 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAerial Vision-Language Navigation with a Unified Framework for Spatial, Temporal and Embodied Reasoning
Dec 09, 2025Aerial Vision-and-Language Navigation (VLN) aims to enable unmanned aerial vehicles (UAVs) to interpret natural language instructions and navigate complex urban environments using onboard visual observation. This task holds promise for real-world applications such as low-altitude inspection, search-and-rescue, and autonomous aerial delivery. Existing methods often rely on panoramic images, depth inputs, or odometry to support spatial reasoning and action planning. These requirements increase system cost and integration complexity, thus hindering practical deployment for lightweight UAVs. We present a unified aerial VLN framework that operates solely on egocentric monocular RGB observations and natural language instructions. The model formulates navigation as a next-token prediction problem, jointly optimizing spatial perception, trajectory reasoning, and action prediction through prompt-guided multi-task learning. Moreover, we propose a keyframe selection strategy to reduce visual redundancy by retaining semantically informative frames, along with an action merging and label reweighting mechanism that mitigates long-tailed supervision imbalance and facilitates stable multi-task co-training. Extensive experiments on the Aerial VLN benchmark validate the effectiveness of our method. Under the challenging monocular RGB-only setting, our model achieves strong results across both seen and unseen environments. It significantly outperforms existing RGB-only baselines and narrows the performance gap with state-of-the-art panoramic RGB-D counterparts. Comprehensive ablation studies further demonstrate the contribution of our task design and architectural choices.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Learning Physical Dynamics for Object-centric Visual Prediction
Mar 15, 2024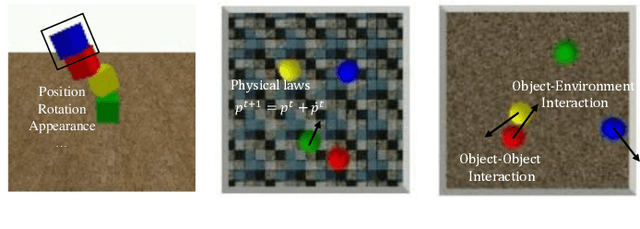
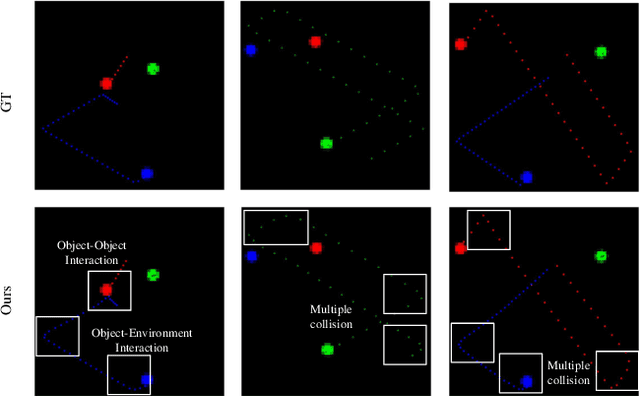
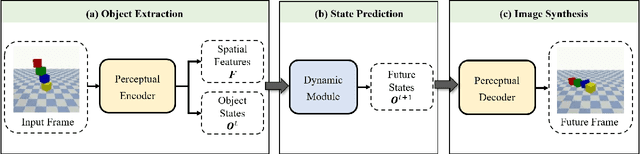
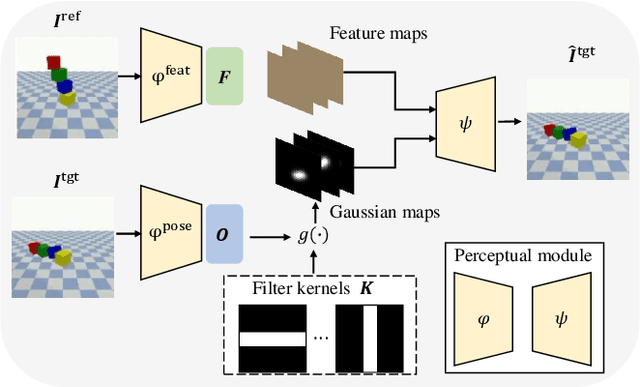
The ability to model the underlying dynamics of visual scenes and reason about the future is central to human intelligence. Many attempts have been made to empower intelligent systems with such physical understanding and prediction abilities. However, most existing methods focus on pixel-to-pixel prediction, which suffers from heavy computational costs while lacking a deep understanding of the physical dynamics behind videos. Recently, object-centric prediction methods have emerged and attracted increasing interest. Inspired by it, this paper proposes an unsupervised object-centric prediction model that makes future predictions by learning visual dynamics between objects. Our model consists of two modules, perceptual, and dynamic module. The perceptual module is utilized to decompose images into several objects and synthesize images with a set of object-centric representations. The dynamic module fuses contextual information, takes environment-object and object-object interaction into account, and predicts the future trajectory of objects. Extensive experiments are conducted to validate the effectiveness of the proposed method. Both quantitative and qualitative experimental results demonstrate that our model generates higher visual quality and more physically reliable predictions compared to the state-of-the-art methods.
Open-sourced Data Ecosystem in Autonomous Driving: the Present and Future
Dec 06, 2023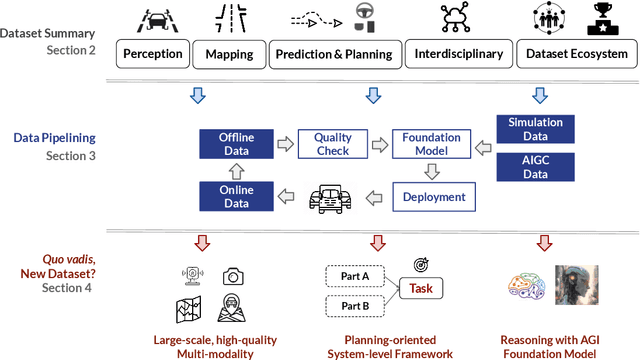
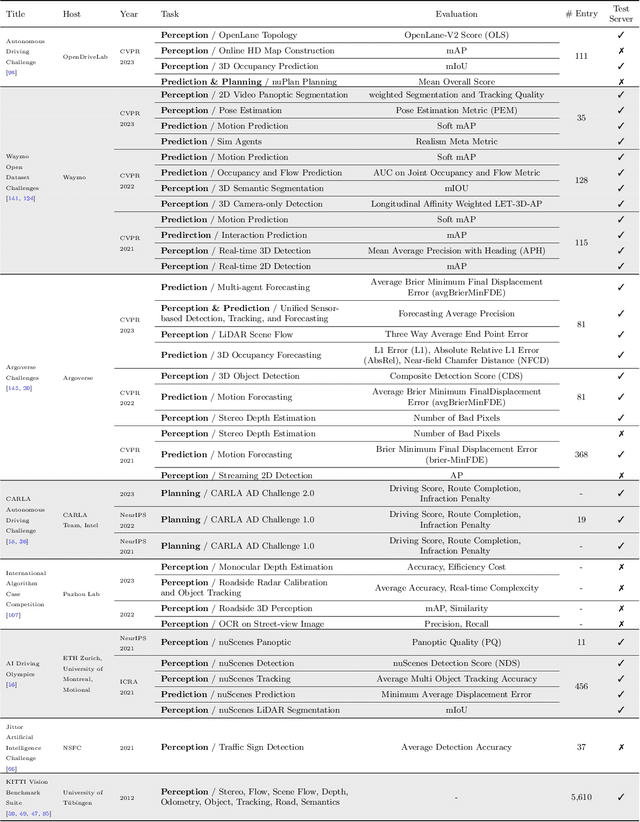
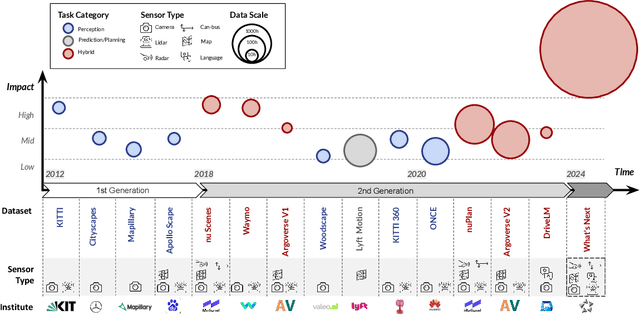
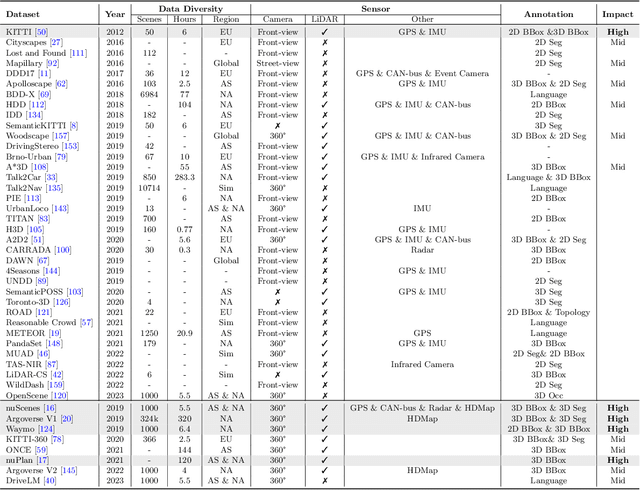
With the continuous maturation and application of autonomous driving technology, a systematic examination of open-source autonomous driving datasets becomes instrumental in fostering the robust evolution of the industry ecosystem. Current autonomous driving datasets can broadly be categorized into two generations. The first-generation autonomous driving datasets are characterized by relatively simpler sensor modalities, smaller data scale, and is limited to perception-level tasks. KITTI, introduced in 2012, serves as a prominent representative of this initial wave. In contrast, the second-generation datasets exhibit heightened complexity in sensor modalities, greater data scale and diversity, and an expansion of tasks from perception to encompass prediction and control. Leading examples of the second generation include nuScenes and Waymo, introduced around 2019. This comprehensive review, conducted in collaboration with esteemed colleagues from both academia and industry, systematically assesses over seventy open-source autonomous driving datasets from domestic and international sources. It offers insights into various aspects, such as the principles underlying the creation of high-quality datasets, the pivotal role of data engine systems, and the utilization of generative foundation models to facilitate scalable data generation. Furthermore, this review undertakes an exhaustive analysis and discourse regarding the characteristics and data scales that future third-generation autonomous driving datasets should possess. It also delves into the scientific and technical challenges that warrant resolution. These endeavors are pivotal in advancing autonomous innovation and fostering technological enhancement in critical domains. For further details, please refer to https://github.com/OpenDriveLab/DriveAGI.
Physics-assisted Deep Learning for FMCW Radar Quantitative Imaging of Two-dimension Target
Jul 05, 2023



Radar imaging is crucial in remote sensing and has many applications in detection and autonomous driving. However, the received radar signal for imaging is enormous and redundant, which degrades the speed of real-time radar quantitative imaging and leads to obstacles in the downlink applications. In this paper, we propose a physics-assisted deep learning method for radar quantitative imaging with the advantage of compressed sensing (CS). Specifically, the signal model for frequency-modulated continuous-wave (FMCW) radar imaging which only uses four antennas and parts of frequency components is formulated in terms of matrices multiplication. The learned fast iterative shrinkage-thresholding algorithm with residual neural network (L-FISTA-ResNet) is proposed for solving the quantitative imaging problem. The L-FISTA is developed to ensure the basic solution and ResNet is attached to enhance the image quality. Simulation results show that our proposed method has higher reconstruction accuracy than the traditional optimization method and pure neural networks. The effectiveness and generalization performance of the proposed strategy is verified in unseen target imaging, denoising, and frequency migration tasks.
FewCLUE: A Chinese Few-shot Learning Evaluation Benchmark
Jul 15, 2021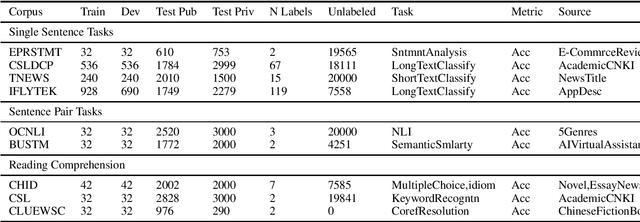
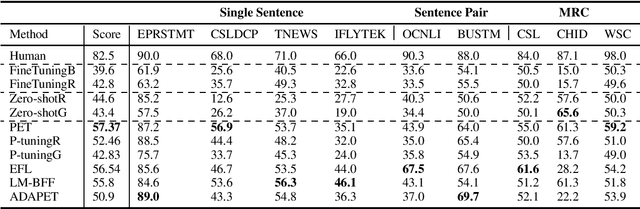

Pretrained Language Models (PLMs) have achieved tremendous success in natural language understanding tasks. While different learning schemes -- fine-tuning, zero-shot and few-shot learning -- have been widely explored and compared for languages such as English, there is comparatively little work in Chinese to fairly and comprehensively evaluate and compare these methods. This work first introduces Chinese Few-shot Learning Evaluation Benchmark (FewCLUE), the first comprehensive small sample evaluation benchmark in Chinese. It includes nine tasks, ranging from single-sentence and sentence-pair classification tasks to machine reading comprehension tasks. Given the high variance of the few-shot learning performance, we provide multiple training/validation sets to facilitate a more accurate and stable evaluation of few-shot modeling. An unlabeled training set with up to 20,000 additional samples per task is provided, allowing researchers to explore better ways of using unlabeled samples. Next, we implement a set of state-of-the-art (SOTA) few-shot learning methods (including PET, ADAPET, LM-BFF, P-tuning and EFL), and compare their performance with fine-tuning and zero-shot learning schemes on the newly constructed FewCLUE benchmark.Our results show that: 1) all five few-shot learning methods exhibit better performance than fine-tuning or zero-shot learning; 2) among the five methods, PET is the best performing few-shot method; 3) few-shot learning performance is highly dependent on the specific task. Our benchmark and code are available at https://github.com/CLUEbenchmark/FewCLUE