 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Quality Enhancement on the Basis of Diversity with Large Language Models for Text Classification: Uncovered, Difficult, and Noisy
Dec 10, 2024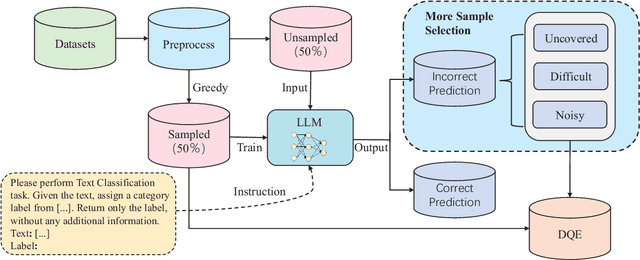
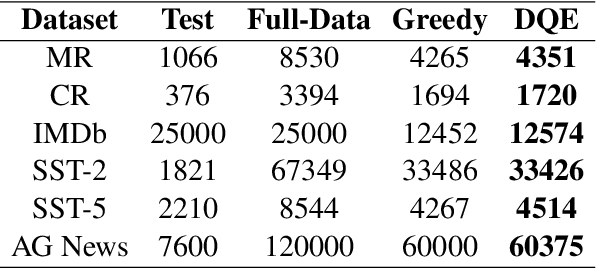
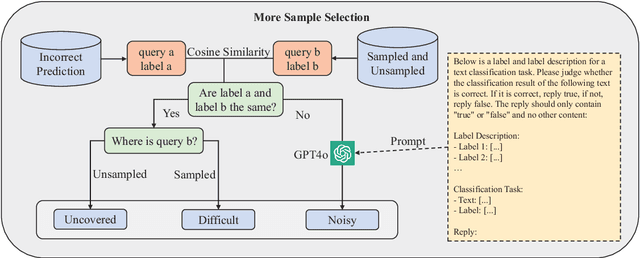
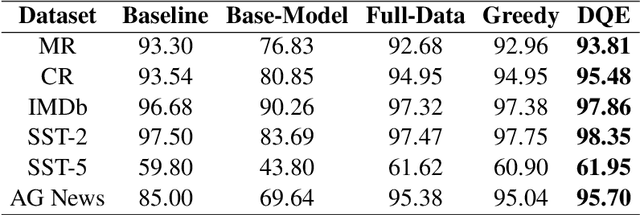
In recent years, the use of large language models (LLMs) for text classification has attracted widespread attention. Despite this, the classification accuracy of LLMs has not yet universally surpassed that of smaller models. LLMs can enhance their performance in text classification through fine-tuning. However, existing data quality research based on LLMs is challenging to apply directly to solve text classification problems. To further improve the performance of LLMs in classification tasks, this paper proposes a data quality enhancement (DQE) method for text classification based on LLMs. This method starts by using a greedy algorithm to select data, dividing the dataset into sampled and unsampled subsets, and then performing fine-tuning of the LLMs using the sampled data. Subsequently, this model is used to predict the outcomes for the unsampled data, categorizing incorrectly predicted data into uncovered, difficult, and noisy data. Experimental results demonstrate that our method effectively enhances the performance of LLMs in text classification tasks and significantly improves training efficiency, saving nearly half of the training time. Our method has achieved state-of-the-art performance in several open-source classification tasks.
CLUENER2020: Fine-grained Named Entity Recognition Dataset and Benchmark for Chinese
Jan 20, 2020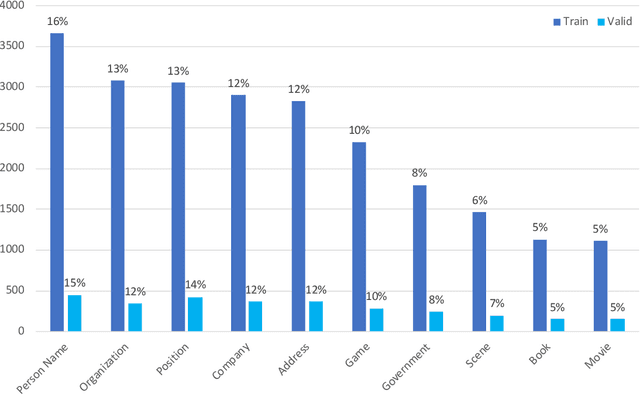

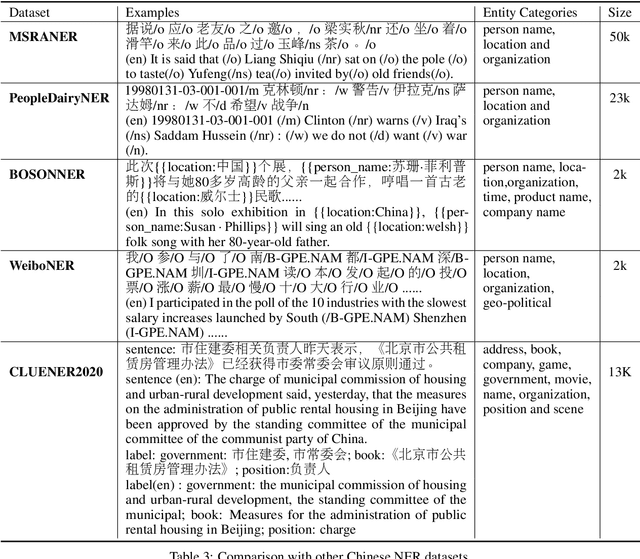
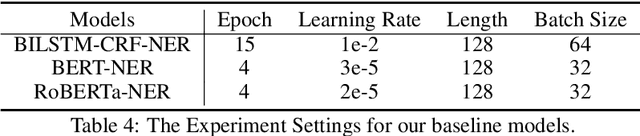
In this paper, we introduce the NER dataset from CLUE organization (CLUENER2020), a well-defined fine-grained dataset for named entity recognition in Chinese. CLUENER2020 contains 10 categories. Apart from common labels like person, organization, and location, it contains more diverse categories. It is more challenging than current other Chinese NER datasets and could better reflect real-world applications. For comparison, we implement several state-of-the-art baselines as sequence labeling tasks and report human performance, as well as its analysis. To facilitate future work on fine-grained NER for Chinese, we release our dataset, baselines, and leader-board.