 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Physical Dynamics for Object-centric Visual Prediction
Paper and Code
Mar 15, 2024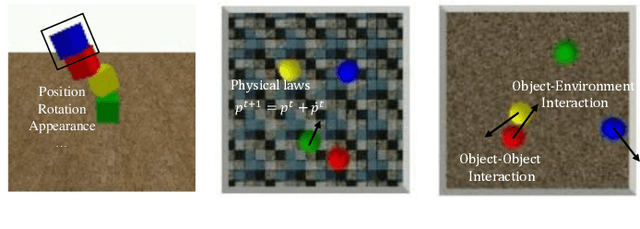
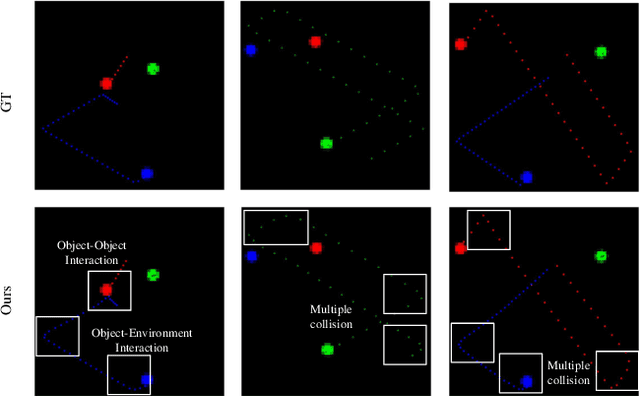
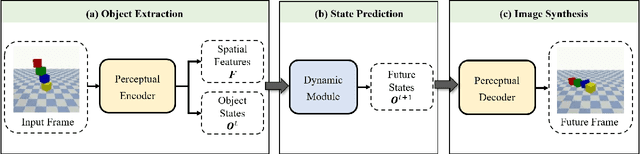
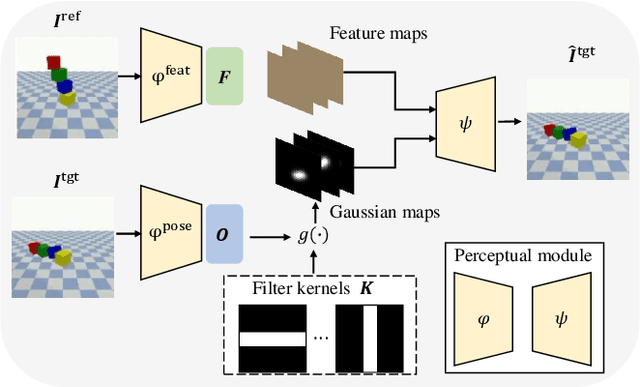
The ability to model the underlying dynamics of visual scenes and reason about the future is central to human intelligence. Many attempts have been made to empower intelligent systems with such physical understanding and prediction abilities. However, most existing methods focus on pixel-to-pixel prediction, which suffers from heavy computational costs while lacking a deep understanding of the physical dynamics behind videos. Recently, object-centric prediction methods have emerged and attracted increasing interest. Inspired by it, this paper proposes an unsupervised object-centric prediction model that makes future predictions by learning visual dynamics between objects. Our model consists of two modules, perceptual, and dynamic module. The perceptual module is utilized to decompose images into several objects and synthesize images with a set of object-centric representations. The dynamic module fuses contextual information, takes environment-object and object-object interaction into account, and predicts the future trajectory of objects. Extensive experiments are conducted to validate the effectiveness of the proposed method. Both quantitative and qualitative experimental results demonstrate that our model generates higher visual quality and more physically reliable predictions compared to the state-of-the-art methods.