 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLite Unified Modeling for Discriminative Reading Comprehension
Mar 26, 2022
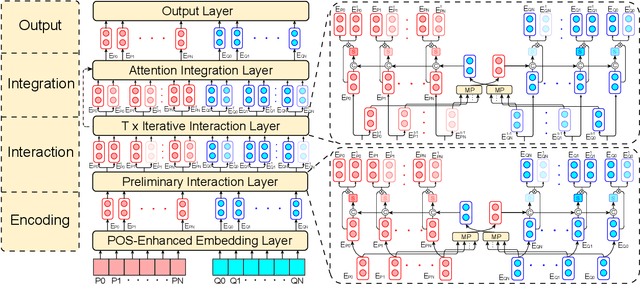
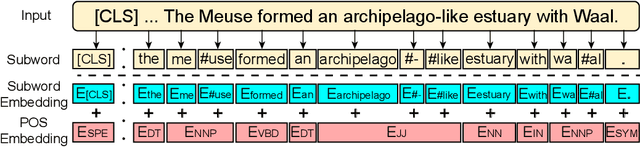
As a broad and major category in machine reading comprehension (MRC), the generalized goal of discriminative MRC is answer prediction from the given materials. However, the focuses of various discriminative MRC tasks may be diverse enough: multi-choice MRC requires model to highlight and integrate all potential critical evidence globally; while extractive MRC focuses on higher local boundary preciseness for answer extraction. Among previous works, there lacks a unified design with pertinence for the overall discriminative MRC tasks. To fill in above gap, we propose a lightweight POS-Enhanced Iterative Co-Attention Network (POI-Net) as the first attempt of unified modeling with pertinence, to handle diverse discriminative MRC tasks synchronously. Nearly without introducing more parameters, our lite unified design brings model significant improvement with both encoder and decoder components. The evaluation results on four discriminative MRC benchmarks consistently indicate the general effectiveness and applicability of our model, and the code is available at https://github.com/Yilin1111/poi-net.
Look Backward and Forward: Self-Knowledge Distillation with Bidirectional Decoder for Neural Machine Translation
Mar 11, 2022

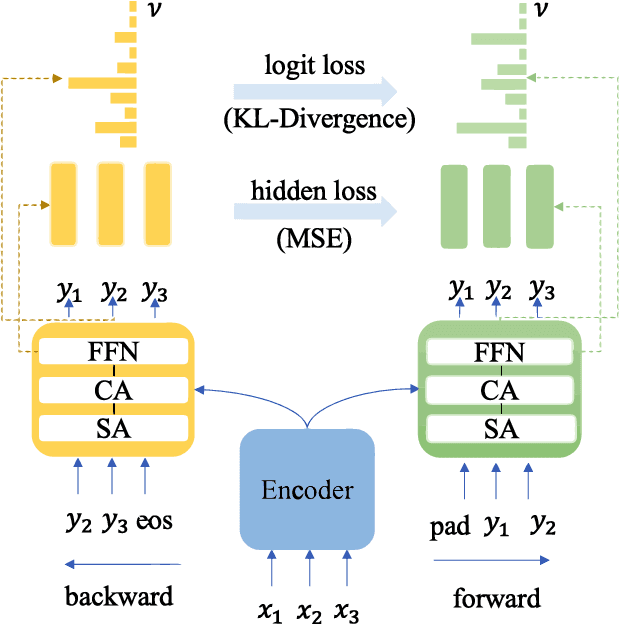
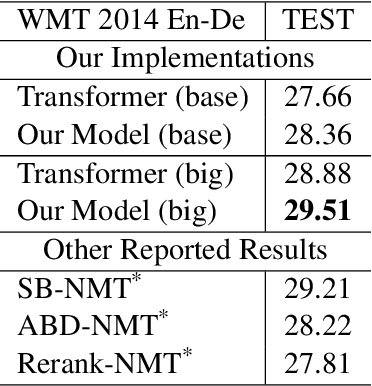
Neural Machine Translation(NMT) models are usually trained via unidirectional decoder which corresponds to optimizing one-step-ahead prediction. However, this kind of unidirectional decoding framework may incline to focus on local structure rather than global coherence. To alleviate this problem, we propose a novel method, Self-Knowledge Distillation with Bidirectional Decoder for Neural Machine Translation(SBD-NMT). We deploy a backward decoder which can act as an effective regularization method to the forward decoder. By leveraging the backward decoder's information about the longer-term future, distilling knowledge learned in the backward decoder can encourage auto-regressive NMT models to plan ahead. Experiments show that our method is significantly better than the strong Transformer baselines on multiple machine translation data sets.
Learning Numeral Embeddings
Jan 11, 2020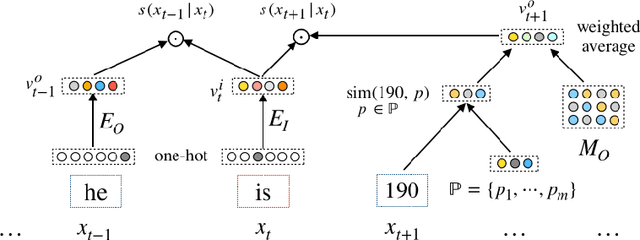

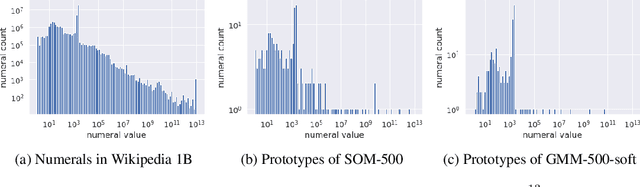
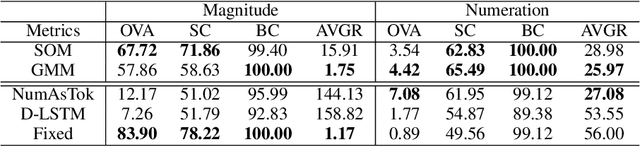
Word embedding is an essential building block for deep learning methods for natural language processing. Although word embedding has been extensively studied over the years, the problem of how to effectively embed numerals, a special subset of words, is still underexplored. Existing word embedding methods do not learn numeral embeddings well because there are an infinite number of numerals and their individual appearances in training corpora are highly scarce. In this paper, we propose two novel numeral embedding methods that can handle the out-of-vocabulary (OOV) problem for numerals. We first induce a finite set of prototype numerals using either a self-organizing map or a Gaussian mixture model. We then represent the embedding of a numeral as a weighted average of the prototype number embeddings. Numeral embeddings represented in this manner can be plugged into existing word embedding learning approaches such as skip-gram for training. We evaluated our methods and showed its effectiveness on four intrinsic and extrinsic tasks: word similarity, embedding numeracy, numeral prediction, and sequence labeling.
Understanding Exhaustive Pattern Learning
Apr 20, 2011
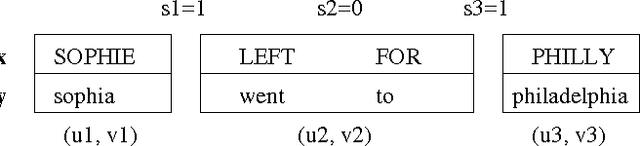
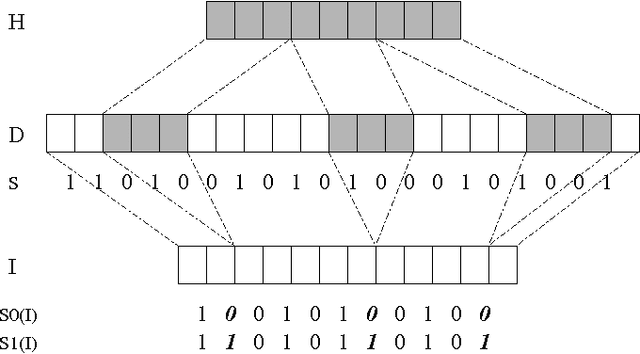
Pattern learning in an important problem in Natural Language Processing (NLP). Some exhaustive pattern learning (EPL) methods (Bod, 1992) were proved to be flawed (Johnson, 2002), while similar algorithms (Och and Ney, 2004) showed great advantages on other tasks, such as machine translation. In this article, we first formalize EPL, and then show that the probability given by an EPL model is constant-factor approximation of the probability given by an ensemble method that integrates exponential number of models obtained with various segmentations of the training data. This work for the first time provides theoretical justification for the widely used EPL algorithm in NLP, which was previously viewed as a flawed heuristic method. Better understanding of EPL may lead to improved pattern learning algorithms in future.