 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperCLUE-Fin: Graded Fine-Grained Analysis of Chinese LLMs on Diverse Financial Tasks and Applications
Apr 29, 2024
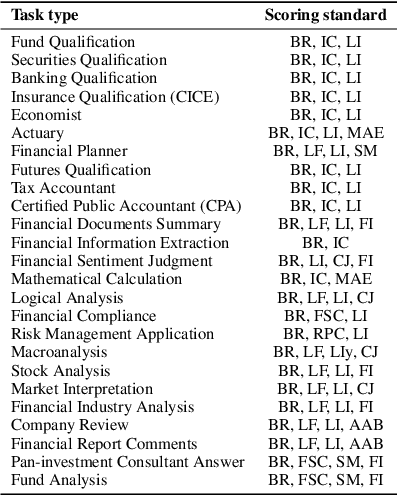


The SuperCLUE-Fin (SC-Fin) benchmark is a pioneering evaluation framework tailored for Chinese-native financial large language models (FLMs). It assesses FLMs across six financial application domains and twenty-five specialized tasks, encompassing theoretical knowledge and practical applications such as compliance, risk management, and investment analysis. Using multi-turn, open-ended conversations that mimic real-life scenarios, SC-Fin measures models on a range of criteria, including accurate financial understanding, logical reasoning, clarity, computational efficiency, business acumen, risk perception, and compliance with Chinese regulations. In a rigorous evaluation involving over a thousand questions, SC-Fin identifies a performance hierarchy where domestic models like GLM-4 and MoonShot-v1-128k outperform others with an A-grade, highlighting the potential for further development in transforming theoretical knowledge into pragmatic financial solutions. This benchmark serves as a critical tool for refining FLMs in the Chinese context, directing improvements in financial knowledge databases, standardizing financial interpretations, and promoting models that prioritize compliance, risk management, and secure practices. We create a contextually relevant and comprehensive benchmark that drives the development of AI in the Chinese financial sector. SC-Fin facilitates the advancement and responsible deployment of FLMs, offering valuable insights for enhancing model performance and usability for both individual and institutional users in the Chinese market..~\footnote{Our benchmark can be found at \url{https://www.CLUEbenchmarks.com}}.
SuperCLUE-Math6: Graded Multi-Step Math Reasoning Benchmark for LLMs in Chinese
Feb 02, 2024We introduce SuperCLUE-Math6(SC-Math6), a new benchmark dataset to evaluate the mathematical reasoning abilities of Chinese language models. SC-Math6 is designed as an upgraded Chinese version of the GSM8K dataset with enhanced difficulty, diversity, and application scope. It consists of over 2000 mathematical word problems requiring multi-step reasoning and providing natural language solutions. We propose an innovative scheme to quantify the reasoning capability of large models based on performance over problems with different reasoning steps. Experiments on 13 representative Chinese models demonstrate a clear stratification of reasoning levels, with top models like GPT-4 showing superior performance. SC-Math6 fills the gap in Chinese mathematical reasoning benchmarks and provides a comprehensive testbed to advance the intelligence of Chinese language models.
SC-Safety: A Multi-round Open-ended Question Adversarial Safety Benchmark for Large Language Models in Chinese
Oct 09, 2023



Large language models (LLMs), like ChatGPT and GPT-4, have demonstrated remarkable abilities in natural language understanding and generation. However, alongside their positive impact on our daily tasks, they can also produce harmful content that negatively affects societal perceptions. To systematically assess the safety of Chinese LLMs, we introduce SuperCLUE-Safety (SC-Safety) - a multi-round adversarial benchmark with 4912 open-ended questions covering more than 20 safety sub-dimensions. Adversarial human-model interactions and conversations significantly increase the challenges compared to existing methods. Experiments on 13 major LLMs supporting Chinese yield the following insights: 1) Closed-source models outperform open-sourced ones in terms of safety; 2) Models released from China demonstrate comparable safety levels to LLMs like GPT-3.5-turbo; 3) Some smaller models with 6B-13B parameters can compete effectively in terms of safety. By introducing SC-Safety, we aim to promote collaborative efforts to create safer and more trustworthy LLMs. The benchmark and findings provide guidance on model selection. Our benchmark can be found at https://www.CLUEbenchmarks.com
SuperCLUE: A Comprehensive Chinese Large Language Model Benchmark
Jul 27, 2023Large language models (LLMs) have shown the potential to be integrated into human daily lives. Therefore, user preference is the most critical criterion for assessing LLMs' performance in real-world scenarios. However, existing benchmarks mainly focus on measuring models' accuracy using multi-choice questions, which limits the understanding of their capabilities in real applications. We fill this gap by proposing a comprehensive Chinese benchmark SuperCLUE, named after another popular Chinese LLM benchmark CLUE. SuperCLUE encompasses three sub-tasks: actual users' queries and ratings derived from an LLM battle platform (CArena), open-ended questions with single and multiple-turn dialogues (OPEN), and closed-ended questions with the same stems as open-ended single-turn ones (CLOSE). Our study shows that accuracy on closed-ended questions is insufficient to reflect human preferences achieved on open-ended ones. At the same time, they can complement each other to predict actual user preferences. We also demonstrate that GPT-4 is a reliable judge to automatically evaluate human preferences on open-ended questions in a Chinese context. Our benchmark will be released at https://www.CLUEbenchmarks.com