 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParametric-ControlNet: Multimodal Control in Foundation Models for Precise Engineering Design Synthesis
Paper and Code
Dec 06, 2024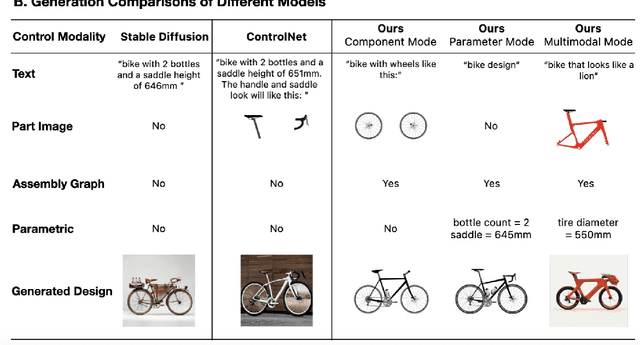

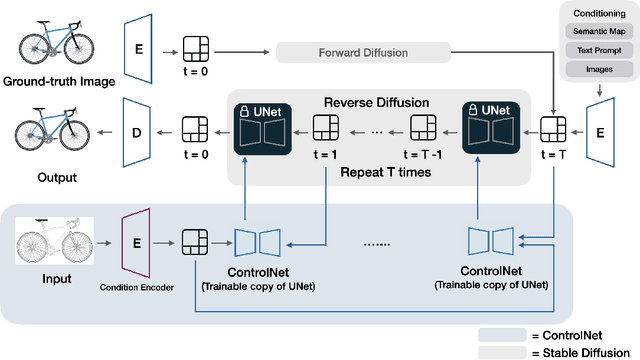
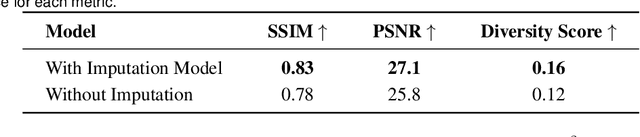
This paper introduces a generative model designed for multimodal control over text-to-image foundation generative AI models such as Stable Diffusion, specifically tailored for engineering design synthesis. Our model proposes parametric, image, and text control modalities to enhance design precision and diversity. Firstly, it handles both partial and complete parametric inputs using a diffusion model that acts as a design autocomplete co-pilot, coupled with a parametric encoder to process the information. Secondly, the model utilizes assembly graphs to systematically assemble input component images, which are then processed through a component encoder to capture essential visual data. Thirdly, textual descriptions are integrated via CLIP encoding, ensuring a comprehensive interpretation of design intent. These diverse inputs are synthesized through a multimodal fusion technique, creating a joint embedding that acts as the input to a module inspired by ControlNet. This integration allows the model to apply robust multimodal control to foundation models, facilitating the generation of complex and precise engineering designs. This approach broadens the capabilities of AI-driven design tools and demonstrates significant advancements in precise control based on diverse data modalities for enhanced design generation.