 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving EHR Data Transformation via Geometric Operators: A Human-AI Co-Design Technical Report
Mar 24, 2026Electronic health records (EHRs) and other real-world clinical data are essential for clinical research, medical artificial intelligence, and life science, but their sharing is severely limited by privacy, governance, and interoperability constraints. These barriers create persistent data silos that hinder multi-center studies, large-scale model development, and broader biomedical discovery. Existing privacy-preserving approaches, including multi-party computation and related cryptographic techniques, provide strong protection but often introduce substantial computational overhead, reducing the efficiency of large-scale machine learning and foundation-model training. In addition, many such methods make data usable for restricted computation while leaving them effectively invisible to clinicians and researchers, limiting their value in workflows that still require direct inspection, exploratory analysis, and human interpretation. We propose a real-world-data transformation framework for privacy-preserving sharing of structured clinical records. Instead of converting data into opaque representations, our approach constructs transformed numeric views that preserve medical semantics and major statistical properties while, under a clearly specified threat model, provably breaking direct linkage between those views and protected patient-level attributes. Through collaboration between computer scientists and the AI agent \textbf{SciencePal}, acting as a constrained tool inventor under human guidance, we design three transformation operators that are non-reversible within this threat model, together with an additional mixing strategy for high-risk scenarios, supported by theoretical analysis and empirical evaluation under reconstruction, record linkage, membership inference, and attribute inference attacks.
Lite Unified Modeling for Discriminative Reading Comprehension
Mar 26, 2022
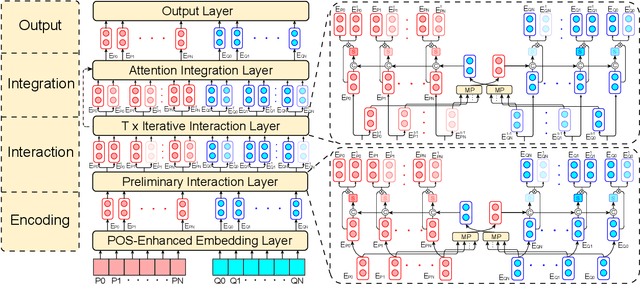
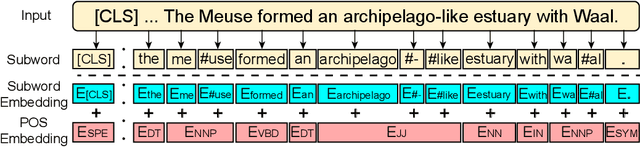
As a broad and major category in machine reading comprehension (MRC), the generalized goal of discriminative MRC is answer prediction from the given materials. However, the focuses of various discriminative MRC tasks may be diverse enough: multi-choice MRC requires model to highlight and integrate all potential critical evidence globally; while extractive MRC focuses on higher local boundary preciseness for answer extraction. Among previous works, there lacks a unified design with pertinence for the overall discriminative MRC tasks. To fill in above gap, we propose a lightweight POS-Enhanced Iterative Co-Attention Network (POI-Net) as the first attempt of unified modeling with pertinence, to handle diverse discriminative MRC tasks synchronously. Nearly without introducing more parameters, our lite unified design brings model significant improvement with both encoder and decoder components. The evaluation results on four discriminative MRC benchmarks consistently indicate the general effectiveness and applicability of our model, and the code is available at https://github.com/Yilin1111/poi-net.
Learning Numeral Embeddings
Jan 11, 2020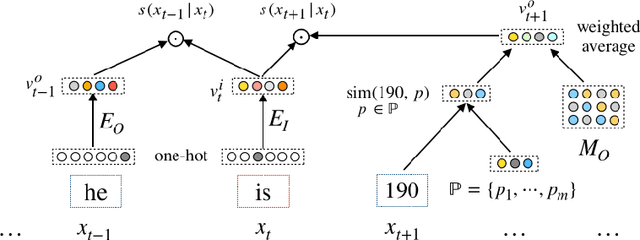

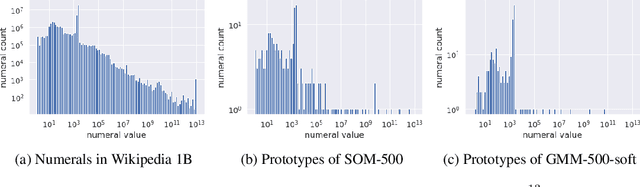
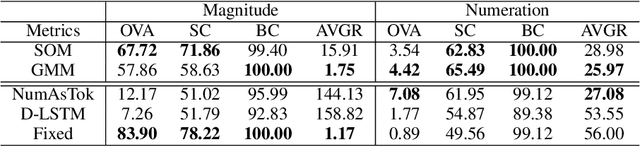
Word embedding is an essential building block for deep learning methods for natural language processing. Although word embedding has been extensively studied over the years, the problem of how to effectively embed numerals, a special subset of words, is still underexplored. Existing word embedding methods do not learn numeral embeddings well because there are an infinite number of numerals and their individual appearances in training corpora are highly scarce. In this paper, we propose two novel numeral embedding methods that can handle the out-of-vocabulary (OOV) problem for numerals. We first induce a finite set of prototype numerals using either a self-organizing map or a Gaussian mixture model. We then represent the embedding of a numeral as a weighted average of the prototype number embeddings. Numeral embeddings represented in this manner can be plugged into existing word embedding learning approaches such as skip-gram for training. We evaluated our methods and showed its effectiveness on four intrinsic and extrinsic tasks: word similarity, embedding numeracy, numeral prediction, and sequence labeling.