 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
SuperCLUE: A Comprehensive Chinese Large Language Model Benchmark
Jul 27, 2023Large language models (LLMs) have shown the potential to be integrated into human daily lives. Therefore, user preference is the most critical criterion for assessing LLMs' performance in real-world scenarios. However, existing benchmarks mainly focus on measuring models' accuracy using multi-choice questions, which limits the understanding of their capabilities in real applications. We fill this gap by proposing a comprehensive Chinese benchmark SuperCLUE, named after another popular Chinese LLM benchmark CLUE. SuperCLUE encompasses three sub-tasks: actual users' queries and ratings derived from an LLM battle platform (CArena), open-ended questions with single and multiple-turn dialogues (OPEN), and closed-ended questions with the same stems as open-ended single-turn ones (CLOSE). Our study shows that accuracy on closed-ended questions is insufficient to reflect human preferences achieved on open-ended ones. At the same time, they can complement each other to predict actual user preferences. We also demonstrate that GPT-4 is a reliable judge to automatically evaluate human preferences on open-ended questions in a Chinese context. Our benchmark will be released at https://www.CLUEbenchmarks.com
Look Backward and Forward: Self-Knowledge Distillation with Bidirectional Decoder for Neural Machine Translation
Mar 11, 2022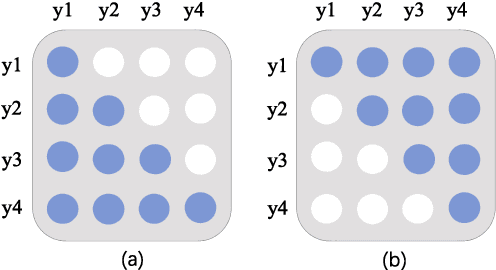

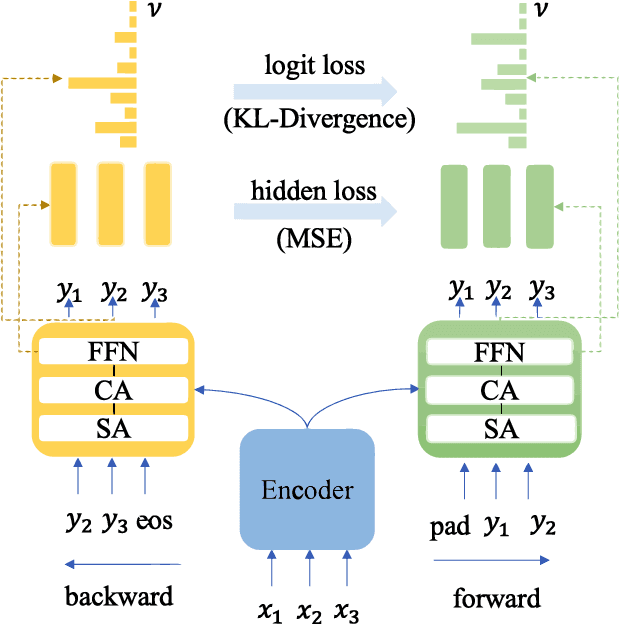
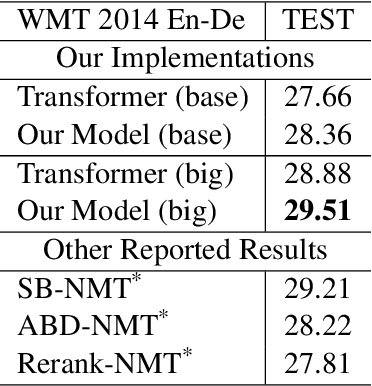
Neural Machine Translation(NMT) models are usually trained via unidirectional decoder which corresponds to optimizing one-step-ahead prediction. However, this kind of unidirectional decoding framework may incline to focus on local structure rather than global coherence. To alleviate this problem, we propose a novel method, Self-Knowledge Distillation with Bidirectional Decoder for Neural Machine Translation(SBD-NMT). We deploy a backward decoder which can act as an effective regularization method to the forward decoder. By leveraging the backward decoder's information about the longer-term future, distilling knowledge learned in the backward decoder can encourage auto-regressive NMT models to plan ahead. Experiments show that our method is significantly better than the strong Transformer baselines on multiple machine translation data sets.
Yuan 1.0: Large-Scale Pre-trained Language Model in Zero-Shot and Few-Shot Learning
Oct 12, 2021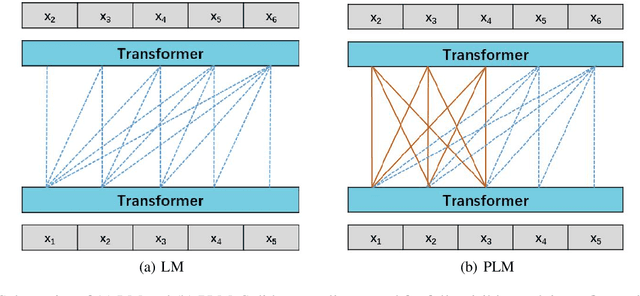

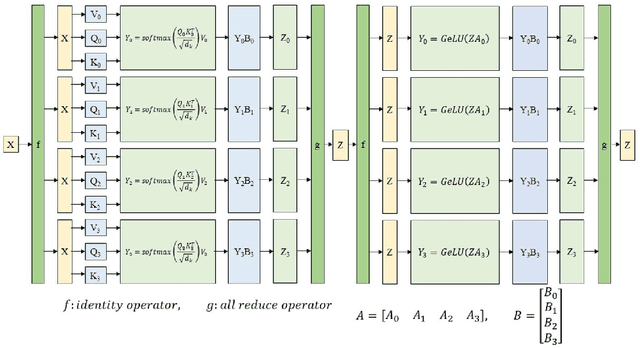

Recent work like GPT-3 has demonstrated excellent performance of Zero-Shot and Few-Shot learning on many natural language processing (NLP) tasks by scaling up model size, dataset size and the amount of computation. However, training a model like GPT-3 requires huge amount of computational resources which makes it challengeable to researchers. In this work, we propose a method that incorporates large-scale distributed training performance into model architecture design. With this method, Yuan 1.0, the current largest singleton language model with 245B parameters, achieves excellent performance on thousands GPUs during training, and the state-of-the-art results on NLP tasks. A data processing method is designed to efficiently filter massive amount of raw data. The current largest high-quality Chinese corpus with 5TB high quality texts is built based on this method. In addition, a calibration and label expansion method is proposed to improve the Zero-Shot and Few-Shot performance, and steady improvement is observed on the accuracy of various tasks. Yuan 1.0 presents strong capacity of natural language generation, and the generated articles are difficult to distinguish from the human-written ones.
FewCLUE: A Chinese Few-shot Learning Evaluation Benchmark
Jul 15, 2021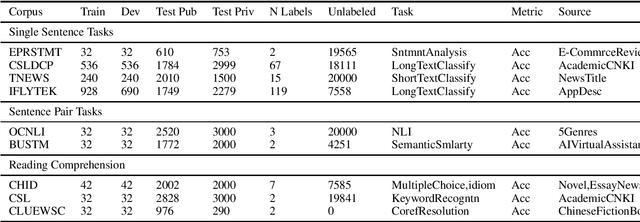
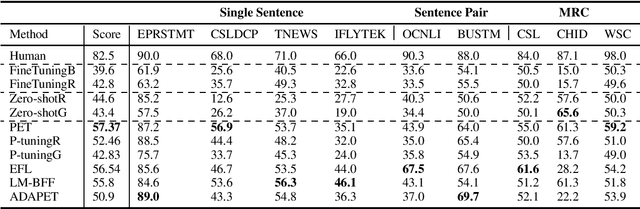

Pretrained Language Models (PLMs) have achieved tremendous success in natural language understanding tasks. While different learning schemes -- fine-tuning, zero-shot and few-shot learning -- have been widely explored and compared for languages such as English, there is comparatively little work in Chinese to fairly and comprehensively evaluate and compare these methods. This work first introduces Chinese Few-shot Learning Evaluation Benchmark (FewCLUE), the first comprehensive small sample evaluation benchmark in Chinese. It includes nine tasks, ranging from single-sentence and sentence-pair classification tasks to machine reading comprehension tasks. Given the high variance of the few-shot learning performance, we provide multiple training/validation sets to facilitate a more accurate and stable evaluation of few-shot modeling. An unlabeled training set with up to 20,000 additional samples per task is provided, allowing researchers to explore better ways of using unlabeled samples. Next, we implement a set of state-of-the-art (SOTA) few-shot learning methods (including PET, ADAPET, LM-BFF, P-tuning and EFL), and compare their performance with fine-tuning and zero-shot learning schemes on the newly constructed FewCLUE benchmark.Our results show that: 1) all five few-shot learning methods exhibit better performance than fine-tuning or zero-shot learning; 2) among the five methods, PET is the best performing few-shot method; 3) few-shot learning performance is highly dependent on the specific task. Our benchmark and code are available at https://github.com/CLUEbenchmark/FewCLUE
CLUE: A Chinese Language Understanding Evaluation Benchmark
Apr 14, 2020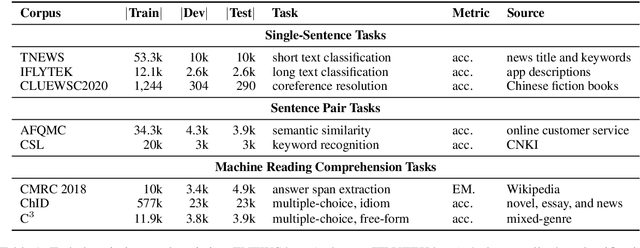
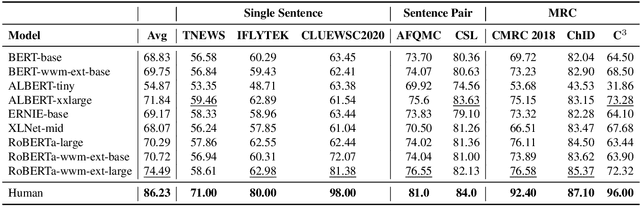
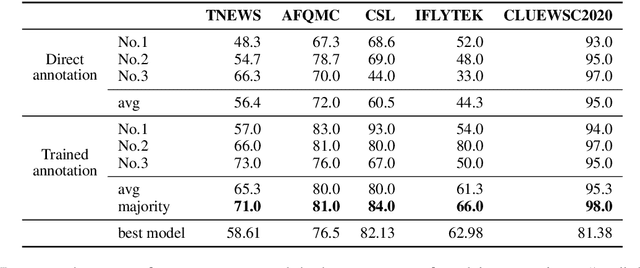
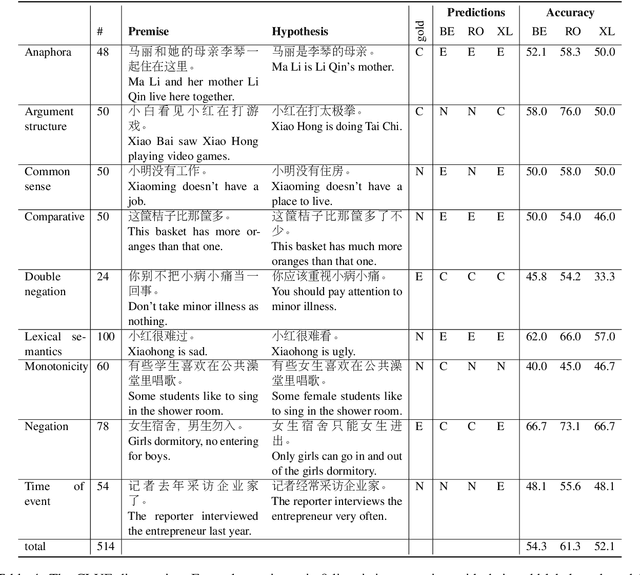
We introduce CLUE, a Chinese Language Understanding Evaluation benchmark. It contains eight different tasks, including single-sentence classification, sentence pair classification, and machine reading comprehension. We evaluate CLUE on a number of existing full-network pre-trained models for Chinese. We also include a small hand-crafted diagnostic test set designed to probe specific linguistic phenomena using different models, some of which are unique to Chinese. Along with CLUE, we release a large clean crawled raw text corpus that can be used for model pre-training. We release CLUE, baselines and pre-training dataset on Github.
CLUECorpus2020: A Large-scale Chinese Corpus for Pre-training Language Model
Mar 05, 2020



In this paper, we introduce the Chinese corpus from CLUE organization, CLUECorpus2020, a large-scale corpus that can be used directly for self-supervised learning such as pre-training of a language model, or language generation. It has 100G raw corpus with 35 billion Chinese characters, which is retrieved from Common Crawl. To better understand this corpus, we conduct language understanding experiments on both small and large scale, and results show that the models trained on this corpus can achieve excellent performance on Chinese. We release a new Chinese vocabulary with a size of 8K, which is only one-third of the vocabulary size used in Chinese Bert released by Google. It saves computational cost and memory while works as good as original vocabulary. We also release both large and tiny versions of the pre-trained model on this corpus. The former achieves the state-of-the-art result, and the latter retains most precision while accelerating training and prediction speed for eight times compared to Bert-base. To facilitate future work on self-supervised learning on Chinese, we release our dataset, new vocabulary, codes, and pre-trained models on Github.
CLUENER2020: Fine-grained Named Entity Recognition Dataset and Benchmark for Chinese
Jan 20, 2020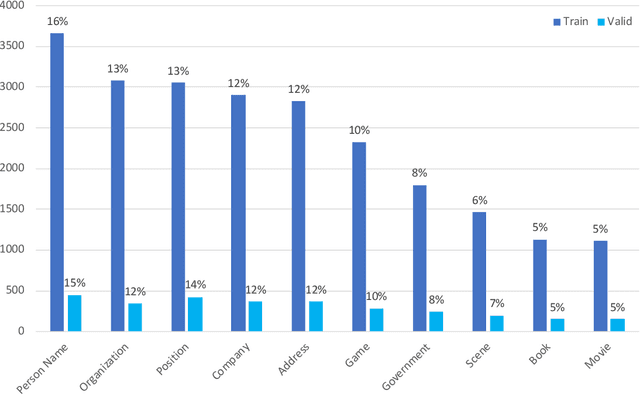

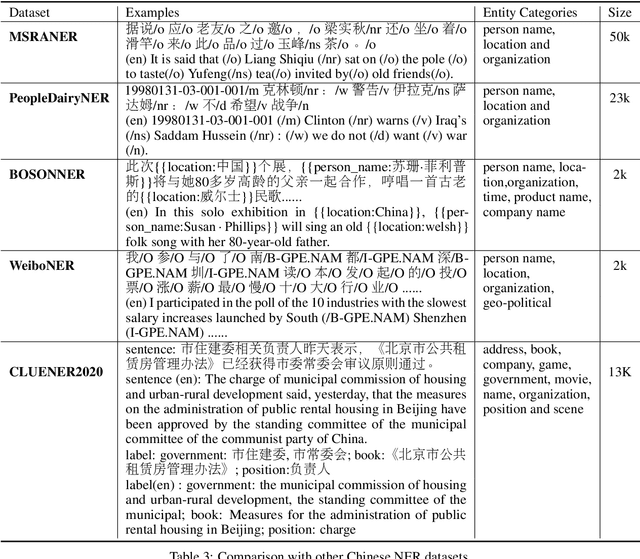
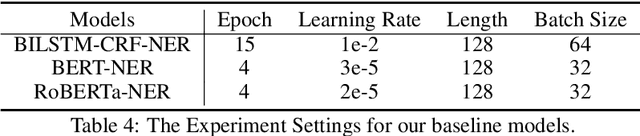
In this paper, we introduce the NER dataset from CLUE organization (CLUENER2020), a well-defined fine-grained dataset for named entity recognition in Chinese. CLUENER2020 contains 10 categories. Apart from common labels like person, organization, and location, it contains more diverse categories. It is more challenging than current other Chinese NER datasets and could better reflect real-world applications. For comparison, we implement several state-of-the-art baselines as sequence labeling tasks and report human performance, as well as its analysis. To facilitate future work on fine-grained NER for Chinese, we release our dataset, baselines, and leader-board.