 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvSearch-R1: Enhancing Query Reformulation for Conversational Search with Reasoning via Reinforcement Learning
May 21, 2025Conversational search systems require effective handling of context-dependent queries that often contain ambiguity, omission, and coreference. Conversational Query Reformulation (CQR) addresses this challenge by transforming these queries into self-contained forms suitable for off-the-shelf retrievers. However, existing CQR approaches suffer from two critical constraints: high dependency on costly external supervision from human annotations or large language models, and insufficient alignment between the rewriting model and downstream retrievers. We present ConvSearch-R1, the first self-driven framework that completely eliminates dependency on external rewrite supervision by leveraging reinforcement learning to optimize reformulation directly through retrieval signals. Our novel two-stage approach combines Self-Driven Policy Warm-Up to address the cold-start problem through retrieval-guided self-distillation, followed by Retrieval-Guided Reinforcement Learning with a specially designed rank-incentive reward shaping mechanism that addresses the sparsity issue in conventional retrieval metrics. Extensive experiments on TopiOCQA and QReCC datasets demonstrate that ConvSearch-R1 significantly outperforms previous state-of-the-art methods, achieving over 10% improvement on the challenging TopiOCQA dataset while using smaller 3B parameter models without any external supervision.
LLatrieval: LLM-Verified Retrieval for Verifiable Generation
Nov 14, 2023


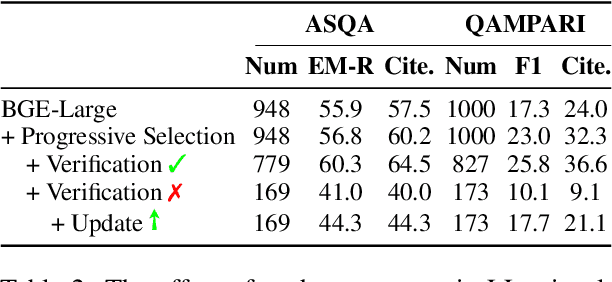
Verifiable generation aims to let the large language model (LLM) generate text with corresponding supporting documents, which enables the user to flexibly verify the answer and makes it more trustworthy. Its evaluation not only measures the correctness of the answer, but also the answer's verifiability, i.e., how well the answer is supported by the corresponding documents. In typical, verifiable generation adopts the retrieval-read pipeline, which is divided into two stages: 1) retrieve relevant documents of the question. 2) according to the documents, generate the corresponding answer. Since the retrieved documents can supplement knowledge for the LLM to generate the answer and serve as evidence, the retrieval stage is essential for the correctness and verifiability of the answer. However, the widely used retrievers become the bottleneck of the entire pipeline and limit the overall performance. They often have fewer parameters than the large language model and have not been proven to scale well to the size of LLMs. Since the LLM passively receives the retrieval result, if the retriever does not correctly find the supporting documents, the LLM can not generate the correct and verifiable answer, which overshadows the LLM's remarkable abilities. In this paper, we propose LLatrieval (Large Language Model Verified Retrieval), where the LLM updates the retrieval result until it verifies that the retrieved documents can support answering the question. Thus, the LLM can iteratively provide feedback to retrieval and facilitate the retrieval result to sufficiently support verifiable generation. Experimental results show that our method significantly outperforms extensive baselines and achieves new state-of-the-art results.
SuperCLUE: A Comprehensive Chinese Large Language Model Benchmark
Jul 27, 2023Large language models (LLMs) have shown the potential to be integrated into human daily lives. Therefore, user preference is the most critical criterion for assessing LLMs' performance in real-world scenarios. However, existing benchmarks mainly focus on measuring models' accuracy using multi-choice questions, which limits the understanding of their capabilities in real applications. We fill this gap by proposing a comprehensive Chinese benchmark SuperCLUE, named after another popular Chinese LLM benchmark CLUE. SuperCLUE encompasses three sub-tasks: actual users' queries and ratings derived from an LLM battle platform (CArena), open-ended questions with single and multiple-turn dialogues (OPEN), and closed-ended questions with the same stems as open-ended single-turn ones (CLOSE). Our study shows that accuracy on closed-ended questions is insufficient to reflect human preferences achieved on open-ended ones. At the same time, they can complement each other to predict actual user preferences. We also demonstrate that GPT-4 is a reliable judge to automatically evaluate human preferences on open-ended questions in a Chinese context. Our benchmark will be released at https://www.CLUEbenchmarks.com