 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning with Language and Generative Models: Toward General Reward-Guided Wireless Network Design
Jan 30, 2026Intelligent access point (AP) deployment remains challenging in next-generation wireless networks due to complex indoor geometries and signal propagation. We firstly benchmark general-purpose large language models (LLMs) as agentic optimizers for AP planning and find that, despite strong wireless domain knowledge, their dependence on external verifiers results in high computational costs and limited scalability. Motivated by these limitations, we study generative inference models guided by a unified reward function capturing core AP deployment objectives across diverse floorplans. We show that diffusion samplers consistently outperform alternative generative approaches. The diffusion process progressively improves sampling by smoothing and sharpening the reward landscape, rather than relying on iterative refinement, which is effective for non-convex and fragmented objectives. Finally, we introduce a large-scale real-world dataset for indoor AP deployment, requiring over $50k$ CPU hours to train general reward functions, and evaluate in- and out-of-distribution generalization and robustness. Our results suggest that diffusion-based generative inference with a unified reward function provides a scalable and domain-agnostic foundation for indoor AP deployment planning.
Locality in Image Diffusion Models Emerges from Data Statistics
Sep 11, 2025



Among generative models, diffusion models are uniquely intriguing due to the existence of a closed-form optimal minimizer of their training objective, often referred to as the optimal denoiser. However, diffusion using this optimal denoiser merely reproduces images in the training set and hence fails to capture the behavior of deep diffusion models. Recent work has attempted to characterize this gap between the optimal denoiser and deep diffusion models, proposing analytical, training-free models that can generate images that resemble those generated by a trained UNet. The best-performing method hypothesizes that shift equivariance and locality inductive biases of convolutional neural networks are the cause of the performance gap, hence incorporating these assumptions into its analytical model. In this work, we present evidence that the locality in deep diffusion models emerges as a statistical property of the image dataset, not due to the inductive bias of convolutional neural networks. Specifically, we demonstrate that an optimal parametric linear denoiser exhibits similar locality properties to the deep neural denoisers. We further show, both theoretically and experimentally, that this locality arises directly from the pixel correlations present in natural image datasets. Finally, we use these insights to craft an analytical denoiser that better matches scores predicted by a deep diffusion model than the prior expert-crafted alternative.
Stylish and Functional: Guided Interpolation Subject to Physical Constraints
Dec 20, 2024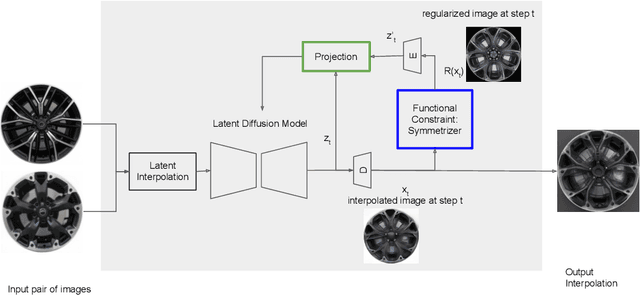



Generative AI is revolutionizing engineering design practices by enabling rapid prototyping and manipulation of designs. One example of design manipulation involves taking two reference design images and using them as prompts to generate a design image that combines aspects of both. Real engineering designs have physical constraints and functional requirements in addition to aesthetic design considerations. Internet-scale foundation models commonly used for image generation, however, are unable to take these physical constraints and functional requirements into consideration as part of the generation process. We consider the problem of generating a design inspired by two input designs, and propose a zero-shot framework toward enforcing physical, functional requirements over the generation process by leveraging a pretrained diffusion model as the backbone. As a case study, we consider the example of rotational symmetry in generation of wheel designs. Automotive wheels are required to be rotationally symmetric for physical stability. We formulate the requirement of rotational symmetry by the use of a symmetrizer, and we use this symmetrizer to guide the diffusion process towards symmetric wheel generations. Our experimental results find that the proposed approach makes generated interpolations with higher realism than methods in related work, as evaluated by Fr\'echet inception distance (FID). We also find that our approach generates designs that more closely satisfy physical and functional requirements than generating without the symmetry guidance.
Enhancing Sample Generation of Diffusion Models using Noise Level Correction
Dec 07, 2024

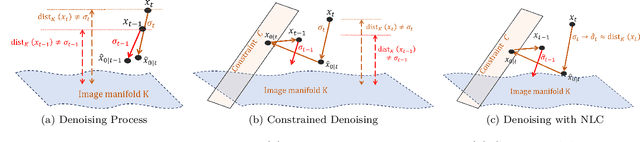
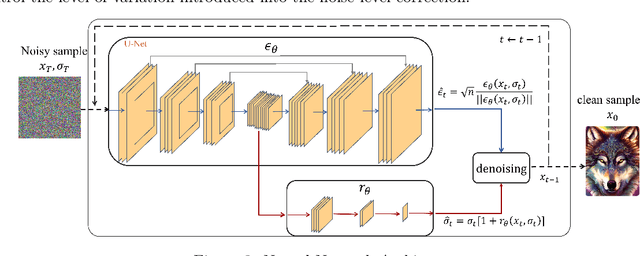
The denoising process of diffusion models can be interpreted as a projection of noisy samples onto the data manifold. Moreover, the noise level in these samples approximates their distance to the underlying manifold. Building on this insight, we propose a novel method to enhance sample generation by aligning the estimated noise level with the true distance of noisy samples to the manifold. Specifically, we introduce a noise level correction network, leveraging a pre-trained denoising network, to refine noise level estimates during the denoising process. Additionally, we extend this approach to various image restoration tasks by integrating task-specific constraints, including inpainting, deblurring, super-resolution, colorization, and compressed sensing. Experimental results demonstrate that our method significantly improves sample quality in both unconstrained and constrained generation scenarios. Notably, the proposed noise level correction framework is compatible with existing denoising schedulers (e.g., DDIM), offering additional performance improvements.
Parametric-ControlNet: Multimodal Control in Foundation Models for Precise Engineering Design Synthesis
Dec 06, 2024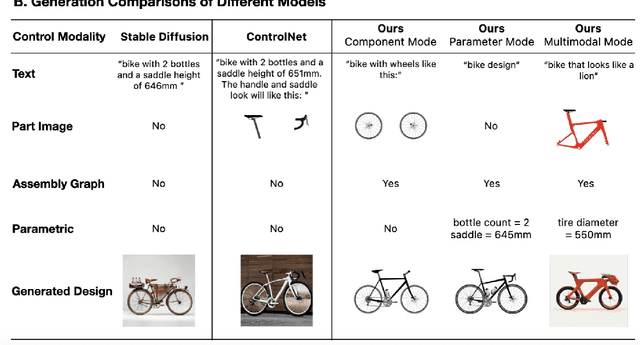

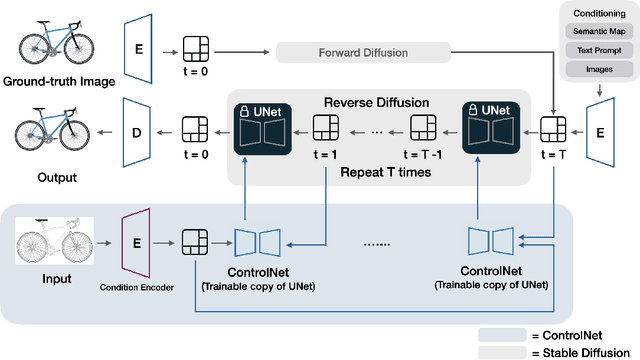
This paper introduces a generative model designed for multimodal control over text-to-image foundation generative AI models such as Stable Diffusion, specifically tailored for engineering design synthesis. Our model proposes parametric, image, and text control modalities to enhance design precision and diversity. Firstly, it handles both partial and complete parametric inputs using a diffusion model that acts as a design autocomplete co-pilot, coupled with a parametric encoder to process the information. Secondly, the model utilizes assembly graphs to systematically assemble input component images, which are then processed through a component encoder to capture essential visual data. Thirdly, textual descriptions are integrated via CLIP encoding, ensuring a comprehensive interpretation of design intent. These diverse inputs are synthesized through a multimodal fusion technique, creating a joint embedding that acts as the input to a module inspired by ControlNet. This integration allows the model to apply robust multimodal control to foundation models, facilitating the generation of complex and precise engineering designs. This approach broadens the capabilities of AI-driven design tools and demonstrates significant advancements in precise control based on diverse data modalities for enhanced design generation.
Bridging Design Gaps: A Parametric Data Completion Approach With Graph Guided Diffusion Models
Jun 17, 2024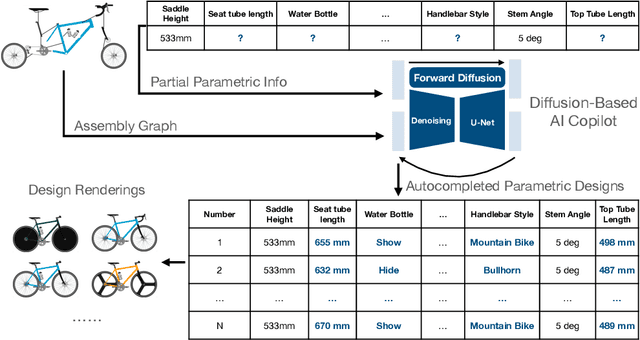

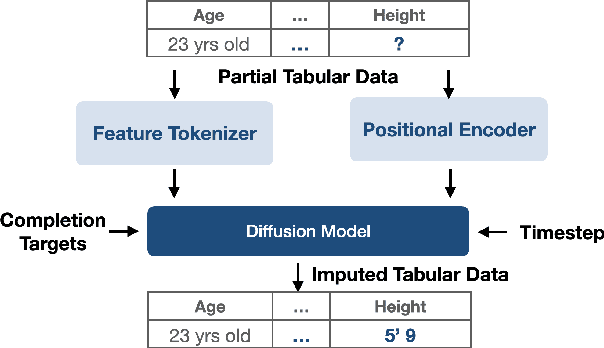
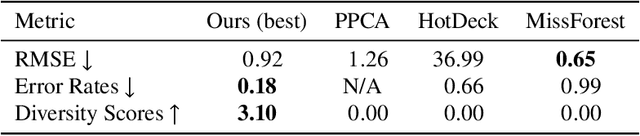
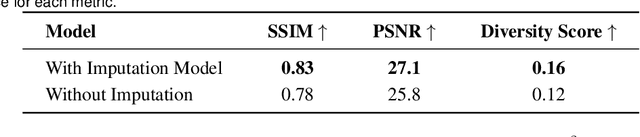
This study introduces a generative imputation model leveraging graph attention networks and tabular diffusion models for completing missing parametric data in engineering designs. This model functions as an AI design co-pilot, providing multiple design options for incomplete designs, which we demonstrate using the bicycle design CAD dataset. Through comparative evaluations, we demonstrate that our model significantly outperforms existing classical methods, such as MissForest, hotDeck, PPCA, and tabular generative method TabCSDI in both the accuracy and diversity of imputation options. Generative modeling also enables a broader exploration of design possibilities, thereby enhancing design decision-making by allowing engineers to explore a variety of design completions. The graph model combines GNNs with the structural information contained in assembly graphs, enabling the model to understand and predict the complex interdependencies between different design parameters. The graph model helps accurately capture and impute complex parametric interdependencies from an assembly graph, which is key for design problems. By learning from an existing dataset of designs, the imputation capability allows the model to act as an intelligent assistant that autocompletes CAD designs based on user-defined partial parametric design, effectively bridging the gap between ideation and realization. The proposed work provides a pathway to not only facilitate informed design decisions but also promote creative exploration in design.
Drag-guided diffusion models for vehicle image generation
Jun 16, 2023
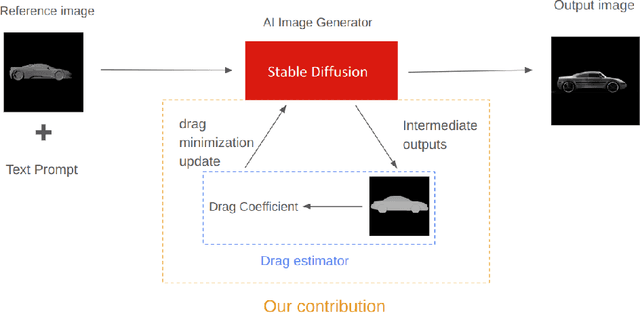

Denoising diffusion models trained at web-scale have revolutionized image generation. The application of these tools to engineering design is an intriguing possibility, but is currently limited by their inability to parse and enforce concrete engineering constraints. In this paper, we take a step towards this goal by proposing physics-based guidance, which enables optimization of a performance metric (as predicted by a surrogate model) during the generation process. As a proof-of-concept, we add drag guidance to Stable Diffusion, which allows this tool to generate images of novel vehicles while simultaneously minimizing their predicted drag coefficients.
Interpreting and Improving Diffusion Models Using the Euclidean Distance Function
Jun 08, 2023



Denoising is intuitively related to projection. Indeed, under the manifold hypothesis, adding random noise is approximately equivalent to orthogonal perturbation. Hence, learning to denoise is approximately learning to project. In this paper, we use this observation to reinterpret denoising diffusion models as approximate gradient descent applied to the Euclidean distance function. We then provide straight-forward convergence analysis of the DDIM sampler under simple assumptions on the projection-error of the denoiser. Finally, we propose a new sampler based on two simple modifications to DDIM using insights from our theoretical results. In as few as 5-10 function evaluations, our sampler achieves state-of-the-art FID scores on pretrained CIFAR-10 and CelebA models and can generate high quality samples on latent diffusion models.
Surrogate Modeling of Car Drag Coefficient with Depth and Normal Renderings
May 26, 2023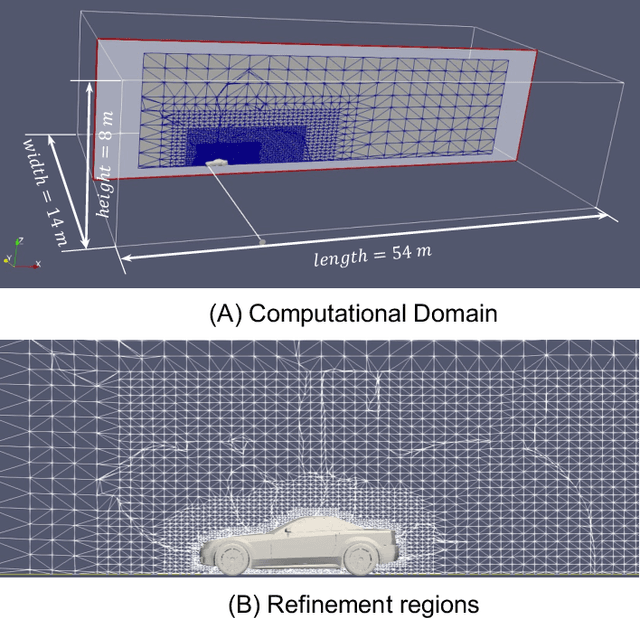
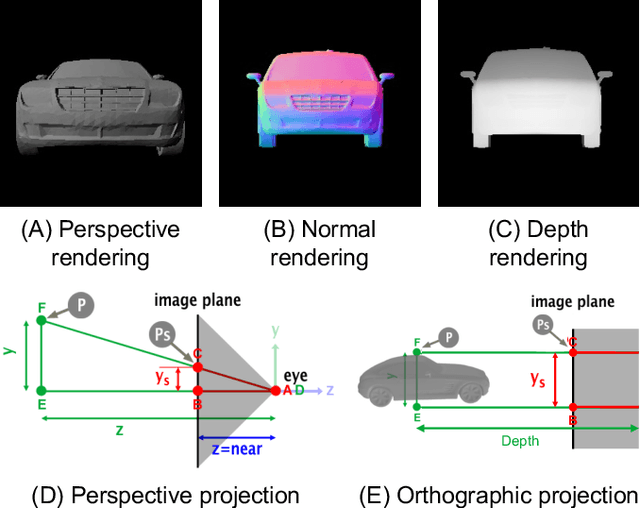
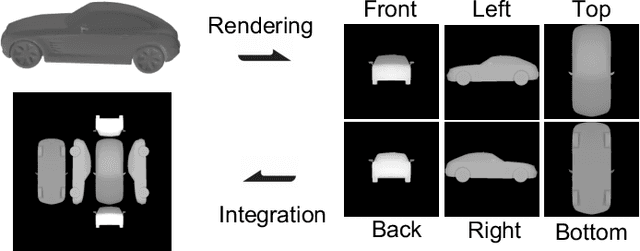
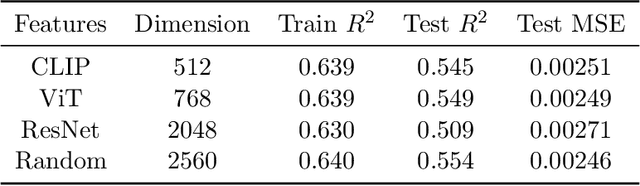
Generative AI models have made significant progress in automating the creation of 3D shapes, which has the potential to transform car design. In engineering design and optimization, evaluating engineering metrics is crucial. To make generative models performance-aware and enable them to create high-performing designs, surrogate modeling of these metrics is necessary. However, the currently used representations of three-dimensional (3D) shapes either require extensive computational resources to learn or suffer from significant information loss, which impairs their effectiveness in surrogate modeling. To address this issue, we propose a new two-dimensional (2D) representation of 3D shapes. We develop a surrogate drag model based on this representation to verify its effectiveness in predicting 3D car drag. We construct a diverse dataset of 9,070 high-quality 3D car meshes labeled by drag coefficients computed from computational fluid dynamics (CFD) simulations to train our model. Our experiments demonstrate that our model can accurately and efficiently evaluate drag coefficients with an $R^2$ value above 0.84 for various car categories. Moreover, the proposed representation method can be generalized to many other product categories beyond cars. Our model is implemented using deep neural networks, making it compatible with recent AI image generation tools (such as Stable Diffusion) and a significant step towards the automatic generation of drag-optimized car designs. We have made the dataset and code publicly available at https://decode.mit.edu/projects/dragprediction/.
FewCLUE: A Chinese Few-shot Learning Evaluation Benchmark
Jul 15, 2021
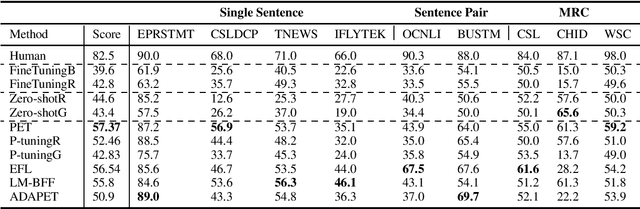

Pretrained Language Models (PLMs) have achieved tremendous success in natural language understanding tasks. While different learning schemes -- fine-tuning, zero-shot and few-shot learning -- have been widely explored and compared for languages such as English, there is comparatively little work in Chinese to fairly and comprehensively evaluate and compare these methods. This work first introduces Chinese Few-shot Learning Evaluation Benchmark (FewCLUE), the first comprehensive small sample evaluation benchmark in Chinese. It includes nine tasks, ranging from single-sentence and sentence-pair classification tasks to machine reading comprehension tasks. Given the high variance of the few-shot learning performance, we provide multiple training/validation sets to facilitate a more accurate and stable evaluation of few-shot modeling. An unlabeled training set with up to 20,000 additional samples per task is provided, allowing researchers to explore better ways of using unlabeled samples. Next, we implement a set of state-of-the-art (SOTA) few-shot learning methods (including PET, ADAPET, LM-BFF, P-tuning and EFL), and compare their performance with fine-tuning and zero-shot learning schemes on the newly constructed FewCLUE benchmark.Our results show that: 1) all five few-shot learning methods exhibit better performance than fine-tuning or zero-shot learning; 2) among the five methods, PET is the best performing few-shot method; 3) few-shot learning performance is highly dependent on the specific task. Our benchmark and code are available at https://github.com/CLUEbenchmark/FewCLUE