly improves the performance of LLMs in reasoning or planning tasks with various tree-search-based prompting methods (e.g., BFS and MCTS). Non-tree-search-based prompting methods such as Chain-of-Thought (CoT) can also benefit from RoT guidelines since RoT can provide task-specific knowledge collected from the search experience.
Using Interpretation Methods for Model Enhancement
Apr 02, 2024In the age of neural natural language processing, there are plenty of works trying to derive interpretations of neural models. Intuitively, when gold rationales exist during training, one can additionally train the model to match its interpretation with the rationales. However, this intuitive idea has not been fully explored. In this paper, we propose a framework of utilizing interpretation methods and gold rationales to enhance models. Our framework is very general in the sense that it can incorporate various interpretation methods. Previously proposed gradient-based methods can be shown as an instance of our framework. We also propose two novel instances utilizing two other types of interpretation methods, erasure/replace-based and extractor-based methods, for model enhancement. We conduct comprehensive experiments on a variety of tasks. Experimental results show that our framework is effective especially in low-resource settings in enhancing models with various interpretation methods, and our two newly-proposed methods outperform gradient-based methods in most settings. Code is available at https://github.com/Chord-Chen-30/UIMER.
* EMNLP 2023
Do PLMs Know and Understand Ontological Knowledge?
Sep 12, 2023



Ontological knowledge, which comprises classes and properties and their relationships, is integral to world knowledge. It is significant to explore whether Pretrained Language Models (PLMs) know and understand such knowledge. However, existing PLM-probing studies focus mainly on factual knowledge, lacking a systematic probing of ontological knowledge. In this paper, we focus on probing whether PLMs store ontological knowledge and have a semantic understanding of the knowledge rather than rote memorization of the surface form. To probe whether PLMs know ontological knowledge, we investigate how well PLMs memorize: (1) types of entities; (2) hierarchical relationships among classes and properties, e.g., Person is a subclass of Animal and Member of Sports Team is a subproperty of Member of ; (3) domain and range constraints of properties, e.g., the subject of Member of Sports Team should be a Person and the object should be a Sports Team. To further probe whether PLMs truly understand ontological knowledge beyond memorization, we comprehensively study whether they can reliably perform logical reasoning with given knowledge according to ontological entailment rules. Our probing results show that PLMs can memorize certain ontological knowledge and utilize implicit knowledge in reasoning. However, both the memorizing and reasoning performances are less than perfect, indicating incomplete knowledge and understanding.
EcomGPT: Instruction-tuning Large Language Models with Chain-of-Task Tasks for E-commerce
Aug 28, 2023
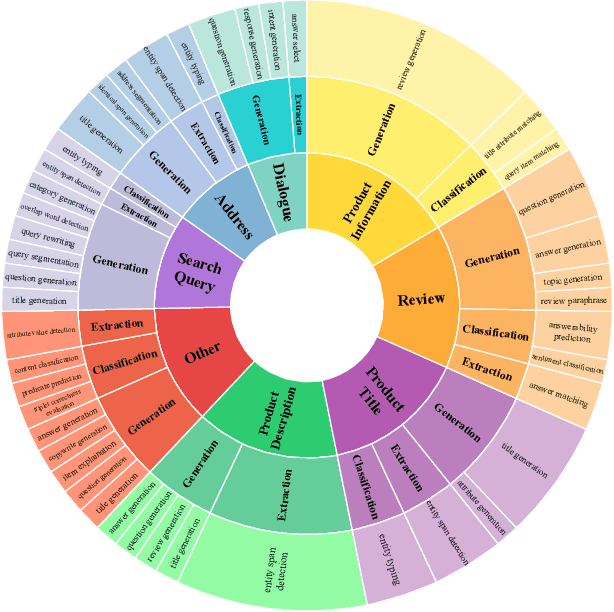
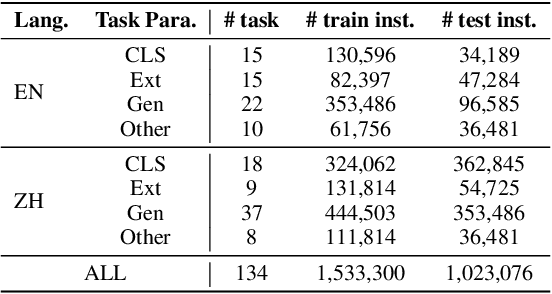
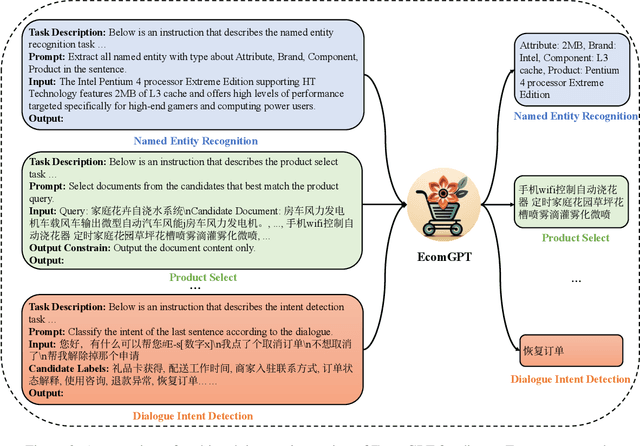
Recently, instruction-following Large Language Models (LLMs) , represented by ChatGPT, have exhibited exceptional performance in general Natural Language Processing (NLP) tasks. However, the unique characteristics of E-commerce data pose significant challenges to general LLMs. An LLM tailored specifically for E-commerce scenarios, possessing robust cross-dataset/task generalization capabilities, is a pressing necessity. To solve this issue, in this work, we proposed the first e-commerce instruction dataset EcomInstruct, with a total of 2.5 million instruction data. EcomInstruct scales up the data size and task diversity by constructing atomic tasks with E-commerce basic data types, such as product information, user reviews. Atomic tasks are defined as intermediate tasks implicitly involved in solving a final task, which we also call Chain-of-Task tasks. We developed EcomGPT with different parameter scales by training the backbone model BLOOMZ with the EcomInstruct. Benefiting from the fundamental semantic understanding capabilities acquired from the Chain-of-Task tasks, EcomGPT exhibits excellent zero-shot generalization capabilities. Extensive experiments and human evaluations demonstrate that EcomGPT outperforms ChatGPT in term of cross-dataset/task generalization on E-commerce tasks.
SeqGPT: An Out-of-the-box Large Language Model for Open Domain Sequence Understanding
Aug 21, 2023
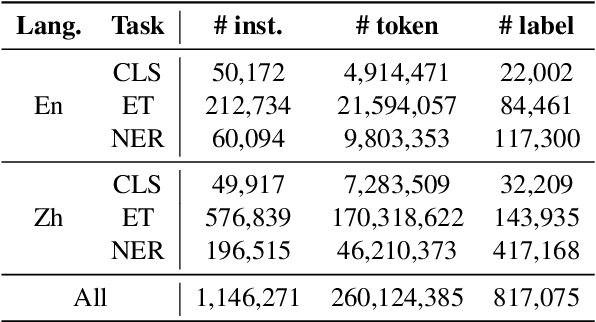
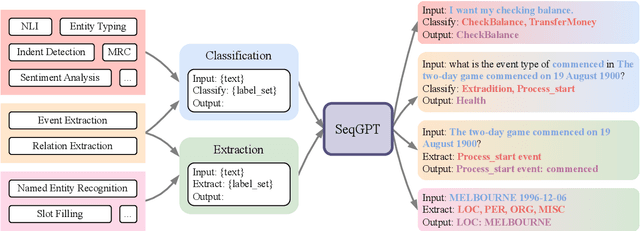

Large language models (LLMs) have shown impressive ability for open-domain NLP tasks. However, LLMs are sometimes too footloose for natural language understanding (NLU) tasks which always have restricted output and input format. Their performances on NLU tasks are highly related to prompts or demonstrations and are shown to be poor at performing several representative NLU tasks, such as event extraction and entity typing. To this end, we present SeqGPT, a bilingual (i.e., English and Chinese) open-source autoregressive model specially enhanced for open-domain natural language understanding. We express all NLU tasks with two atomic tasks, which define fixed instructions to restrict the input and output format but still ``open'' for arbitrarily varied label sets. The model is first instruction-tuned with extremely fine-grained labeled data synthesized by ChatGPT and then further fine-tuned by 233 different atomic tasks from 152 datasets across various domains. The experimental results show that SeqGPT has decent classification and extraction ability, and is capable of performing language understanding tasks on unseen domains. We also conduct empirical studies on the scaling of data and model size as well as on the transfer across tasks. Our model is accessible at https://github.com/Alibaba-NLP/SeqGPT.
COMBO: A Complete Benchmark for Open KG Canonicalization
Feb 08, 2023



Open knowledge graph (KG) consists of (subject, relation, object) triples extracted from millions of raw text. The subject and object noun phrases and the relation in open KG have severe redundancy and ambiguity and need to be canonicalized. Existing datasets for open KG canonicalization only provide gold entity-level canonicalization for noun phrases. In this paper, we present COMBO, a Complete Benchmark for Open KG canonicalization. Compared with existing datasets, we additionally provide gold canonicalization for relation phrases, gold ontology-level canonicalization for noun phrases, as well as source sentences from which triples are extracted. We also propose metrics for evaluating each type of canonicalization. On the COMBO dataset, we empirically compare previously proposed canonicalization methods as well as a few simple baseline methods based on pretrained language models. We find that properly encoding the phrases in a triple using pretrained language models results in better relation canonicalization and ontology-level canonicalization of the noun phrase. We release our dataset, baselines, and evaluation scripts at https://github.com/jeffchy/COMBO/tree/main.
Recall, Expand and Multi-Candidate Cross-Encode: Fast and Accurate Ultra-Fine Entity Typing
Dec 18, 2022



Ultra-fine entity typing (UFET) predicts extremely free-formed types (e.g., president, politician) of a given entity mention (e.g., Joe Biden) in context. State-of-the-art (SOTA) methods use the cross-encoder (CE) based architecture. CE concatenates the mention (and its context) with each type and feeds the pairs into a pretrained language model (PLM) to score their relevance. It brings deeper interaction between mention and types to reach better performance but has to perform N (type set size) forward passes to infer types of a single mention. CE is therefore very slow in inference when the type set is large (e.g., N = 10k for UFET). To this end, we propose to perform entity typing in a recall-expand-filter manner. The recall and expand stages prune the large type set and generate K (K is typically less than 256) most relevant type candidates for each mention. At the filter stage, we use a novel model called MCCE to concurrently encode and score these K candidates in only one forward pass to obtain the final type prediction. We investigate different variants of MCCE and extensive experiments show that MCCE under our paradigm reaches SOTA performance on ultra-fine entity typing and is thousands of times faster than the cross-encoder. We also found MCCE is very effective in fine-grained (130 types) and coarse-grained (9 types) entity typing. Our code is available at \url{https://github.com/modelscope/AdaSeq/tree/master/examples/MCCE}.
Modeling Label Correlations for Ultra-Fine Entity Typing with Neural Pairwise Conditional Random Field
Dec 03, 2022Ultra-fine entity typing (UFET) aims to predict a wide range of type phrases that correctly describe the categories of a given entity mention in a sentence. Most recent works infer each entity type independently, ignoring the correlations between types, e.g., when an entity is inferred as a president, it should also be a politician and a leader. To this end, we use an undirected graphical model called pairwise conditional random field (PCRF) to formulate the UFET problem, in which the type variables are not only unarily influenced by the input but also pairwisely relate to all the other type variables. We use various modern backbones for entity typing to compute unary potentials, and derive pairwise potentials from type phrase representations that both capture prior semantic information and facilitate accelerated inference. We use mean-field variational inference for efficient type inference on very large type sets and unfold it as a neural network module to enable end-to-end training. Experiments on UFET show that the Neural-PCRF consistently outperforms its backbones with little cost and results in a competitive performance against cross-encoder based SOTA while being thousands of times faster. We also find Neural- PCRF effective on a widely used fine-grained entity typing dataset with a smaller type set. We pack Neural-PCRF as a network module that can be plugged onto multi-label type classifiers with ease and release it in https://github.com/modelscope/adaseq/tree/master/examples/NPCRF.
ShanghaiTech at MRP 2019: Sequence-to-Graph Transduction with Second-Order Edge Inference for Cross-Framework Meaning Representation Parsing
Apr 08, 2020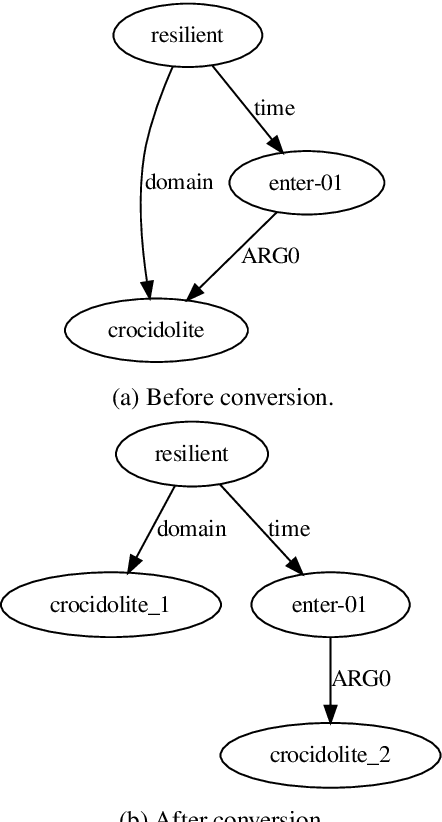
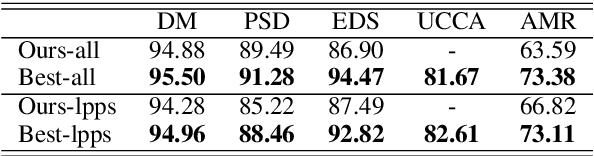
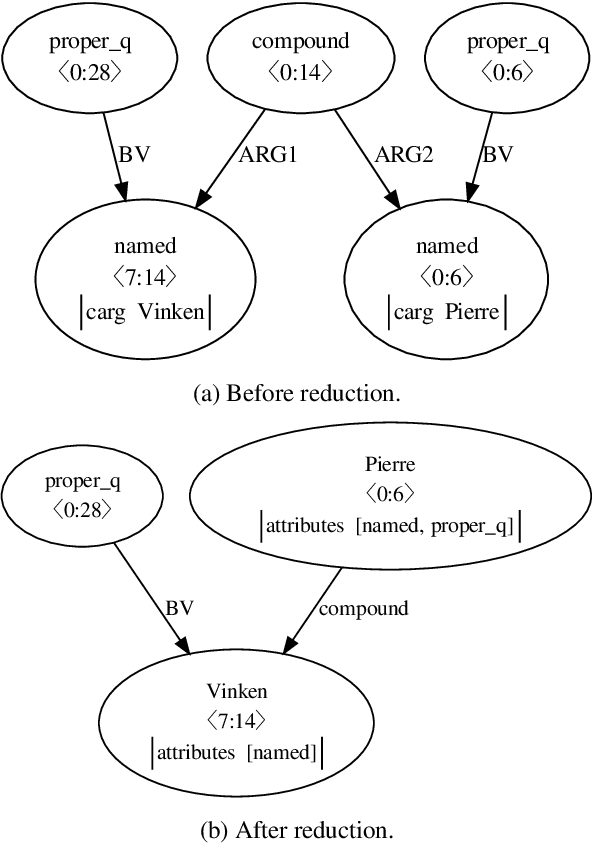
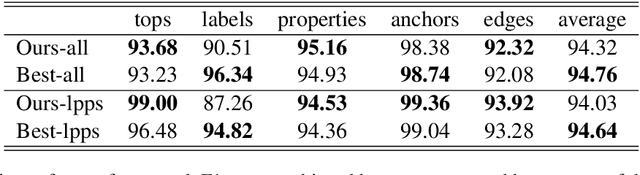
This paper presents the system used in our submission to the \textit{CoNLL 2019 shared task: Cross-Framework Meaning Representation Parsing}. Our system is a graph-based parser which combines an extended pointer-generator network that generates nodes and a second-order mean field variational inference module that predicts edges. Our system achieved \nth{1} and \nth{2} place for the DM and PSD frameworks respectively on the in-framework ranks and achieved \nth{3} place for the DM framework on the cross-framework ranks.
Learning Numeral Embeddings
Jan 11, 2020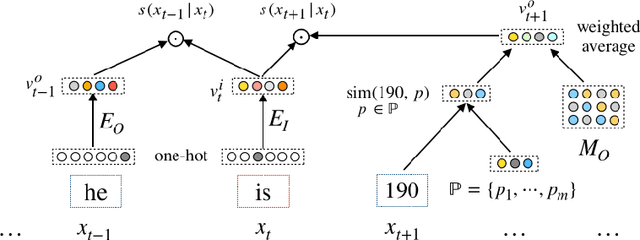

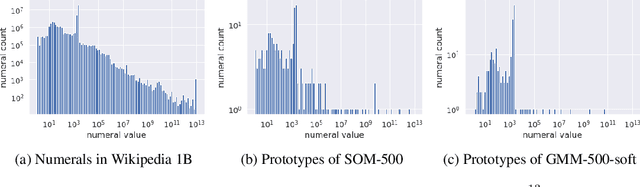
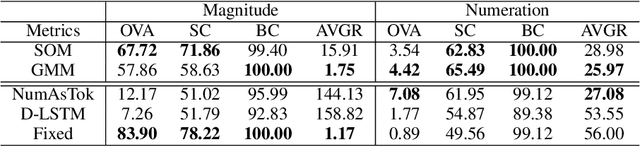
Word embedding is an essential building block for deep learning methods for natural language processing. Although word embedding has been extensively studied over the years, the problem of how to effectively embed numerals, a special subset of words, is still underexplored. Existing word embedding methods do not learn numeral embeddings well because there are an infinite number of numerals and their individual appearances in training corpora are highly scarce. In this paper, we propose two novel numeral embedding methods that can handle the out-of-vocabulary (OOV) problem for numerals. We first induce a finite set of prototype numerals using either a self-organizing map or a Gaussian mixture model. We then represent the embedding of a numeral as a weighted average of the prototype number embeddings. Numeral embeddings represented in this manner can be plugged into existing word embedding learning approaches such as skip-gram for training. We evaluated our methods and showed its effectiveness on four intrinsic and extrinsic tasks: word similarity, embedding numeracy, numeral prediction, and sequence labeling.