 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Backward and Forward: Self-Knowledge Distillation with Bidirectional Decoder for Neural Machine Translation
Mar 11, 2022

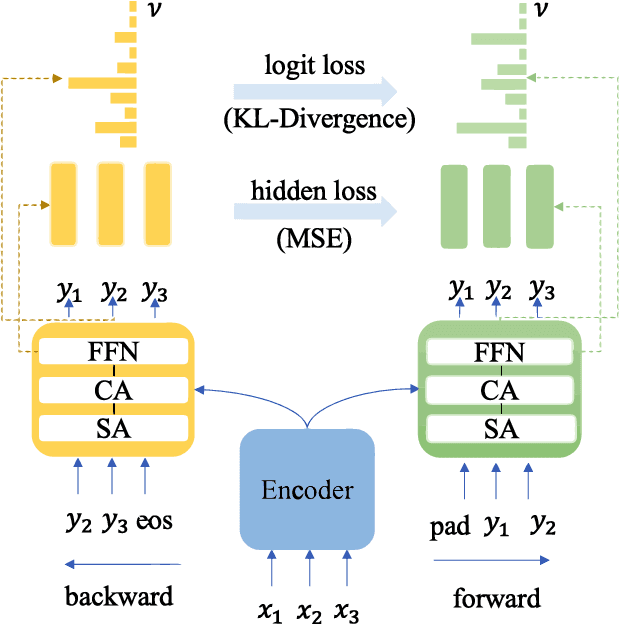
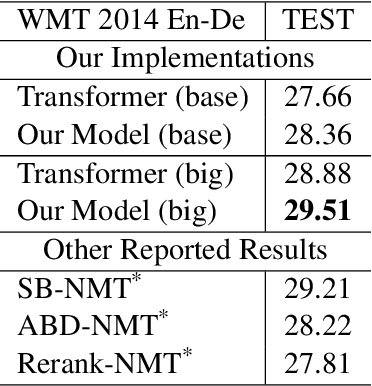
Neural Machine Translation(NMT) models are usually trained via unidirectional decoder which corresponds to optimizing one-step-ahead prediction. However, this kind of unidirectional decoding framework may incline to focus on local structure rather than global coherence. To alleviate this problem, we propose a novel method, Self-Knowledge Distillation with Bidirectional Decoder for Neural Machine Translation(SBD-NMT). We deploy a backward decoder which can act as an effective regularization method to the forward decoder. By leveraging the backward decoder's information about the longer-term future, distilling knowledge learned in the backward decoder can encourage auto-regressive NMT models to plan ahead. Experiments show that our method is significantly better than the strong Transformer baselines on multiple machine translation data sets.