 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFewCLUE: A Chinese Few-shot Learning Evaluation Benchmark
Jul 15, 2021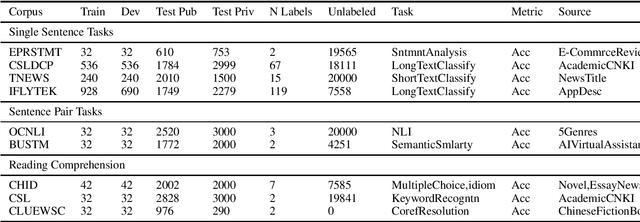
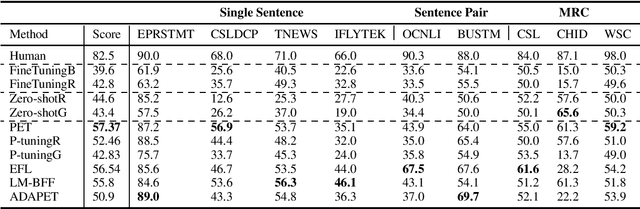

Pretrained Language Models (PLMs) have achieved tremendous success in natural language understanding tasks. While different learning schemes -- fine-tuning, zero-shot and few-shot learning -- have been widely explored and compared for languages such as English, there is comparatively little work in Chinese to fairly and comprehensively evaluate and compare these methods. This work first introduces Chinese Few-shot Learning Evaluation Benchmark (FewCLUE), the first comprehensive small sample evaluation benchmark in Chinese. It includes nine tasks, ranging from single-sentence and sentence-pair classification tasks to machine reading comprehension tasks. Given the high variance of the few-shot learning performance, we provide multiple training/validation sets to facilitate a more accurate and stable evaluation of few-shot modeling. An unlabeled training set with up to 20,000 additional samples per task is provided, allowing researchers to explore better ways of using unlabeled samples. Next, we implement a set of state-of-the-art (SOTA) few-shot learning methods (including PET, ADAPET, LM-BFF, P-tuning and EFL), and compare their performance with fine-tuning and zero-shot learning schemes on the newly constructed FewCLUE benchmark.Our results show that: 1) all five few-shot learning methods exhibit better performance than fine-tuning or zero-shot learning; 2) among the five methods, PET is the best performing few-shot method; 3) few-shot learning performance is highly dependent on the specific task. Our benchmark and code are available at https://github.com/CLUEbenchmark/FewCLUE
A Generic Network Compression Framework for Sequential Recommender Systems
May 26, 2020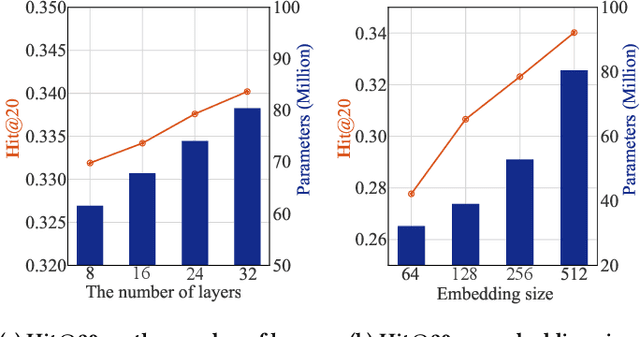
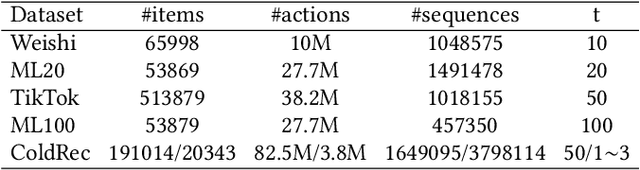
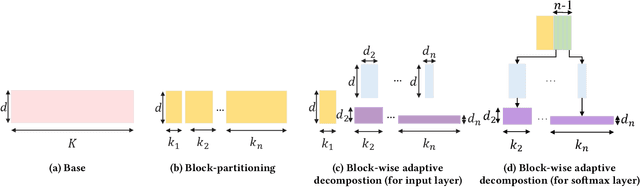
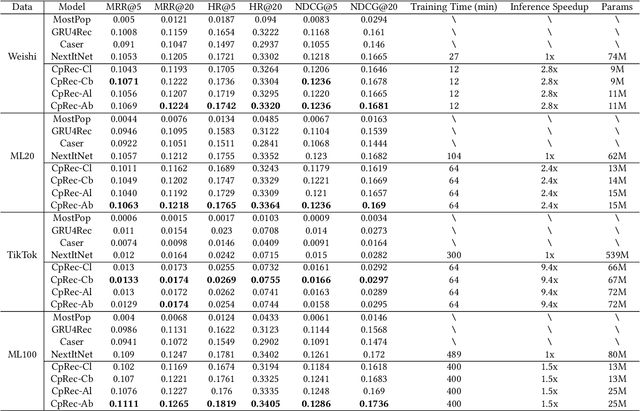
Sequential recommender systems (SRS) have become the key technology in capturing user's dynamic interests and generating high-quality recommendations. Current state-of-the-art sequential recommender models are typically based on a sandwich-structured deep neural network, where one or more middle (hidden) layers are placed between the input embedding layer and output softmax layer. In general, these models require a large number of parameters (such as using a large embedding dimension or a deep network architecture) to obtain their optimal performance. Despite the effectiveness, at some point, further increasing model size may be harder for model deployment in resource-constraint devices, resulting in longer responding time and larger memory footprint. To resolve the issues, we propose a compressed sequential recommendation framework, termed as CpRec, where two generic model shrinking techniques are employed. Specifically, we first propose a block-wise adaptive decomposition to approximate the input and softmax matrices by exploiting the fact that items in SRS obey a long-tailed distribution. To reduce the parameters of the middle layers, we introduce three layer-wise parameter sharing schemes. We instantiate CpRec using deep convolutional neural network with dilated kernels given consideration to both recommendation accuracy and efficiency. By the extensive ablation studies, we demonstrate that the proposed CpRec can achieve up to 4$\sim$8 times compression rates in real-world SRS datasets. Meanwhile, CpRec is faster during training\inference, and in most cases outperforms its uncompressed counterpart.